Sabitlenmiş Tweet
VLM Run
149 posts


VLM Run
@vlmrun
Visual Intelligence for Enterprise.
Santa Clara, CA Katılım Ocak 2022
46 Takip Edilen334 Takipçiler
Manually parsing handwritten intake forms can be slow and prone to error, while VLM Run's HIPAA-ready API allows you to extract the same details in seconds. In this tutorial by @jeremyparkphd, learn how to use VLM Run to extract structured JSON from handwritten healthcare documents at scale.
Through this walkthrough, you will learn how to:
- Upload documents in the Requests tab and run them against your saved skills
- Enable confidence scores and grounding to see exactly where each field came from in the original document
- Edit incorrect extractions and provide feedback to improve extraction over time
- Run the same workflow programmatically via the VLM Run API as shown in Google Colab
English
Read our skills documentation here: docs.vlm.run/skills/introdu…
Chat: chat.vlm.run
English
Announcing Orion Skills! 🚀
Rather than rewriting prompts every time you want to define a specific task, you can now package all of that knowledge into a reusable skill.
Why skills?
- Reusable: Create a skill once, reference it from any endpoint (image, document, video, audio, agent)
- Versionable: Pin a specific skill version for reproducible results, or use "latest" to always get the newest revision
- Composable: Pass multiple skills in a single request, or combine them with custom schemas
Unlike purely text-based skills, we have reimagined what skills mean for visual agents and how to codify visual workflows into skills.
Try skills in chat today!
And check out this skills creation tutorial by @jeremyparkphd 👇
English
The AI agent skills conversation focuses mainly on text. But for many tasks, words fall short. We need visual skills: providing images and videos as context, not just text.
It's one thing to describe to a robot how to fold a t-shirt. It's another to show it a video.
At VLM Run, that's what we're building: visual agents that understand visual data and act on it.
English

Visual AI agents for identifying the most delicious blueberries?! 🫐
@jeremyparkphd recently shared his PhD research on computer vision for blueberries and new results using @vlmrun's visual agent Orion for segmentation, detection, and metadata tagging.
#agtech #visualanalytics #computervision #blueberry
English
What if visual AI agents could help give feedback on exercise?
@jeremyparkphd recently reviewed Orion visual AI agent for providing deadlift feedback. He raises the question: what if visual intelligence could be made accessible for applications in exercise, all through a chat interface?
Read the Substack blog here: jeremyparkphd.substack.com/p/visual-agent…
English
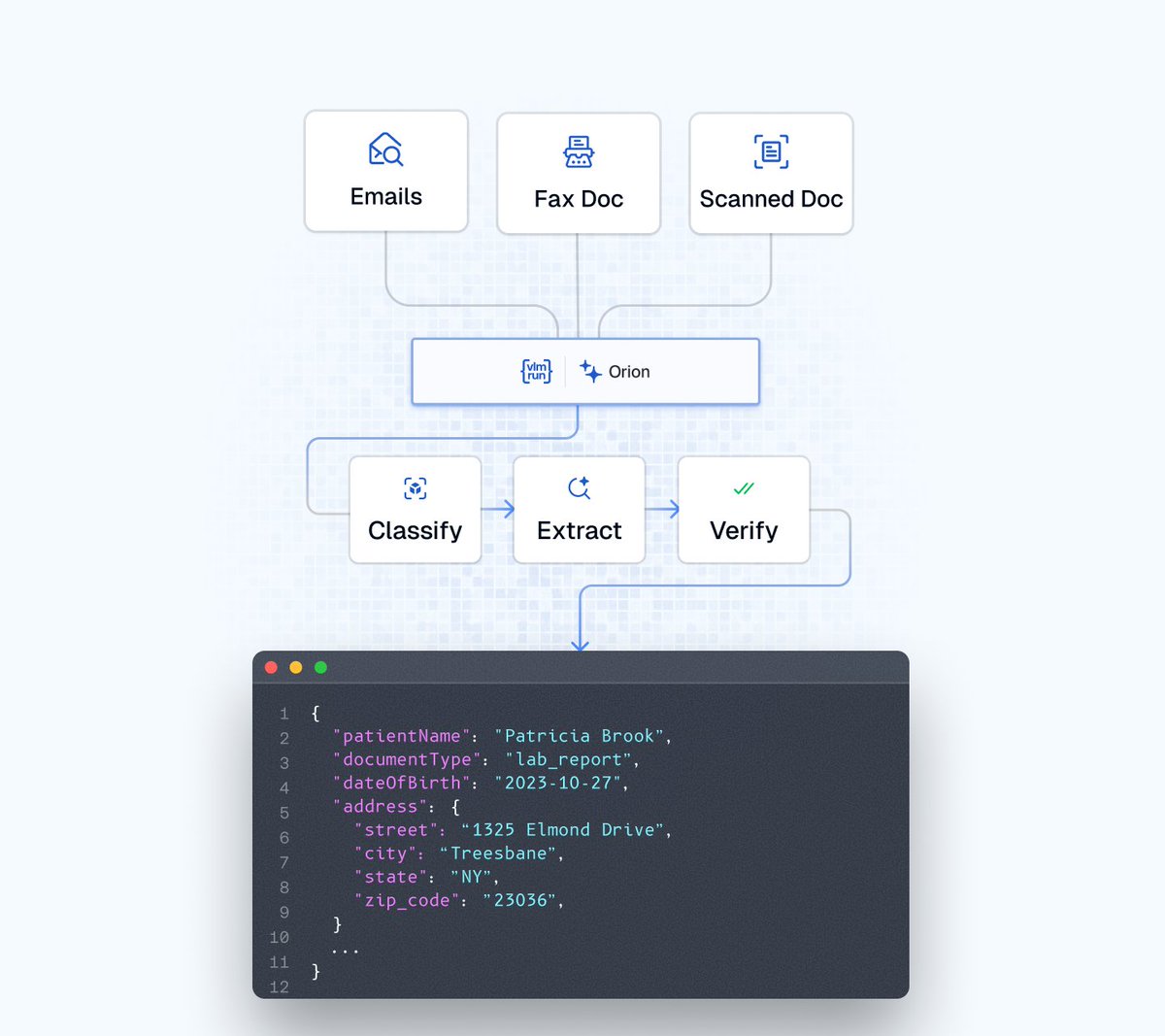

Healthcare documents come fragmented across PDFs, images, emails, and faxed scans. OCR fails because real-world documents require visual reasoning of layout and context – not just plain text extraction.
Scan.com processes high volumes of documents and images where both speed and accuracy matter. They needed automation that could handle the diversity and complexity of healthcare documents.
We built it together with Orion. In a single call:
• Classifies multi-page document bundles
• Extracts data from emails and attachments
• Understands checkboxes, handwriting, and layout
• Visually verifies for high confidence
The result: faster processing, reduced manual QA, reliable structured data.
Document automation isn't a text problem. It's a visual reasoning problem.
Read more:
vlm.run/blog/how-scan.…

English
We're hiring our first infra engineer (senior/staff) at @vlmrun!
We're processing tens of millions of VLM requests per month and scaling fast; we're looking for a founding Infrastructure Engineer to serve and operationalize our GPU workloads (custom runtimes on @vllm_project / transformers, orchestrated with @raydistributed / @modal).
The work is technically challenging, the learning curve is steep (in the best way), and you'll be joining a stellar ML team building the go-to visual intelligence platform for enterprises. In-person ONLY.
Tag someone who'd crush this 👇
English
@sanjaykrishna @emollick @emollick Check out our whitepaper on the first visual agent that sees, reasons and acts on images/videos: storage.googleapis.com/vlm-data-publi…
English


The ability of AI to understand video/images seems to be largely underexplored and underexploited. There are a lot of economically valuable applications to having an AI watch the world in real time, even with errors & limitations, and I have seen few products or papers on it.
English
Check out how you can generate your own poster here: chat.vlm.run/c/7b43cda3-37b…
English

🏈 Super Bowl hits different when it's less than a mile from your office.
We couldn’t help but generate this 4K poster with chat.vlm.run combining two star quarterbacks (Sam Darnorld and @DrakeMaye2) into a single face-off. You’ll likely see it while walking to the stadium.
Wishing both teams the best of luck tonight.
#SuperBowl #VLMRun #SeattleSeahawks #NewEnglandPatriots #SBLX @vlmrun

English

@GoogleAI We’ve been doing this for a while: docs.vlm.run/agents/introdu…
English

Introducing Agentic Vision — a new frontier AI capability in Gemini 3 Flash that converts image understanding from a static act into an agentic process.
By combining visual reasoning with code execution, one of the first tools supported by Agentic Vision, the model grounds answers in visual evidence and delivers a consistent 5-10% quality boost across most vision benchmarks. Here’s how the agentic ‘Think, Act, Observe’ loop works:
— Think: The model analyzes an image query then architects a multi-step plan
— Act: The model then generates and executes Python code to actively manipulate or analyze images
— Observe: The transformed image is appended to the model's context window, allowing it to inspect the new data before generating a final response to the initial image query
Learn more about Agentic Vision and how to access it in our blog ⬇️
blog.google/innovation-and…
English