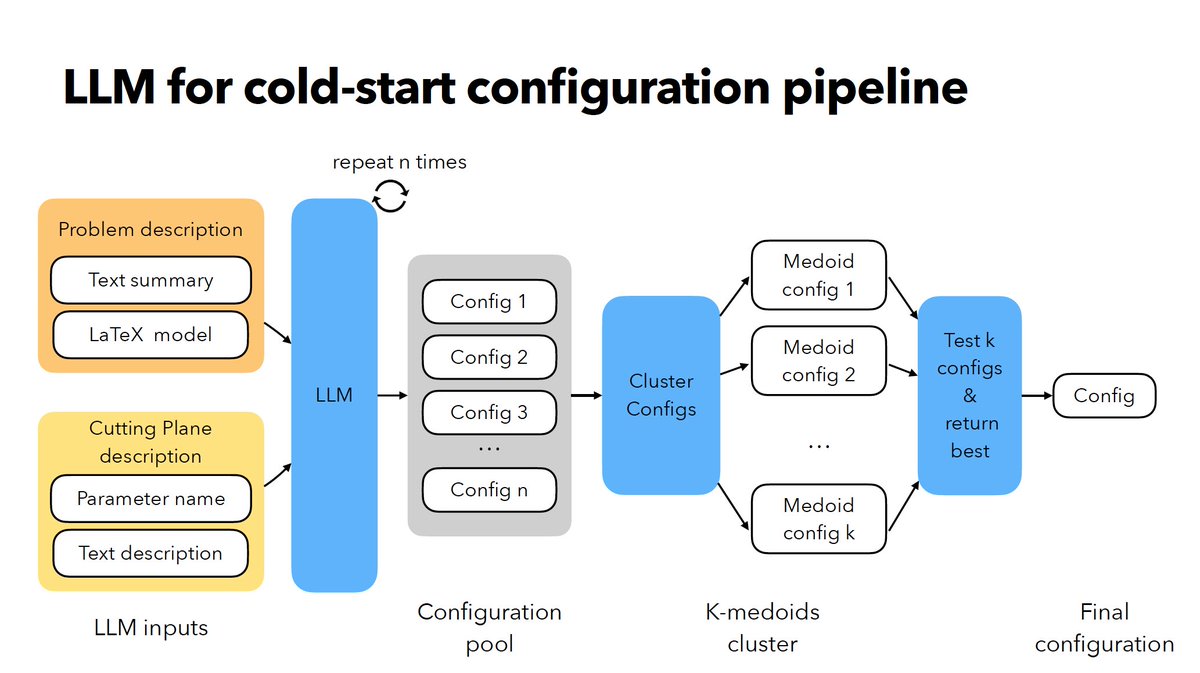
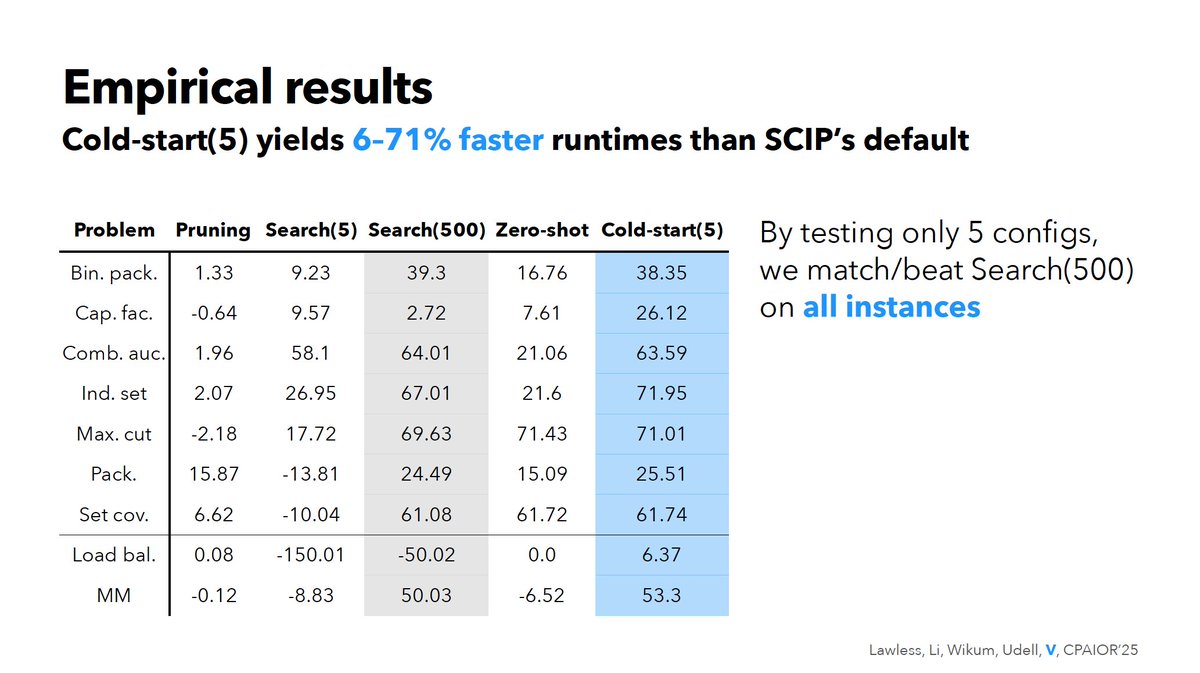
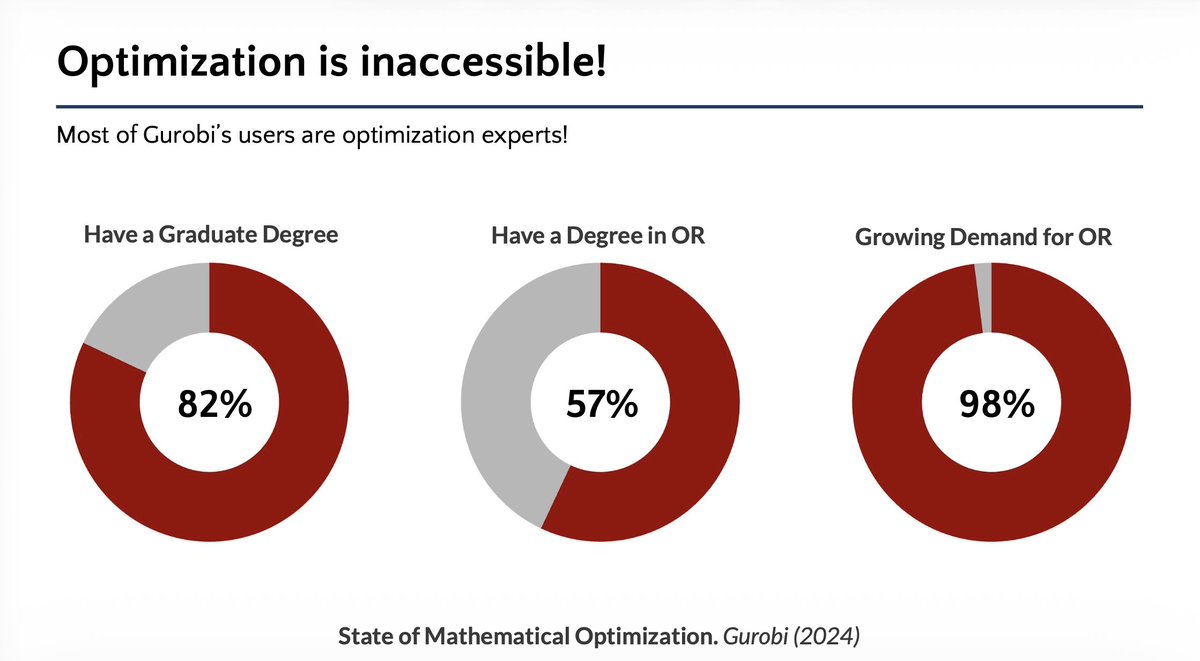
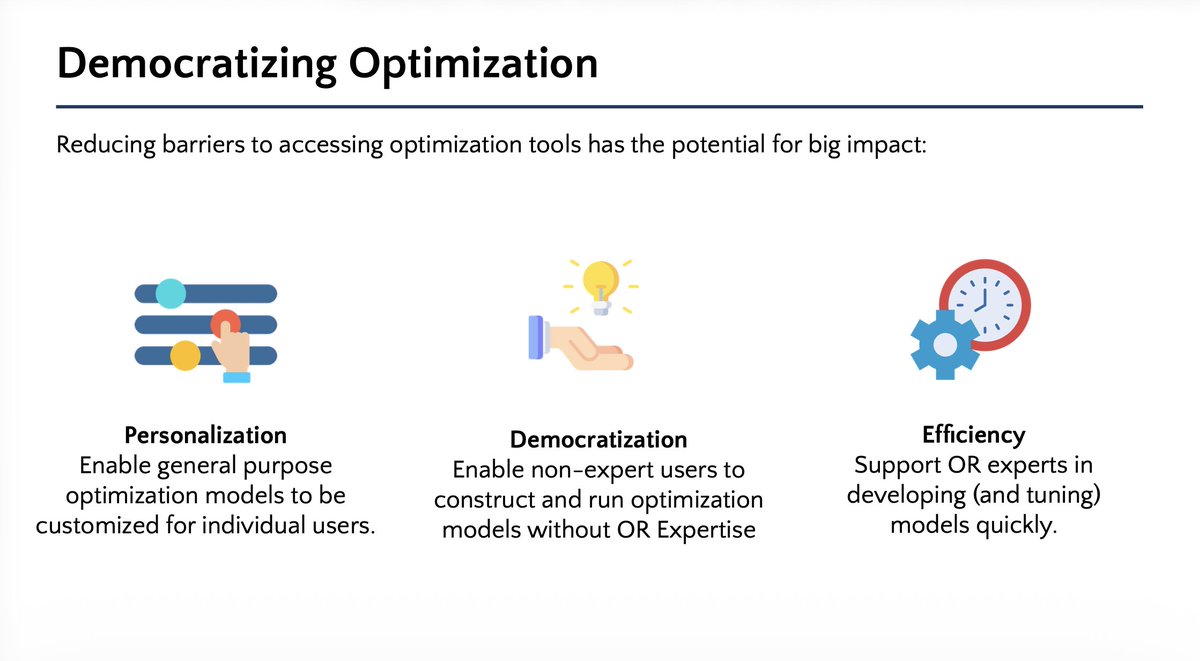
Congrats to my awesome postdoc @xizhi_tan, as well as @GolowichNoah and Yifan!
ACM SIGecom@AcmSIGecom
🏅 Runners-up: - @xizhi_tan (Drexel), advised by Vasilis Gkatzelis, for: "Learning-augmented mechanism design" - Yifan Wu (Northwestern), advised by @jasondhartline, for: "Trustworthy AI: Foundations from Proper Scoring Rules"
English