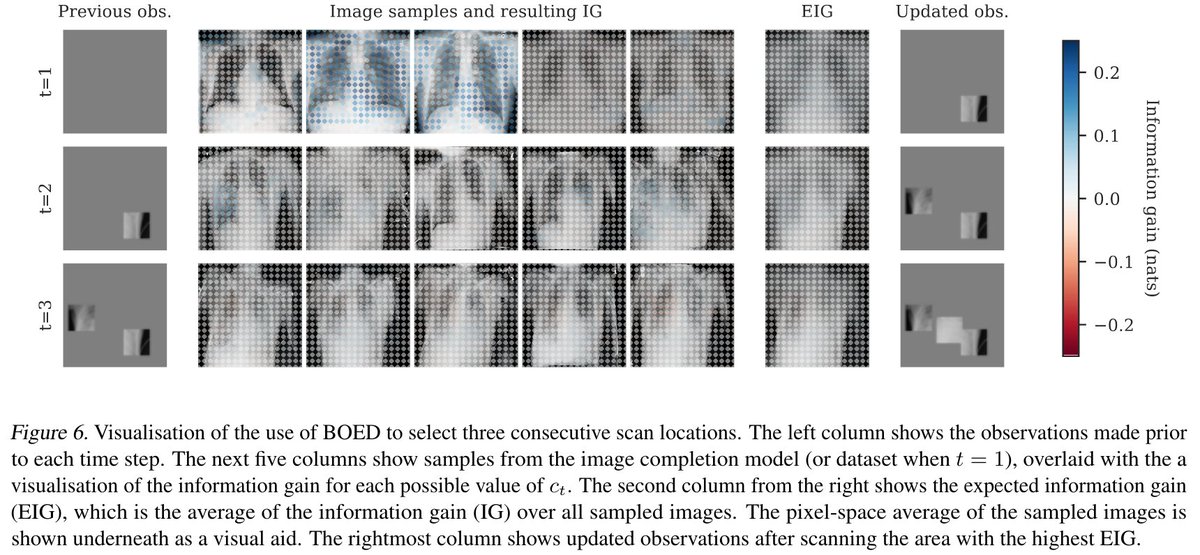
Will Harvey retweetledi

It is @NeurIPS time again! I am excited to present our trans-dimensional jump diffusion work with @AndrewC_ML @willarvey @ValentinDeBort1 @tom_rainforth and @ArnaudDoucet1 ! Come over on Thursday 2nd poster session, neurips.cc/virtual/2023/p…. arxiv.org/abs/2305.16261 #NeurIPS2023
English