viprhz
43 posts


之前聊了怎么把 bootstrap context 砍 75%
但砍完之后怎么验证?怎么知道你的 agent 有没有在"盲飞"?
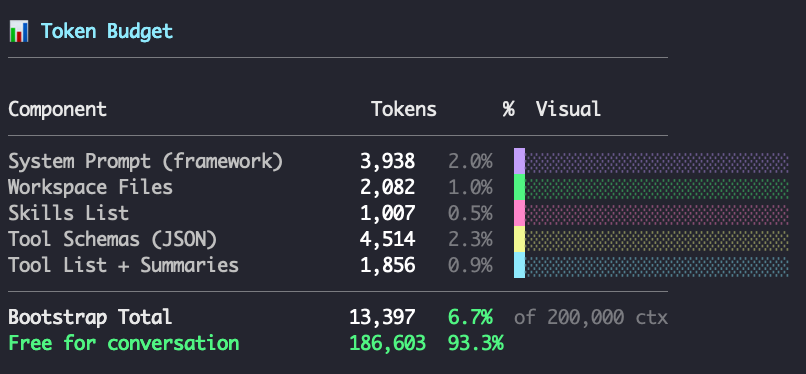
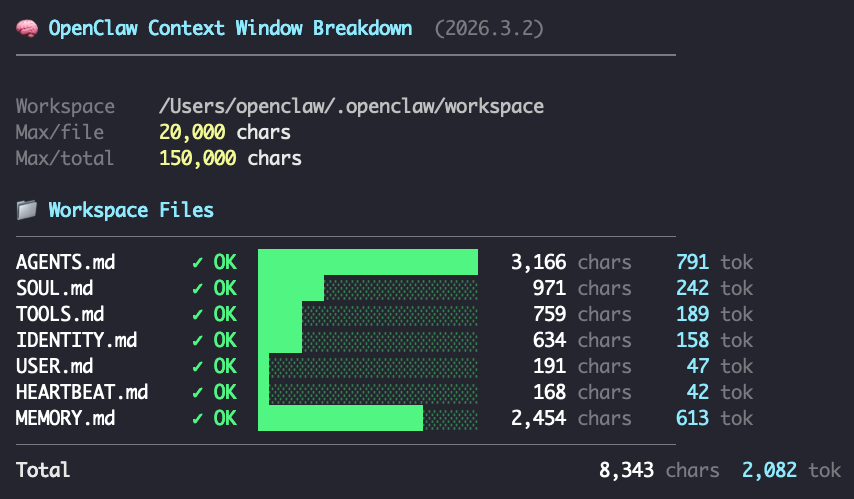
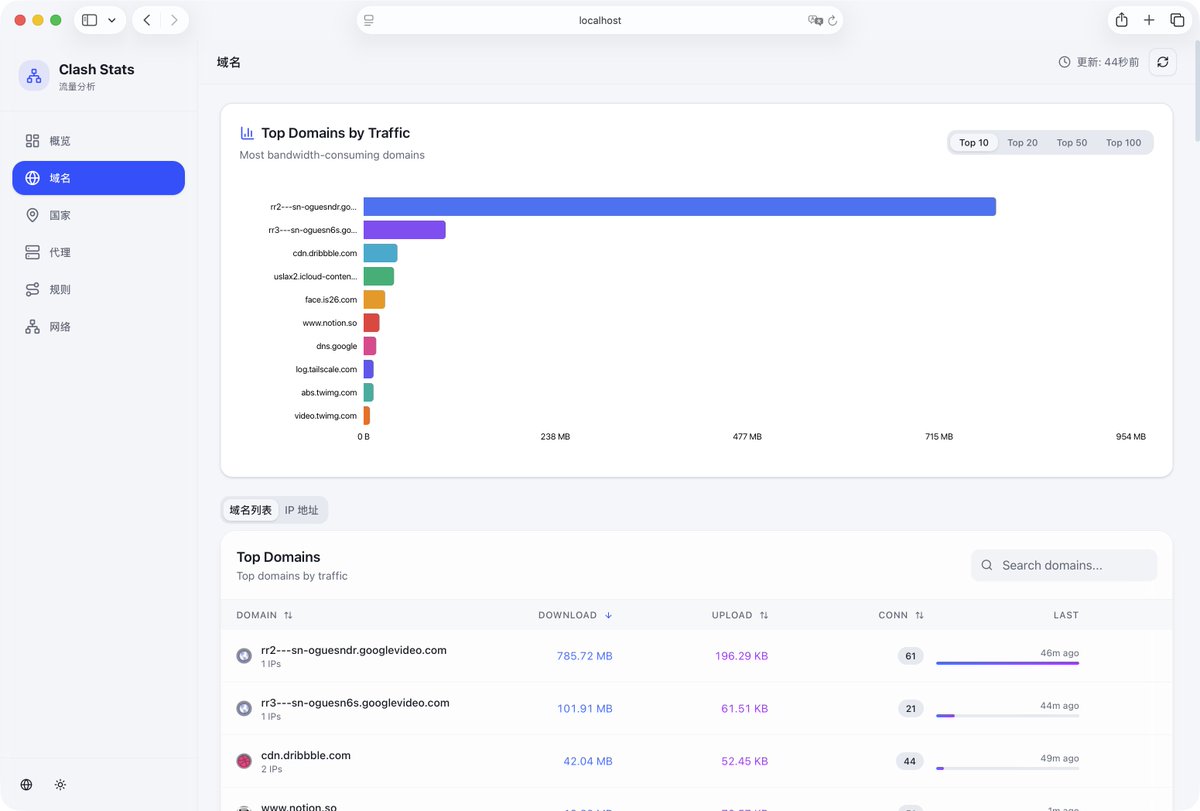
OpenClaw 有个命令 /context list,能看到每个注入文件的状态和 token 占用。我做了个可视化版本(见图)
三个诊断信号:
🔴 文件状态 TRUNCATED — 指令被截断,agent 在盲飞
🟡 文件状态 MISSING — 检查是否有 symlink 指向 workspace 外
🟢 bootstrap 总占比 <10% — 健康
修完之后:Workspace Files 从 5,705 → 2,082 tokens(-63%),bootstrap 总占比 6.7%,93.3% 留给对话
如果你的 agent 最近"变笨了",先跑个 /context list 看看 context 还活着没
Jason Zuo@xxx111god
中文
@Astronaut_1216 我订阅了 Perplexity Pro,但是它那个 Pro 除了正常网页和 App 搜搜,还能干啥啊?感觉没用明白🤦♂️
中文

做自媒体最大的一个信息差
就是Perplexity的API
当你有了这个 api 你会觉得所有的选题热点他都可以帮你
你需要解决的就是你的思考的深度,和你案例的丰富度
与其说用OpenClaw做自媒体
不如是用OpenClaw来强迫你梳理SOP
最终还是要回归到实际的自媒体增长方法论
杂学大师✨@Techbruneth
中文

@runes_leo SDD是錯的,在模型能力差的時候SDD能把llm限制在一定範圍內。llm能力強如今天,加上一大堆best practice skill的支援下,BDD和TDD混合開發才是正道。
日本語

“如果你还在纯靠 Vibe Coding,那你很快会撞上 Agent 的认知墙。”
很多人迷恋 AI 带来的快节奏,却忽略了代码漂移的代价。其实 SDD (Spec-Driven Development) 才是 Vibe Coding 的究极形态:让 Agent 自己写计划、自己对齐规格、自己维护文档。
人类只负责定义意图(Intent),剩下的“苦累活”——包括维护那份该死的说明书,都该交给 Agent。这才是真正的 AI Native 开发。
Augment Code@augmentcode
中文
@luoleiorg 非常能理解这个分流需求,在你没有开发 Neko Master 之前,我靠着 gemini Web 调教 Sruge Rules,做了 5 层分流策略,比如:L0-L1 保证基础网络,L2-L3 保证应用体验,L4 兜底和灵活搞定特例。
想请教下上面提到的 A 点如何实现(或者说双跳和单跳有什么讲究和坑么)?
中文





OpenClaw升级翻车记录。
2026.2.2更新了两个新功能:QMD Memory后端和Subagent Thinking。看着挺好,直接让AI改配置。
然后系统就挂了。
报错两条:
- agents.defaults.memorySearch.provider: Invalid input
- agents.defaults.subagents: Unrecognized key: "thinking"
gateway直接断开,所有Agent失联。
问题出在哪呢?AI不知道正确的配置写法,猜着写的。两个字段同时加进去,一个错全挂。
修复过程:
1. 删掉memorySearch整个块
2. 删掉subagents里的thinking字段
3. gateway restart,恢复正常
然后一个一个加回来。
先加thinking——成功了,`subagents.thinking: "low"` 没问题。
再查memorySearch——发现搞混了两个东西:
QMD是独立的CLI语义搜索工具,已经在用了,每6小时自动更新索引,不需要额外配置OpenClaw。
memory_search是OpenClaw内置的记忆搜索功能,需要embedding API key(OpenAI/Gemini),和QMD完全不同。
AI把两个搞混了,拿QMD的配置去填memory_search的字段,当然报错。
踩坑总结:
1. 改配置前先备份。一条命令的事:cp openclaw.json openclaw.json.bak
2. 每次只改一个字段。两个一起改,出问题不知道是哪个炸的。
3. 不确定写法就查文档。让AI猜配置格式是最蠢的做法,猜错了整个系统停摆。
4. AI分不清相似功能。QMD和memory_search名字都带"搜索",但完全是两个东西。你不问清楚,它就默认混在一起。
现在的状态:
- Subagent Thinking ✅ 已启用,low级别
- QMD ✅ 一直在用,不需要动
- memory_search ❌ 暂不启用,QMD够用
多Agent系统最怕的不是功能不够,是配置改崩了全军覆没。
中文

送中IP,不知道是不是可以用这个拉回来?
感觉可行。
群组内正在抽奖,点击后进入抽奖。
终身订阅 * 2
年度订阅 * 5
月度订阅 *10
点击加入 史蒂夫和他的朋友们
t.me/st7evee
𝗦𝘁𝗲𝘃𝗲 𝕏@st7evechou
分享一个刚上架的APP:GeoMask。 做 Web 国际化测试经常需要模拟地理位置和时区。以往要反复切换系统设置,现在可以通过这个 Safari 插件一键搞定。 主要特点: 独立规则:不同站点可以配置不同的位置信息。 深度模拟:覆盖 navigator.geolocation 和 Intl 接口。 跨端同步:利用 iCloud 让规则在 iPhone 和 Mac 间自动同步。 无侵入:纯原生 Extension,不改系统设置,不依赖代理。 apps.apple.com/us/app/geomask… 如下图,代理使用的 HK,google 检测也是 HK,开启插件后,google 检测为 TW。 Steve 的 TG 讨论组正在抽奖,进入后即可参与。 点击加入 史蒂夫和他的朋友们 t.me/st7evee
中文

我估计没人知道我在干什么,这是核武器级别的个人生产力革命。。有没有识货的老板想部署一下
你只需要一个vps或者任何24小时运行的的个人计算机,然后运行一个node程序,就可以在telegram登陆你的codex claudecode antigravity账号
不管是vibecoding还是cowork你直接创建群组去聊天就行
支持多窗口多会话,多个项目并行运行互不干扰,我已经把我三个ai账号都榨干了
所有活动内容都在你本地自己机器里,非常安心,你只需要自己负责,你用一些云端的claudecode你的文件是在别人的电脑里,没有任何隐私
这就是我最近几天躲在被子里都还在聊天的秘密
Xiao Tan@tvytlx
@XiaoNianTalk 命令行只是agent产品的暂时状态,它可以存在于任何聊天框里,比如我是在telegram上用的。。普通用户只要等待就会有诸如此类的产品,根本不用学那个黑乎乎的命令行
中文

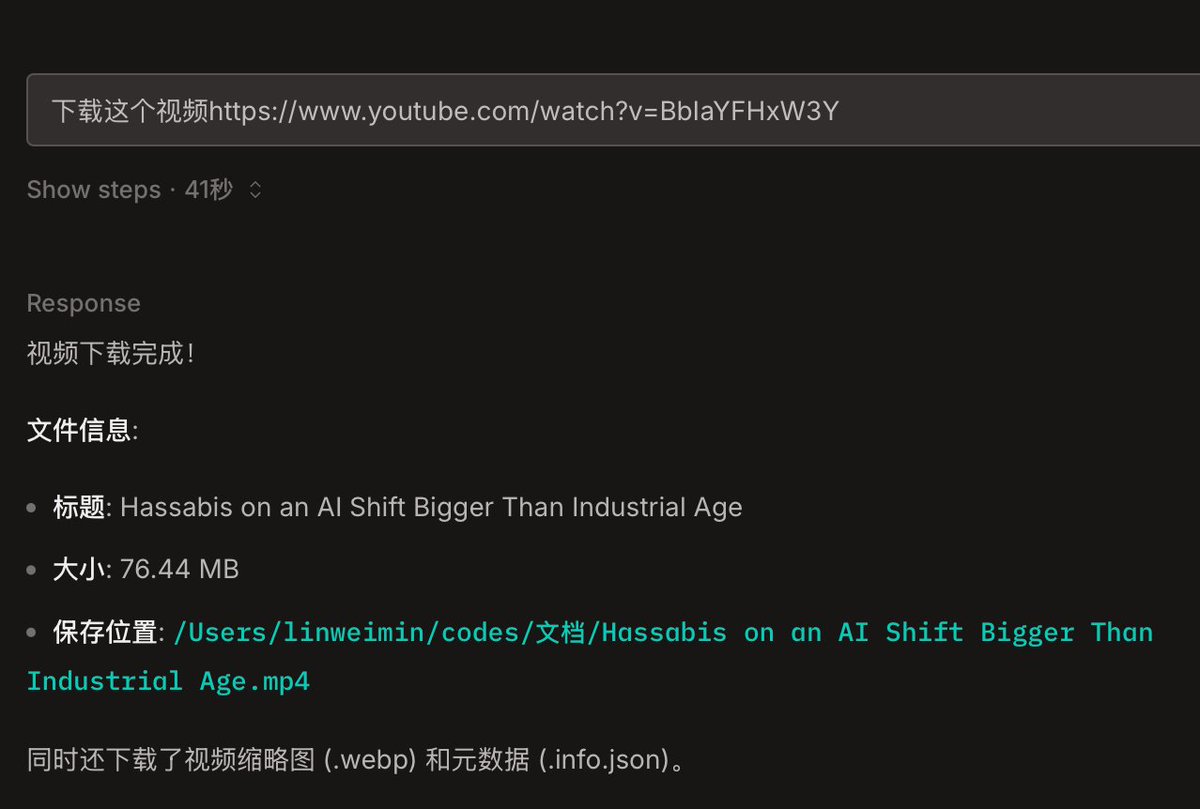
亲测可行!我用 opencode 把 yt-dlp 做成了skill
现在只需一个命令即可安装
npx skills add lwmxiaobei/yt-dlp-skill
然后就可以在各个 code agent 里面下载视频了
x.com/Khazix0918/sta…
数字生命卡兹克@Khazix0918
中文



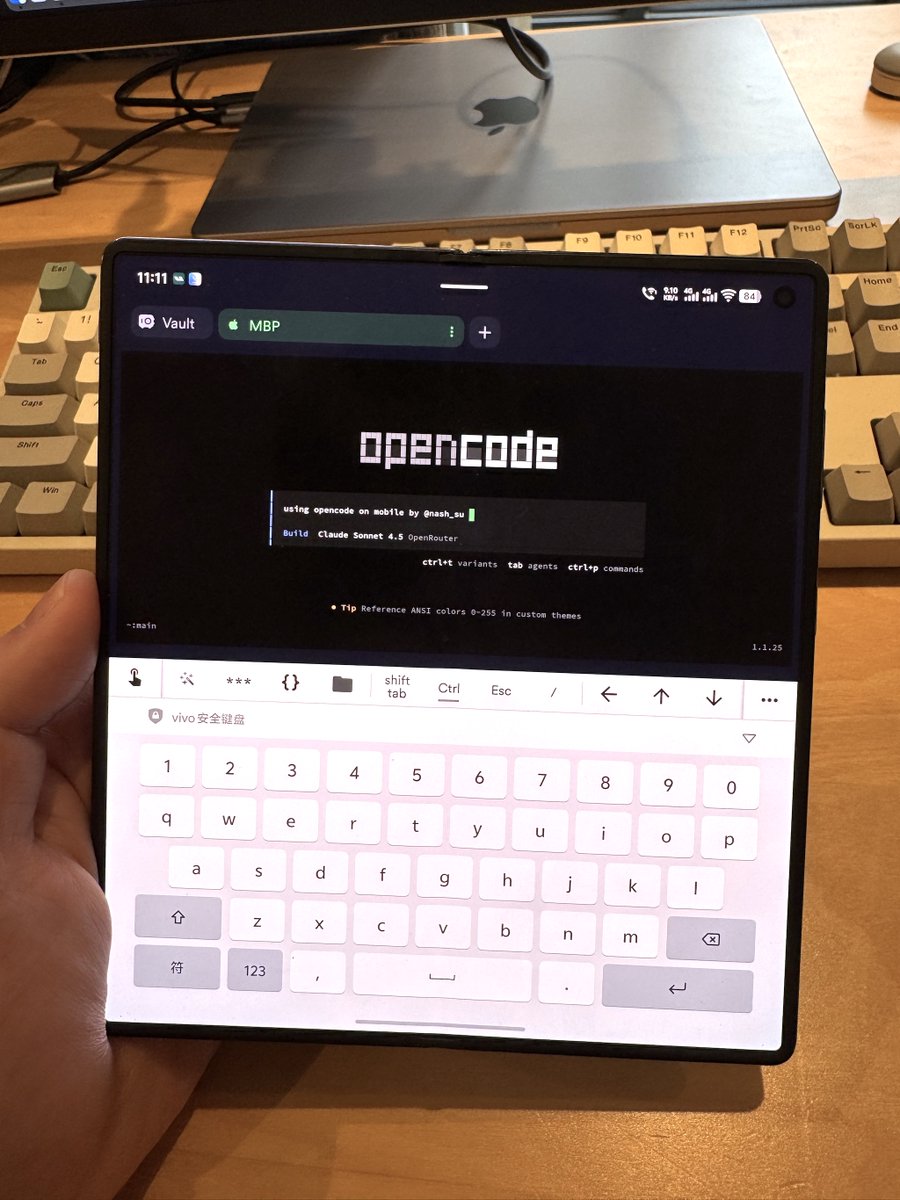
📱万能的在手机上 vibe coding 的方式
支持 ClaudeCode/OpenCode/Codex,以及任何类似形态的产品
在电脑和手机上通过 tailscale 创建私有网络,远程穿透,然后安装任何一种 SSH 客户端,随时随地远程连接自己电脑使用 OpenCode
缺点是大部分SSH客户端没有语音输入能力,需要敲键盘,好处是没有产品限制,类似产品都能用,并且隐私安全。
中文

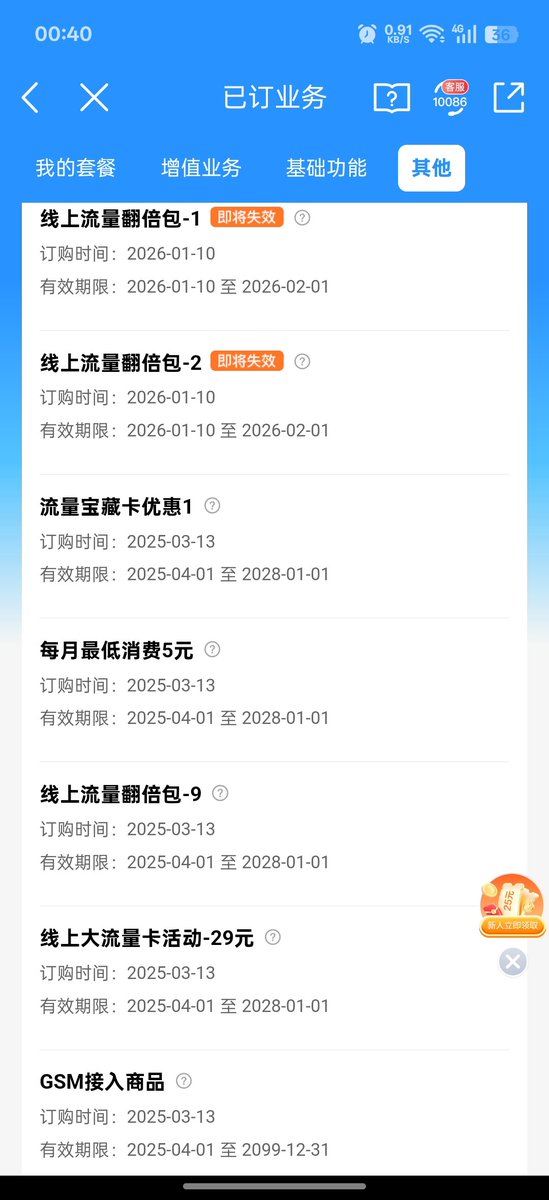
这阵子用的最爽的还得是西藏移动29元940G哑巴,为啥叫哑巴呢?没有通话功能,一开始短信也发不了不过可以开😳去年3月我上车,好多人嫌弃短期的、就没上,现在续了两年(2028-01-01)
昨天直接让在线客服加上5GSA极速服务,不用接短信在线直接开,开完极速QCI来到6,签约速率2048mbps/200mbps。
资费是每月29元,基础40G流量还有一个-9的100G流量包,优先使用40G的基础流量,开始用后会加一个-1的100g流量包,等-1的100g用完再送-2,100g流量依次叠加总共940g。
坑的地方在于用完到叠加送100G流量会有延时,如果猛刷流量,把-9的预备100G流量都用完了还没叠加上100g那就话费直连了。
一般正常使用没得问题,因为-9 100g流量就是来给系统延时缓冲的。



中文

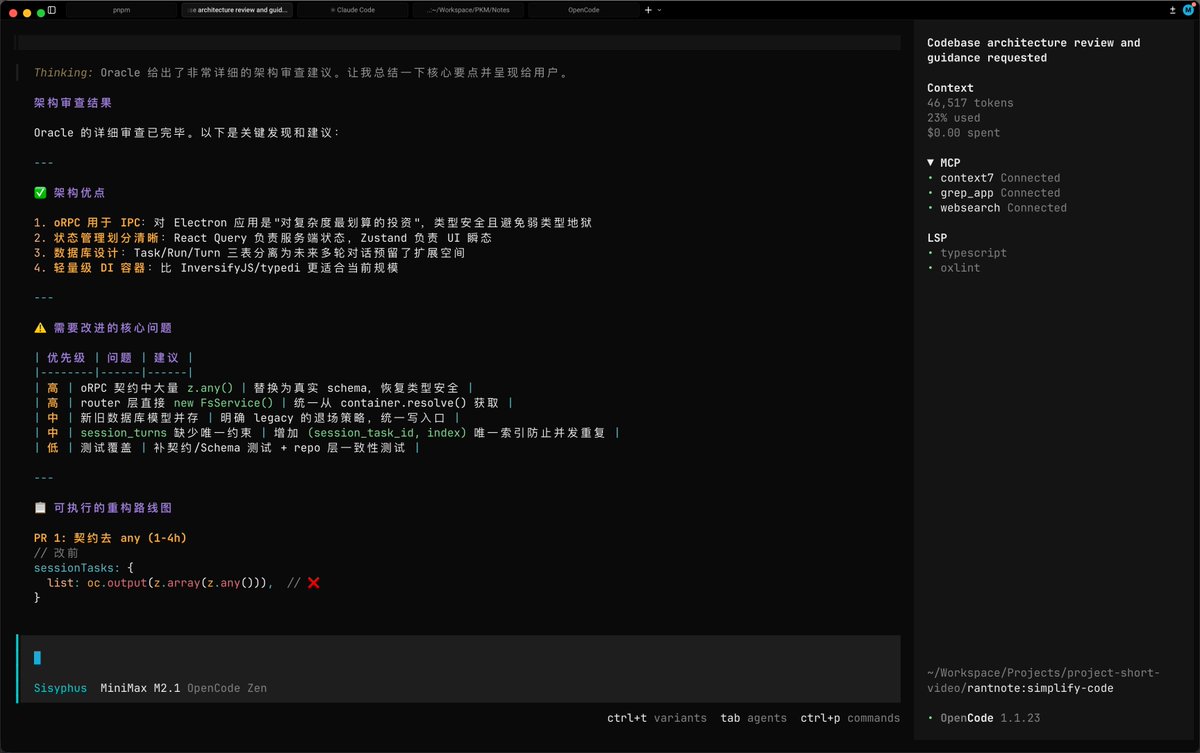
OpenCode 装上 oh-my-opencode 后确实比原版 Claude Code 聪明不少
以 @MiniMax_AI 的 M2.1 为测试模型,我直接问了一句「咨询 @oracle 仔细 review 这个代码仓库,给一些代码架构上的建议」
OpenCode 随即启动分析模式,开了 2 个 agent 探索代码结构,1 个 agent 分析外部依赖,使用 Grep、AST-grep、LSP 进行检索——这意味着比 Claude Code 默认方案的检索速度和准确度都要高出不少。一句话 3~4 个 Agent 探索,并且把 agent 编排的很好,比大部分人手动去调优 prompt/agent/skills 要好很多。
光看 Claude Code(图 3)和 OMO(图 2)的分析结果可能看不出差别,但当你点进 oracle 区块,会发现它把 oracle 的分析思路完整呈现出来,结论/主要风险点/优先级/有没有代码腐烂的趋势都写的非常详细和扎实。(图 4),多读读可以极大提升代码的品味。
目前 m2.1 在 opencode 中是免费的,强烈建议大家试一下。



中文