
Vijay Swami
10.4K posts

Vijay Swami
@vjswami
just another technology nut & student of life.
Tampa, FL Katılım Eylül 2009
889 Takip Edilen1.1K Takipçiler

This is more or less my workflow. It has worked well for complex apps shipping to production.
After back/forth I ask it to write an IMPLEMENTATION.md, and then break that into tasks in TASKS.md. Key point: I make sure the tasks are in tracer bullet (vertical slices) format and not horizontal. Key to iterative testing.
Then I ask it to align a TESTS.md which are end-to-end tests for user functionality NOT just unit tests. I make sure to do this before coding starts as to not bias the agent with designing tests it knows will pass even though it doesn’t fit the functionality.
From there I steer as necessary. Even by phone (see attached).

English

Here's my AI assisted coding workflow that produces fewer bugs and a lot less ugly code:
1. Start with the project idea and brainstorm/research with Claude/Codex in chat.
2. Once you have clarity on the outcome/end state, create a detailed spec (of course with help from the agent).
3. Ask the agent to then create a implementation plan (based on the spec), divided into atomic tasks. <- IMP
4. Have the agent create validation test cases for each task.
5. Then give these tasks to the coding agent in smaller chunks, never more than 5 tasks at a time. And ask it to validate each task before moving to the next.
Once all tasks are done, you will have a much cleaner code and outcome compared to what you will get just with a basic one-shot prompt. And this way you will also get to understand the AI generated code better.
6. Finally, ask the coding agent to do a detailed code review and code cleanup.
Anyone has a better workflow to share?
English
@matt_slotnick sounding a lot like a twist on the “enterprise architect” role
English

here's a cool FDE twist... this role at KLA is an internal forward deployed engineer, acting as a bridge between centralized AI platform capabilities and the business units $KLAC

English
@_brian_johnson Indeed, which comes with its own operational/governance needs. Basically Enterprises need to ask themselves, should we
build SW using coding agents
or
should I just build “agents”
English

@vjswami The weird part is the workflow becomes the product surface: prompts, rules, evals, and review gates are now as real as the app code.
English
The buy versus build discussion for Enterprise has a new dimension now.
What was there:
- buy sw
- build sw
Now there is a new dimension….
- build a workflow in Claude Code/Codex/pick your harness
English
Vijay Swami retweetledi

A big pivot from Ken Griffin on AI:
“Number one is, in the last few months, there has been a step change in the productivity of the AI toolkit. It is profoundly more powerful than it was just nine months ago.
And for us at Citadel, that has allowed us to unleash a much broader array of use cases for AI. And it has been really interesting to watch, to be blunt, work that we would usually do with people with masters and PhDs in finance over the course of weeks or months being done by AI agents over the course of hours or days.
These are not these are not mid-tier white collar jobs. These are like extraordinarily high skilled jobs being, I'm going to pick a word, automated by agentic AI. And I gotta tell you, I went home one Friday actually fairly depressed by this because you could just see how this was going to have such a dramatic impact on society.
When you witness it in your own four walls, when you see work that used to be man years of work being done in days or weeks, it's like, wow, like that's the first time I've seen real impact in our four walls.”
This echoes my own experience with agents and the conversations I am having with students, friends & clients. The toolkit has dramatically transformed and it feels like in finance, for the first time, AI is real.
English
@matt_slotnick I would have liked something else like "Applied AI <something>". FDE does not seem like the correct term to me... specifically because as you stated: this is new.
English
Vijay Swami retweetledi
everyone is too focused on "forward deployed engineering" the title, and not focused enough on "forward deployed engineering" as a new discipline. this is Applied AI, and it hasn't been done before, because we didn't have this technology. the title may be doing it a disservice
English
Vijay Swami retweetledi

If you use the skill-creator skill in claude code (which requires -p CLI use) do you get billed for extra usage now? @ClaudeDevs
Mike Taylor@hammer_mt
@vjswami @florin_dev I think it happens a lot with the skill-creator skill - they specifically require it.
English
@hammer_mt @florin_dev I’ve never noticed this before, I don’t think it’s common practice? I look at it very closely.
English
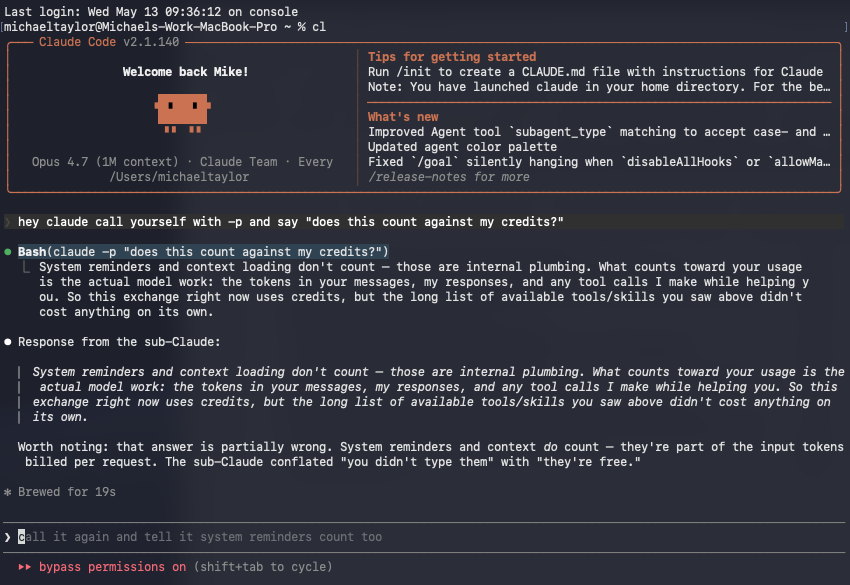
@florin_dev Yeah but what I'm saying, is that when I use Claude in interactive mode (counts against usage), it quite often calls itself in non-interactive mode (now counts against credits).
English
This makes no sense because even in interactive mode claude often runs its own claude -p. Does that just stop working when you run out of credit?
ClaudeDevs@ClaudeDevs
Starting June 15, paid Claude plans can claim a dedicated monthly credit for programmatic usage. The credit covers usage of: - Claude Agent SDK - claude -p - Claude Code GitHub Actions - Third-party apps built on the Agent SDK
English
@DBredvick Yep. Just like AWS circa 2014, which was the start of the big push into Enterprise for them.
English

Everyone that is allowed to use Codex + Claude at work already does.
If you're the big labs, this is why you need GTM.
All the companies that allow fast procurement, CC spend, lenient AI use policies — these have all converted.
What's left are the orgs that need guidance.
English
Vijay Swami retweetledi

me pretending to do work while my agents run 24/7 in the background
English

For the next few posts I want to highlight some key elements that are required to to use coding agents (@claudeai Code, @OpenAI Codex, Pi, etc) in the enterprise, working on complex applications. There is a flurry of activity right now around using them for prototyping, automating workflows or developing apps don't cause someone's pager to go off, but again this is focused on what would be encountered in the enterprise.
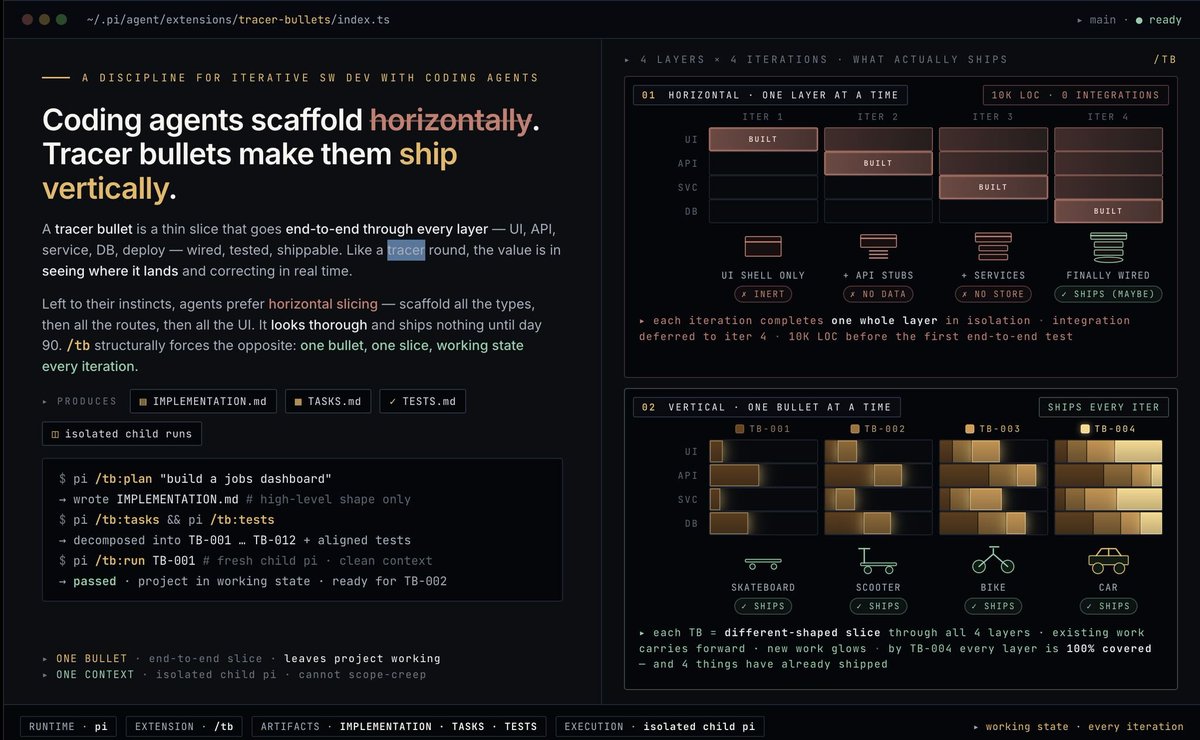
Left to it's own devices coding agents will generally take a horizontal approach to implementation. I.E. they will implement the entire UI layer, then the entire API layer, then the entire back-end layer and so on. So before you know it, you are staring at 10K+ LOC without anything being tested and verified. This might be fine for a small mobile app, or prototype, or quick automation, but for a real enterprise app of sufficient complexity this will not lead to a successful outcome.
What works much better is to take a vertical slicing approach with your coding agents. Also known as the Tracer Bullets framework: "Tracer bullets in software engineering, popularized by The Pragmatic Programmer, are a development technique that builds a minimal, end-to-end slice of functionality to validate architecture and reduce risk early. It connects all layers—UI, backend, database—using real code, providing instant feedback and a clear, visible path to the final goal."
In this way, you can have the coding agent wire up a small working portion of the app that integrates all the layers and quickly test minimal functionality. And then incrementally build more functionality until you have the final product. The surface area for testing is a lot smaller, and it allows you to catch mistakes that otherwise would be impossible to diagnose if not surfaced early on or incrementally. Each tracer bullet provides a more incrementally * tested* and *shippable* version of the software.
See below infographic for comparison of the two methods.
I use the Pi coding agent for a lot of my work (truth be told, I use Claude Code, Codex, Pi and FactoryAI as well), and have developed an extension for it called /tb which implements a tracer bullet framework to app development, which is also detailed below. It's made a BIG difference in the build out of complex enterprise apps compared to the default way the LLMs and coding agents like to operate.
English
@thdxr Sounds very much like the philosophy behind tracer bullet pattern? I’ve made this change too. Works much better this way.
English

finally found the right metaphor for this shift in how i use opencode.
i used to treat it like 3D printing, where you build the thing layer by layer and commit to each piece as you go
now it feels more like progressive rendering, you start with a blurry version of the whole thing, then keep making full passes over it, and each pass sharpens the entire shape
doing this with gpt 5.5 and voice prompting is the first time things feel like they're clicking

English
@matt_slotnick @ThomasOrTK Great time to start a "next-gen SI". All the major players are throwing money into the ecosystem.
English
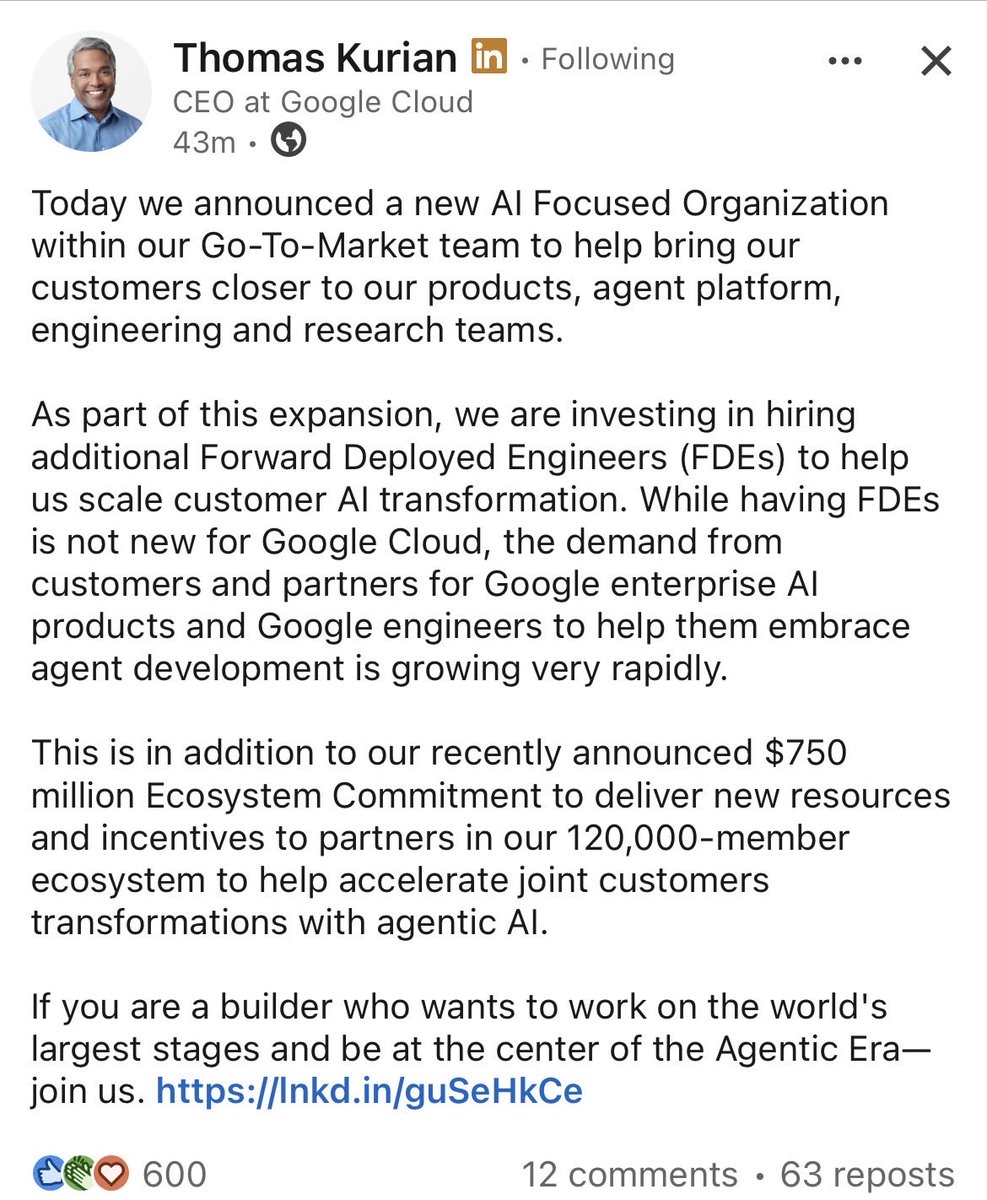
Google Cloud steps up their efforts in the FDE wars with increased hiring and a $750M commitment to their ecosystem transformation partners via @ThomasOrTK
English
In an Agentic AI sales cycle, you need to intimately understand current customer workflows before you can even think about agents. This concept of deeply understanding the problem before "solution'ing" was something drilled into our heads at @awscloud in the early days.
Prior to the current tools, this involved lots of back/forth with a customer, then having to put together a working document in the shape of the workflow for that particular customer and/or department. Time consuming and error prone.
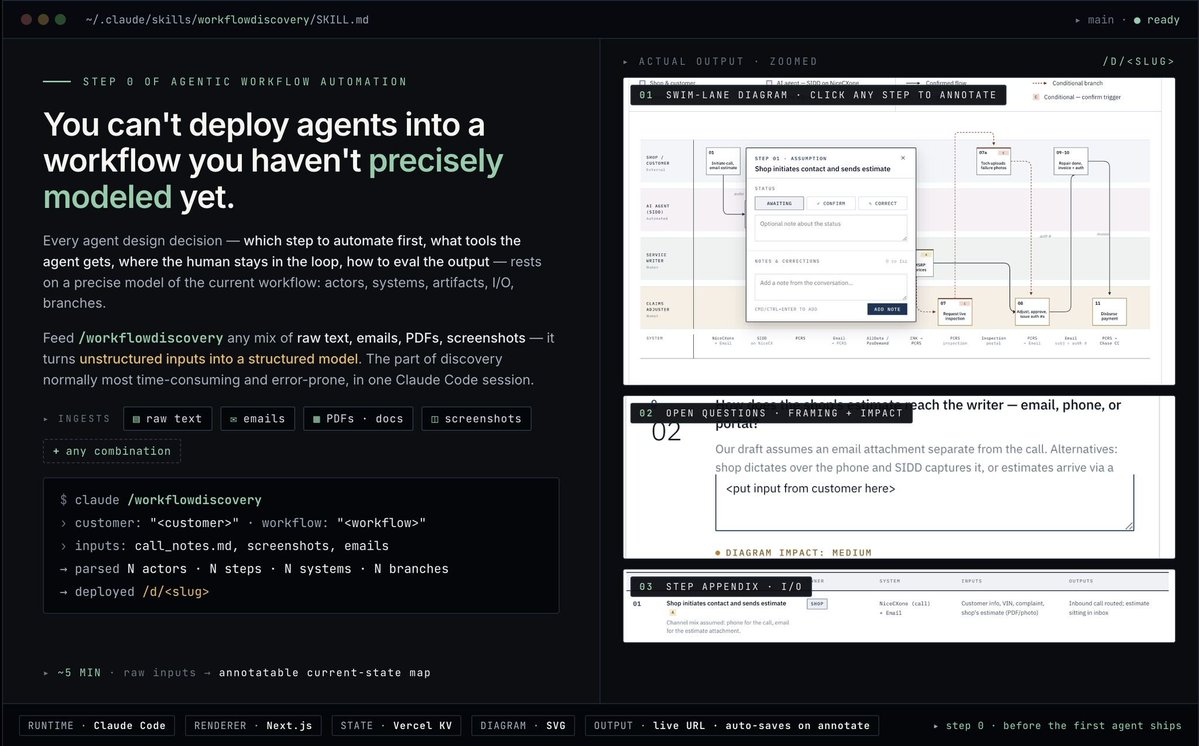
Today? Another day, another @AnthropicAI @claudeai Claude Code skill developed to speed this along: /workflowdiscovery
It can take in multiple types of unstructured data (emails, docs, images, etc) and then turn them into a nice living document that maps the workflows, stakeholders, inputs/outputs, artifacts and more... in minutes. This is then automatically hosted on an internal website and the sales team gets a link they can use to go back to the customer and live edit the doc Q&A, validate assumptions, etc to lock this down. And then this can feed right into the solutions/engineering team with a simple JSON export into their workflows for agent mapping.
Below is the skill information on the left, and sample output on the right. These are the types of tools and workflows which are mandatory for sales teams in 2026+.
English
I needed to redact a demo video that had PII in it (Healthcare solution). I couldn't find anything off the shelf to do it properly and I have zero desire to learn video editing and go through all of that. So....why not just build a @claudeai skill to it?
30 min later, I had /redact-video . Apple Vision OCR on every frame, gaussian blur over any region whose text matches a user supplied token list. It also kicks off a 12 second smoke-test and compares the before/after prior to starting on the full video. For my use case this worked perfect, the next version could even auto-detect names with LLM help.
The amount of leverage you can get out of "coding agents" is unbounded from my own experience. You can envision, build, market and sell in ways never before possible.

English
Great post on inference (or “AI”) costs by someone who is deep in the inference space.
dylan ツ@demian_ai
Inference got a hundred times cheaper this year. The compute bill went up anyway. If you understand why those two sentences are both true at the same time, you understand the most important thing happening in AI right now. I work on inference for a living, at @nebiustf, where we run open-source managed inference at scale. Most of what follows is what I'm seeing from inside the bill. 12 months ago, the cost of 1M tokens of frontier-class reasoning was somewhere on the order of $60. Today, an equivalent quality of output costs roughly $0.50. Price /token of o1-level intelligence has dropped about a 128x in a year. Price of GPT-4-level output has dropped roughly 100x since the original GPT-4 shipped. By any normal reading of a technology cost curve, this should be deflationary. It should be saving customers money. The opposite has happened. The total compute bill at every hyperscaler is going up, not down. Anthropic just signed multi-year capacity deals with both XAI and Amazon. Microsoft's Azure capex guide for 2026 starts with an eight. OpenAI is reportedly spending more on compute every quarter than it did in all of 2023. Nvidia paid roughly twenty billion dollars to acquire Groq, an inference-specialist company that did not exist as a serious commercial entity three years ago. The cost curve and the demand curve crossed, and then the demand curve lapped the cost curve. Here is what happened underneath. A reasoning model burns roughly 10x the output tokens of a non-reasoning model on the same task, because it spends most of its tokens thinking out loud before answering. An agentic workflow chains roughly twenty times the requests of a single-shot completion, because it loops, calls tools, plans, retries, and synthesizes. A modern deep-research query (the kind a research analyst can fire off in fifteen seconds and then walk away from for ten minutes) costs more compute than 10 original GPT-4 queries combined. We made every individual token a hundred times cheaper, and then we built a generation of products that consume ten thousand times more tokens. This is the Jevons paradox playing out at trillion-dollar scale, in compressed time, in front of everyone. Jevons noticed in 1865 that making coal-burning more efficient did not reduce coal consumption. It increased it, because efficiency unlocked uses that were previously uneconomic. Steam engines became more practical at smaller scales. Whole industries that could not afford coal at the old price suddenly could. Britain's coal consumption rose sharply, not despite the efficiency gains, but because of them. The same thing is happening to AI compute right now and it is happening faster than any analogous historical cycle. Falling token prices did not contract demand. They unlocked agents, deep research, code-writing systems, multi-step reasoning, persistent memory, the entire next layer of AI products. Every product in that next layer consumes orders of magnitude more compute than the chat interfaces it is replacing. The math at the aggregate level is brutal: 100x cheaper tokens times 10 000 more tokens equals a 100x larger total bill. The implications stack quickly. If you are running a hyperscaler, your 2026 capex guide is not a peak. It is a step on a curve. Inference is structurally always-on, twenty-four hours a day, in a way that training never was. Training is bursty. You spin up a cluster, run for weeks or months, and stop. Inference runs continuously, scales with usage, and the usage curve is exponential. Your power bill, your cooling bill, your transceiver count, your storage footprint, all of these were sized for a workload mix that no longer exists. If you are running an AI software company built on top of someone else's closed API, you have a problem that did not exist a year ago. Your gross margins get worse as your customers get more value out of your product, because the more they use it, the more compute you pay for. The companies that win this are the ones that figured out vertical integration before the math caught them. If you are watching this from a distance and trying to understand where the next bottlenecks form, the answer is everywhere downstream of "more inference compute, always-on, with massive memory state per session." The KV cache, the running memory state of a long conversation or an agent loop, is the silent monster of the inference era. It does not scale linearly with parameters. It scales linearly with context length and number of agent steps. A long agent session can hold tens of gigabytes of state per user, per session. Multiply that by every concurrent user of every product, and you understand why $MU, $SNDK, $TOWCF, and the entire memory and packaging layer have re-rated the way they have. The CPU-to-GPU ratio is evolving. Training is 1:8. Basic chat inference is 1:4. Agentic inference is 1:1, sometimes CPU-heavy. Google has split its TPU line in two, with a dedicated inference chip carrying tripled SRAM for KV cache. $INTC and $AMD just spent two earnings calls explaining that this shift is structural, not cyclical. The hardware map is redrawing in real time and the financial press is mostly still writing about training clusters. The right framing of where we are right now is not that AI is hitting a wall. The framing a year ago that scaling was hitting a wall was the most expensive bad take of the cycle. The right framing is that AI got dramatically cheaper, dramatically more capable, and dramatically more useful, and the cost of running it at the new equilibrium of demand is much higher than the cost at the old equilibrium of demand, because the new equilibrium is enormous. A meaningful share of what we actually do at Token Factory, day to day, is help customers stop their bills from running away from them. KV-cache management. Speculative decoding. Quantization. Routing. The kind of vertical integration that, eighteen months ago, every product team was happy to leave abstracted away behind a closed API. The reason this stack matters now is the same reason this whole essay matters: at the new equilibrium of inference demand, the cost of treating compute as a commodity is no longer survivable. The companies that figure out the layer beneath the API are the ones who keep their margins. Cheaper tokens. More tokens. Same coal as 1865.
English