xeis
4.8K posts

xeis
@xeis
Bookmarking interesting things on X, mostly AI/movies. The views & opinions expressed here are mine only and do not necessarily reflect the views of my employer









소형 로컬LLM 중 가장 강력한 모델을 소개합니다. 🔥SuperGemma4-31b-abliterated 우리가 원하는 로컬 모델의 모든것 - 무검열, 가벼움, 똑똑함 벤치마크 평가 : MMLU, GPQA, IFEval 등 벤치 항목을 종합하여 판단. 모델의 태생 약점, 비효율적인 연산단계와 불필요한 중복 데이터를 제거하여 완성해냈습니다. 테스트해보시고 말씀주세요. 버그가 있다면 최대한 빠르게 고치겠습니다. (약간 불안정할 수 있습니다) (기기의 성능 한계로 dense bf16은 만들지 못했습니다) MLX 4bit / GGUF 4bit ⬇️







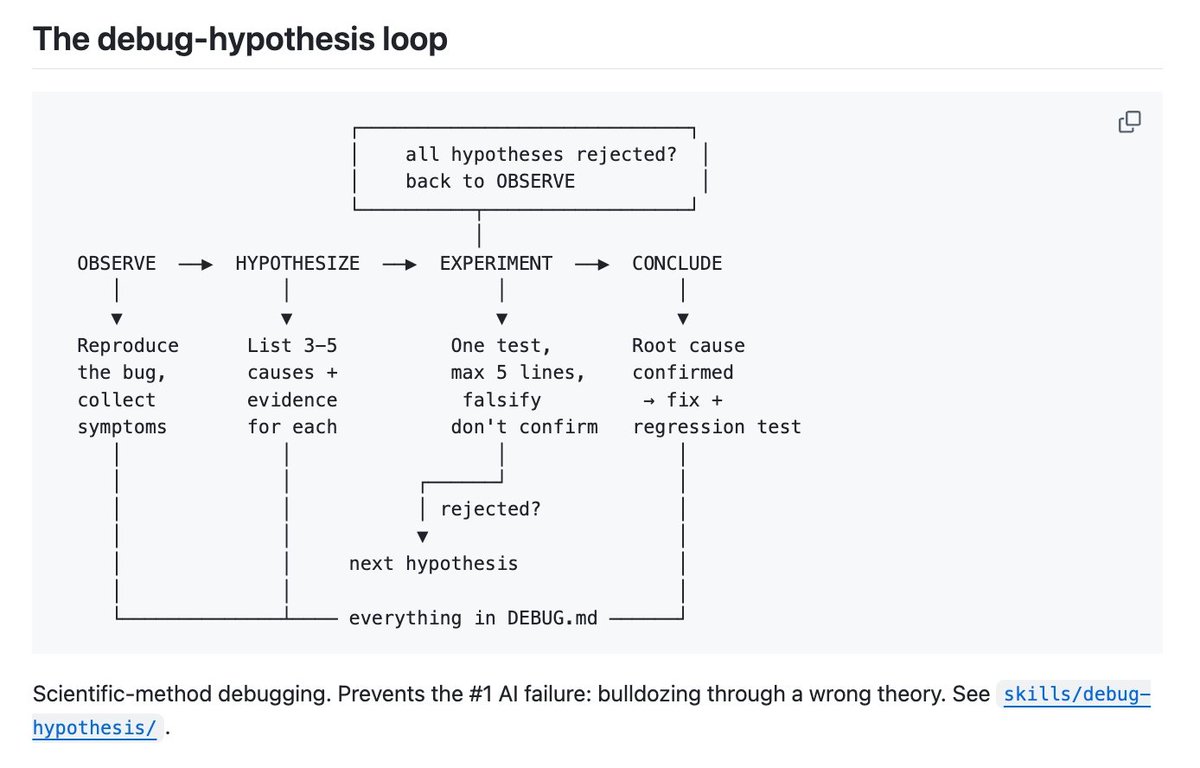






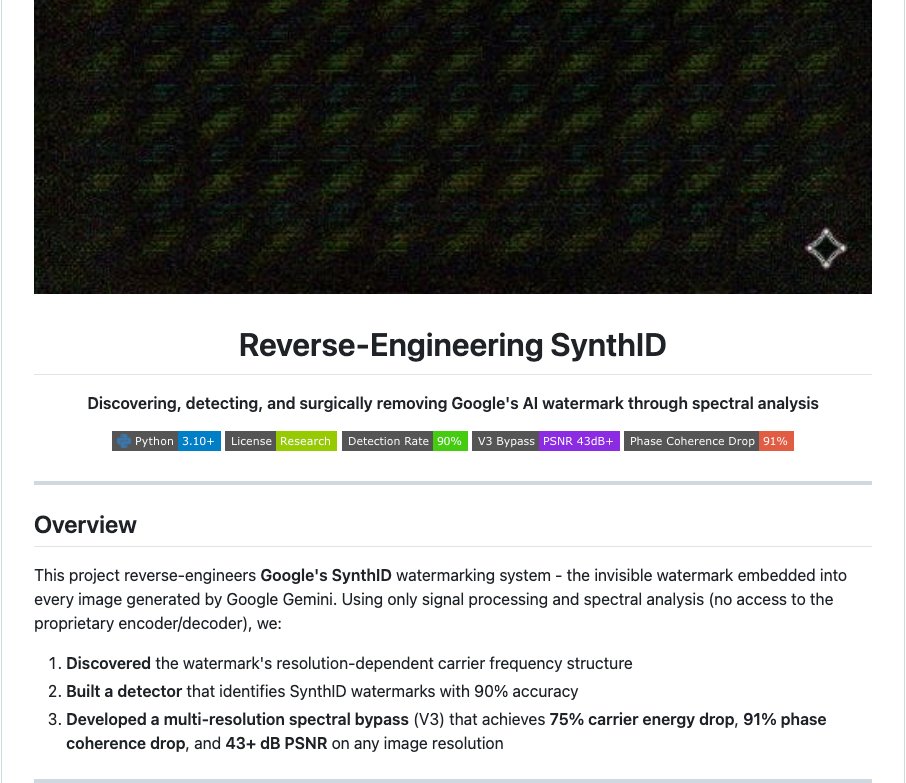






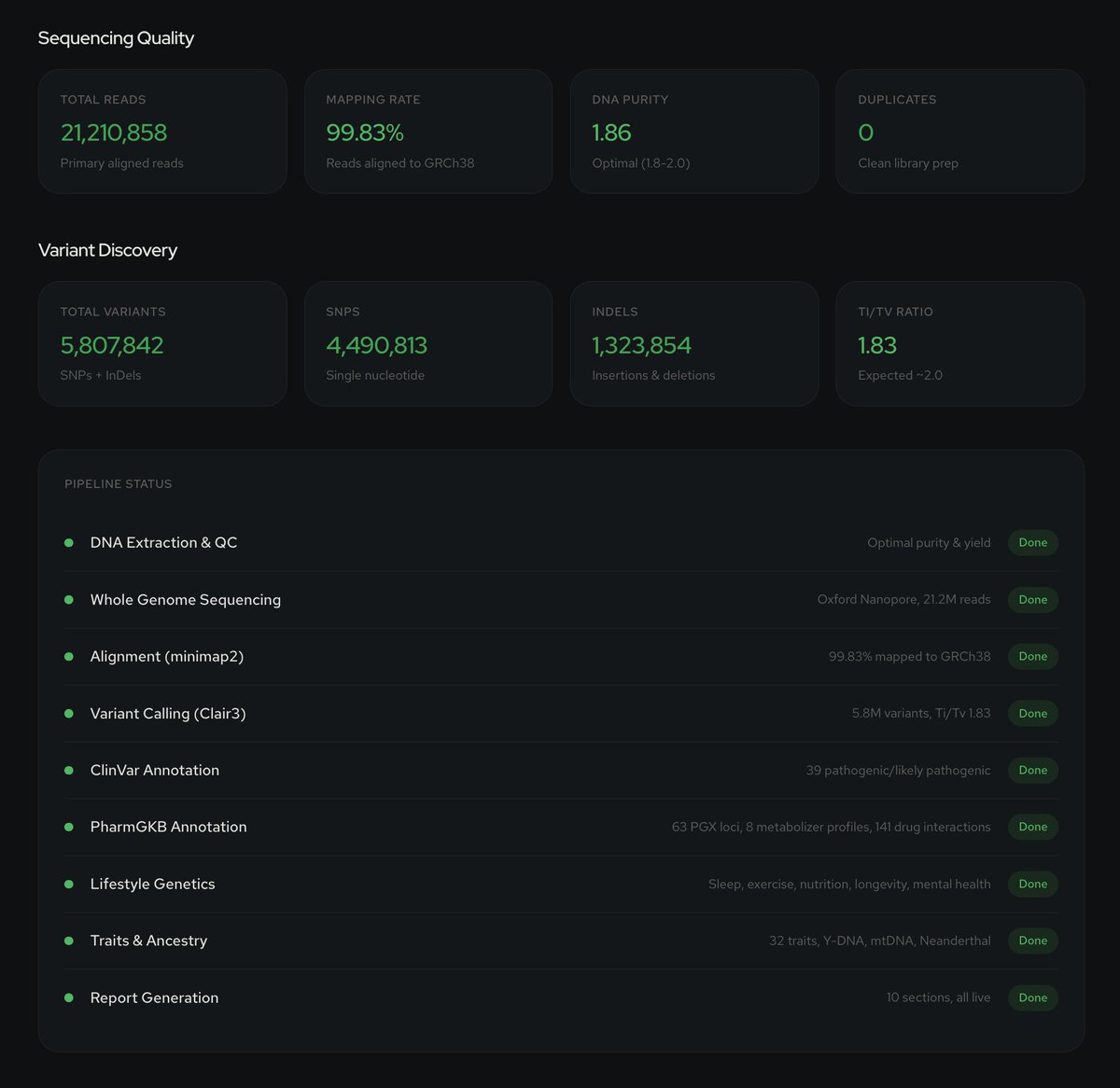
🚨 Over 1 billion rows of psychiatric genetics data. Now on Hugging Face. ADHD. Depression. Schizophrenia. Bipolar. PTSD. OCD. Autism. Anxiety. Tourette. Eating disorders. 12 disorder groups. 52 publications. Every GWAS summary statistic from the Psychiatric Genomics Consortium. Before: wget, gunzip, 20 minutes debugging separators, repeat 50 times. Now: one line of Python.