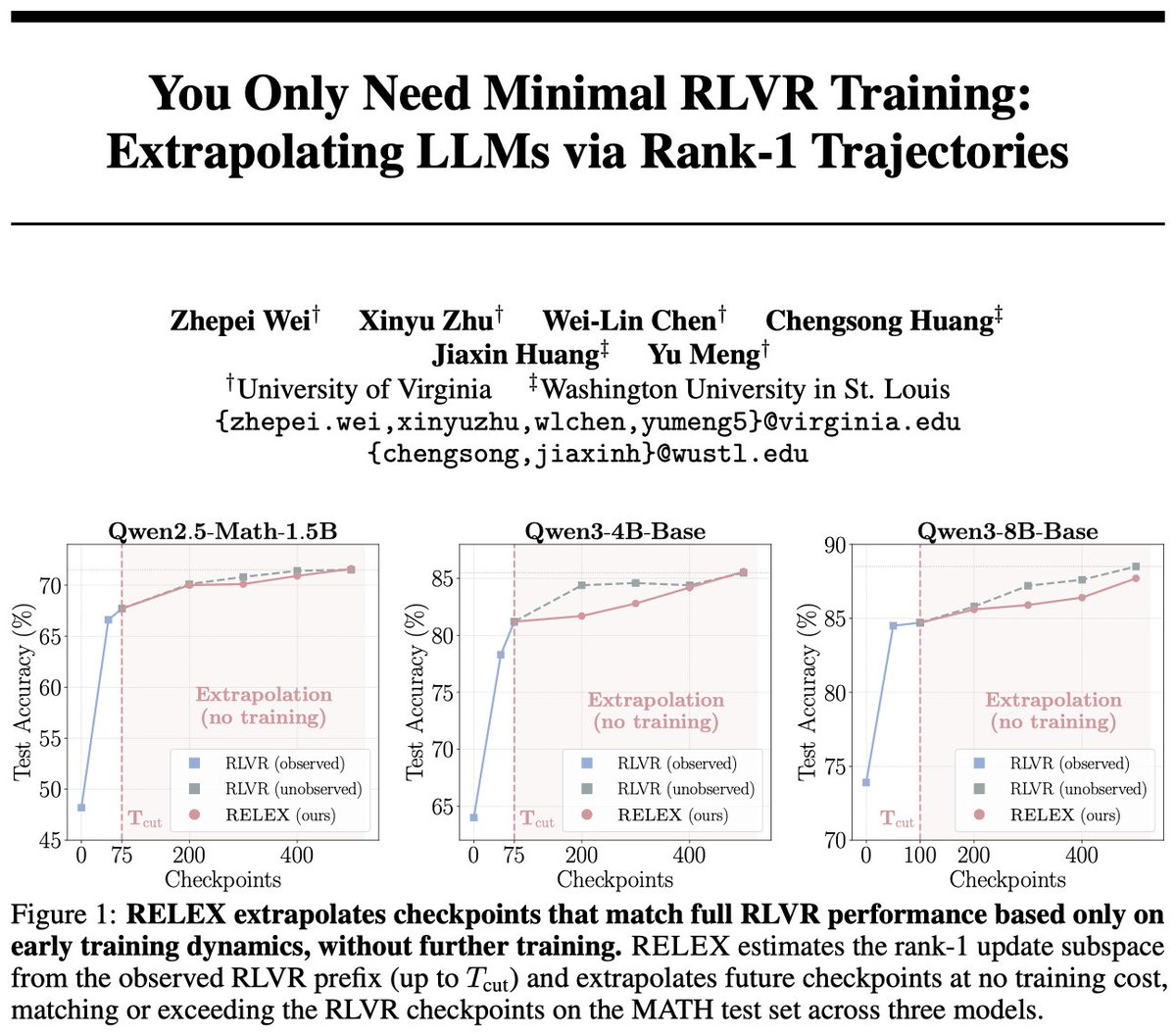
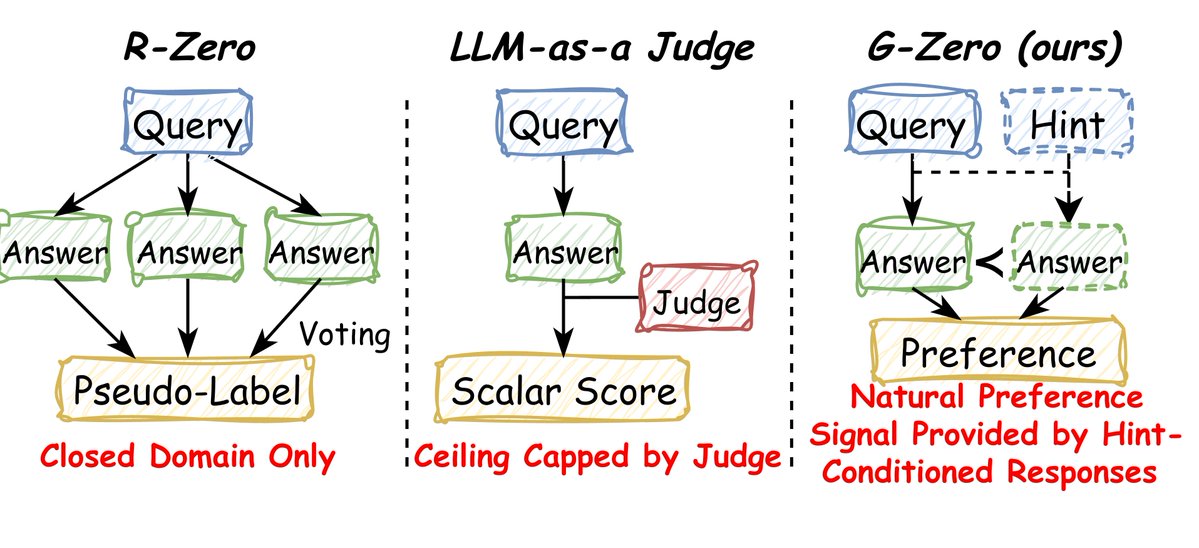
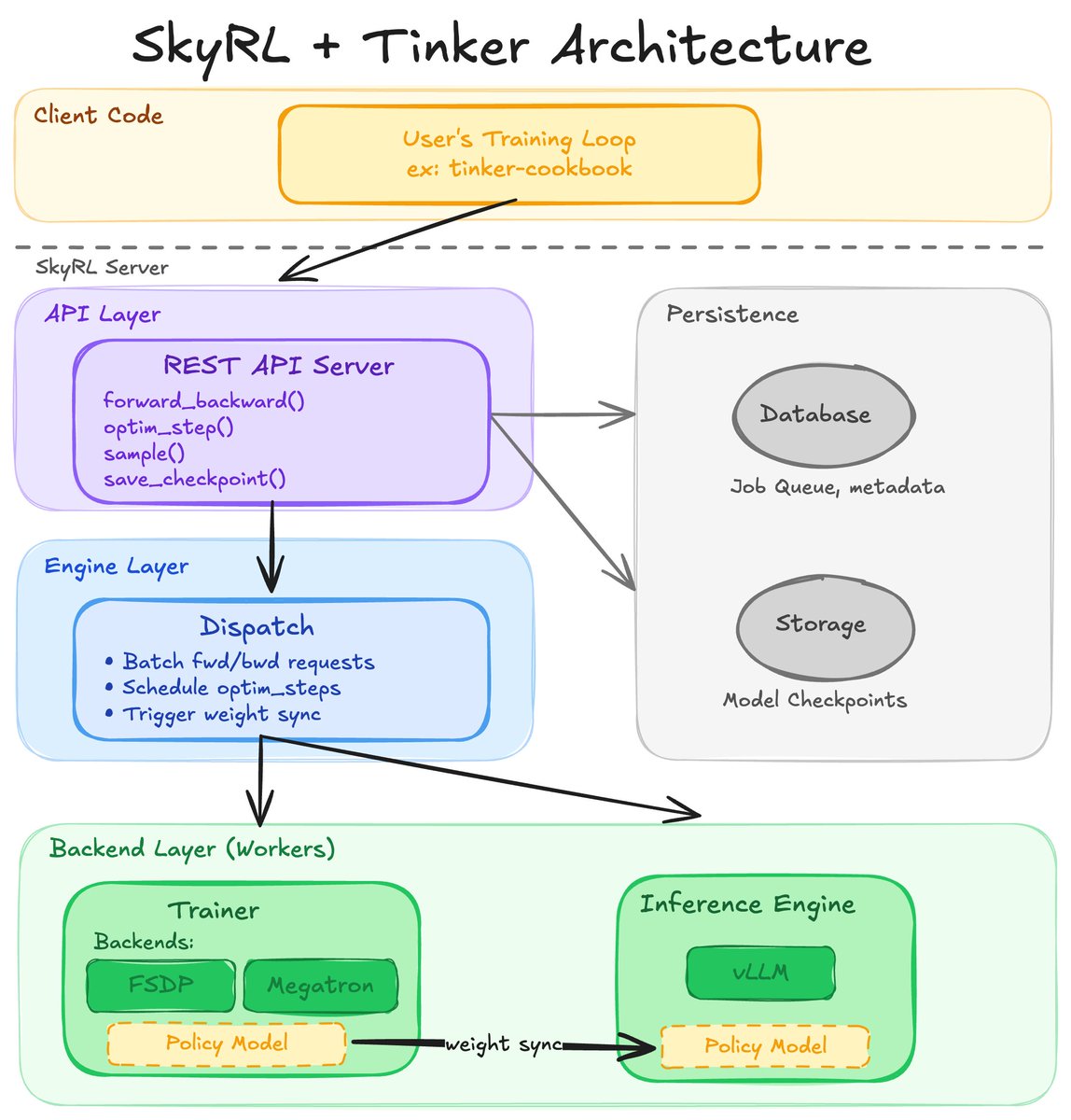
Zhuofeng Li@zhuofengli96475
🔥 Introducing Direct Corpus Interaction (DCI)! The best retriever for agentic search is no retriever.
🚀 We replaced the entire agentic search pipeline — embedding model, vector index, top-k retrieval — with only `grep` and `bash`. 🔧
📄 Paper: huggingface.co/papers/2605.05…
DCI unlocks the full agentic potential of any Claude Sonnet 4.6: 69.0% → 80.0% on BrowseComp-Plus (+11.0, −$424).
💡The Magic:
The agent searches the raw corpus directly — `grep`, `find`, `bash`, shell pipelines — exactly like a coding agent navigating a codebase. No preprocess. No embedding model. No vector index. No offline indexing.
📊The Results:
DCI outperforms top baselines across 13 benchmarks, with average gains of:
🔍 Agentic Search: +11.0%
🧠 Multi-hop QA: +30.7%
📈 IR Ranking: +21.5%
💡 Insights:
Beyond accuracy, we conduct a series of controlled ablation studies to pinpoint the sources of DCI’s gains. Specifically, we examine trajectory-level search, evidence utilization corpus, context management, and tool usage (RQ2-RQ6).
Try it yourself!
🛠️Code: github.com/DCI-Agent/DCI-…
🤖 Demo: huggingface.co/spaces/DCI-Age…
🔎 Eval logs: huggingface.co/datasets/DCI-A…