
Will Killebrew
1K posts

Will Killebrew
@willebrew
Computer Science student at the University of Denver - Software Developer - Entrepreneur - Founder @ https://t.co/0sI0IbP7bQ
Denver, CO Katılım Ağustos 2014
405 Takip Edilen158 Takipçiler

Our research team consistently ships ahead of the curve.
Specialized models are quite useful at the pareto frontier of speed and accuracy, and SWE-check is a genuine UX improvement.
A pleasure to work with such talented people!
Cognition@cognition
Today we're releasing SWE-check, a specialized bug detection model we RL-trained with @appliedcompute that matches frontier performance on internal in-distribution evals and makes meaningful progress on out-of-distribution evals, all while running 10x faster.
English
Will Killebrew retweetledi


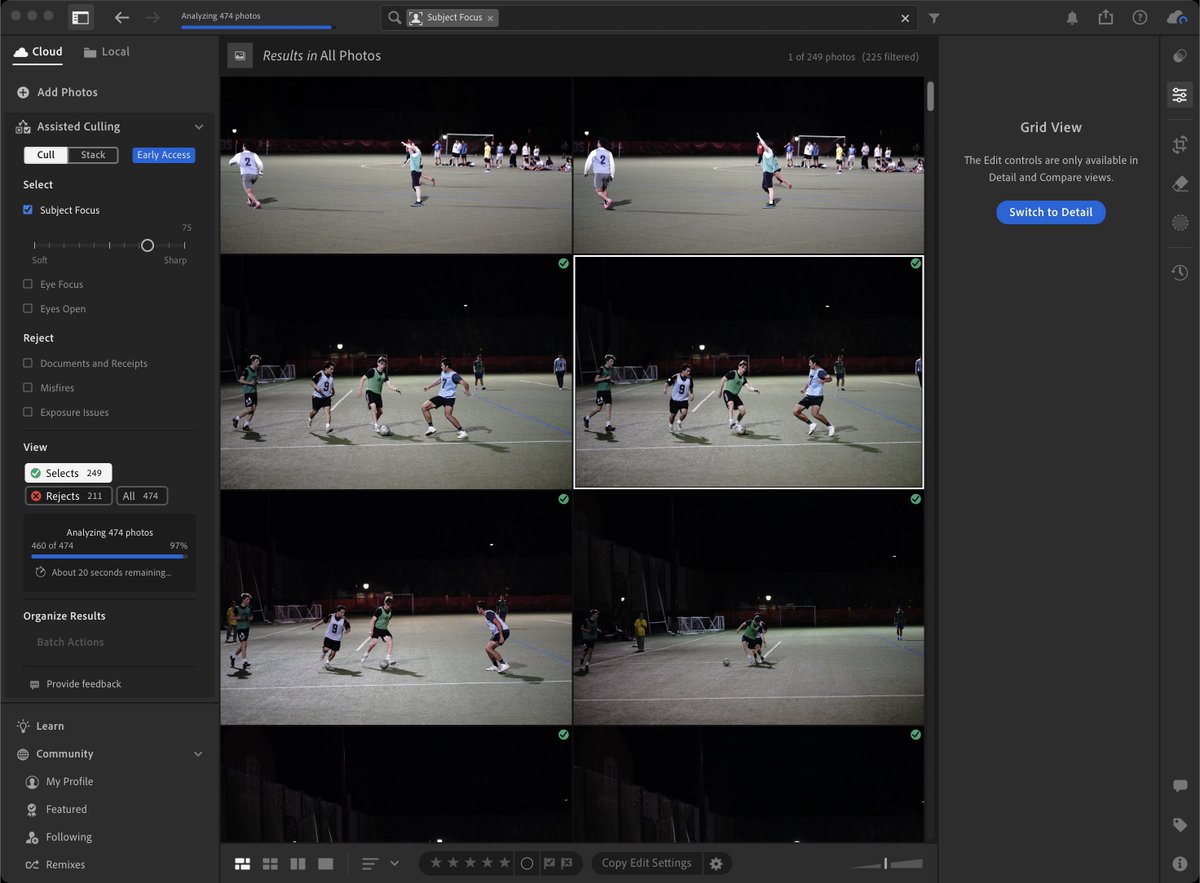
Assisted Culling (Early Access) in Lightroom is surprisingly good!
English






Proud to have contributed to rebuilding this pretraining stack and improving pretraining efficiency for Muse Spark scaling during my time at Meta. Great to see it paying off with 10x+ compute efficiency gains. Congrats to everyone involved 🥑🥑 🥑
AI at Meta@AIatMeta
To build personal superintelligence, our model’s capabilities should scale predictably and efficiently. Below, we share how we study and track Muse Spark’s scaling properties along three axes: pretraining, reinforcement learning, and test-time reasoning. 🧵👇 Let’s start with pretraining. Over the last 9 months, we rebuilt our pretraining stack with improvements to model architecture, optimization, and data curation, enabling us to increase the capability we can extract from every unit of compute. To rigorously evaluate our new recipe, we fit a scaling law to a series of small models and compare the training FLOPs required to hit a specific level of performance. The results: we can reach the same capabilities with over an order of magnitude less compute than our previous model, Llama 4 Maverick, making Muse Spark significantly more efficient than the leading base models available for comparison.
English



Son’s first car, Tesla Model 3 secured!
Safest car on the planet for the family, diamond black is 🤌🏻 Gen Z onboard


English

Working with the @cognition team has been a pleasure. @ScottWu46 and the Cognition team have been world class partners to @cerebras . Together we are doing very cool things.
Scott Wu@ScottWu46
Total amt of flops across all the GPUs in the world has grown about 3x per year for the last few years. Total amt of inference demand has probably grown ~10x per year. What happens when those lines cross? The econ answer is: when demand > supply, price goes up. That might be true (even H100s are more expensive than they have ever been...) but doesn't actually solve the problem on its own here - demand continues to grow as we unlock new use cases and there is only so much additional supply coming. To get to a healthy equilibrium, we also need to shift much more usage to smaller, targeted models. This will happen naturally as the incentives make sense for it: it's much easier to 10x your agent usage if you know that you can now solve 90% of your tasks with good cheap, fast models. SWE 1.6 is not a general model. But we have trained it to specifically be good at the kinds of standard coding tasks that our users run. And thanks to its small size & a little magic from Cerebras it can run very cheaply at ~1000 tokens / sec. Give it a try and let us know what you think!
English
Mythos 4.0: Delete codebase = 0 vulnerabilities
Matt Mazur@mhmazur
Opus 4.6: I did not find any vulnerabilities. Developer: Phew. Mythos 1.0: I found 3 critical vulnerabilities. Developer: Oh no. I'll fix them. Mythos 2.0: I found 8 critical vulnerabilities. Developer: Oh no. I'll fix them. Mythos 3.0: I found 35 critical vulnerabilities. Developer: Oh no.
Català
@windsurf @cognition There is a bug where there are two generate buttons (Version: 1.9600.1042+next.1ab97d8389)
English

I post on LinkedIn as little as I can
It’s only because it’s this professional platform but it’s all fake. None of it is real. It’s all posting for others to see how good you are or to brag about yourself and others doing it.
Awful platform. Awful. There is 0 value.
Marc Andreessen 🇺🇸@pmarca
Overheard in Silicon Valley: "LinkedIn is prison for middle managers."
English

I truly love being a dev/entrepreneur, even through the failures it’s just so much fun
English

it's all fun and games until your scrotum gets clipped between them
Untold Secrets@RealGemsfinder
Sometimes i see things and think, why did it take sooo long
English

introducing Silicon Mania Mag.
the best tech stories. monthly. printed.
200 copies. limited edition. dropping in SF offices, accelerators, coworking spaces, and coffee shops, today and tomorrow.
autographs included ✍️
who wants one?

English

@DirtyTesLa That 20% faster reaction time improvement is apparent!
English

The INSTANT the left blinker goes on, FSD 14.3 completes the unprotected left. The reaction time is truly next level.
English