Guilherme Favaron@guifav
Test time scaling is the current bet for making LLM agents smarter: just give them more compute at inference. But does it actually work for general purpose agents?
New benchmark from @XiongChenyan and Xiaochuan Li at @CMU_LTI, with collaborators from @MetaAI, tested 10 leading agents across search, coding, reasoning, and tool use in a unified setting.
Two findings that should concern anyone building agent products:
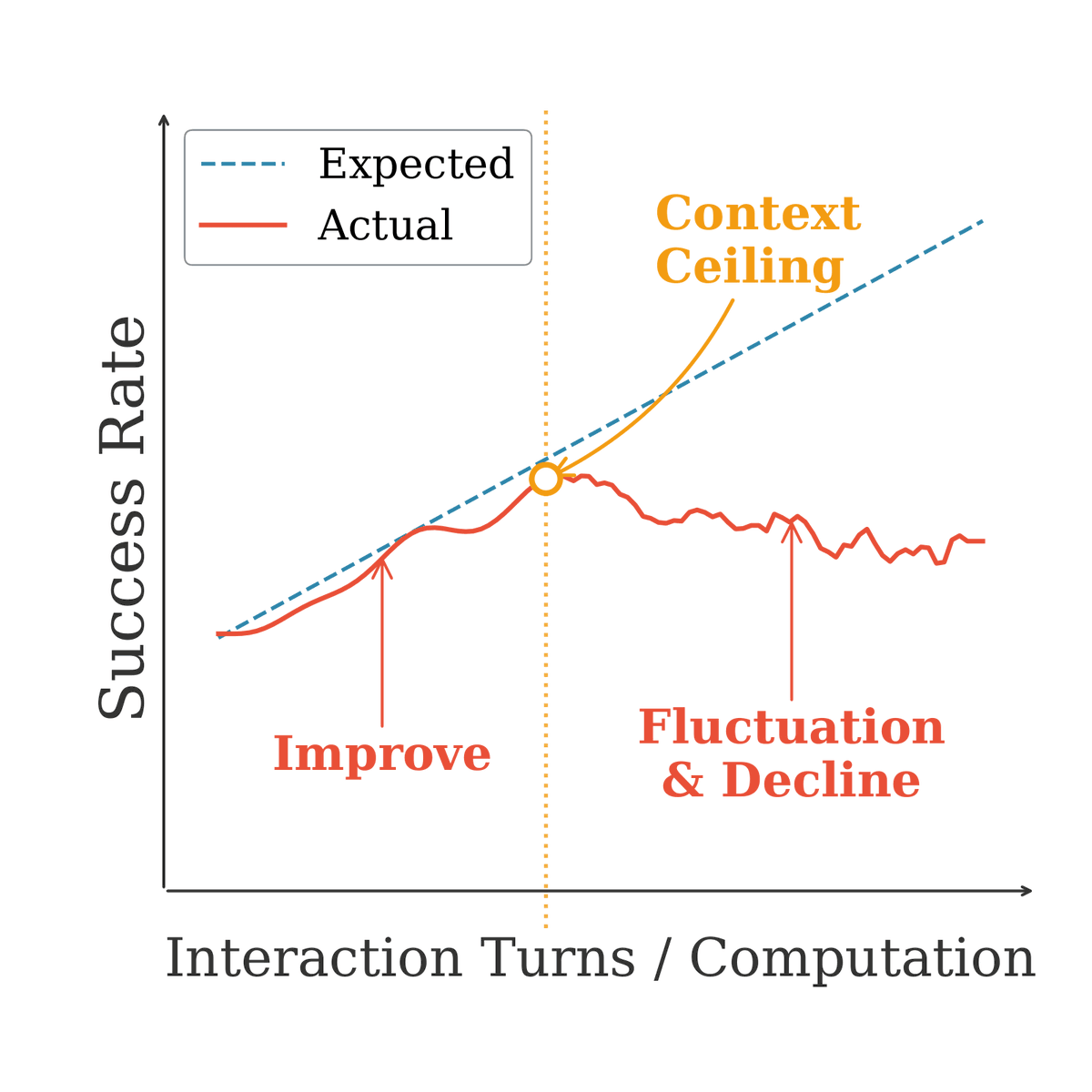
1. Sequential scaling (longer interactions) hits a 'context ceiling' around 96K to 112K tokens. Beyond that, agents destabilize. More rounds of interaction make them worse, not better.
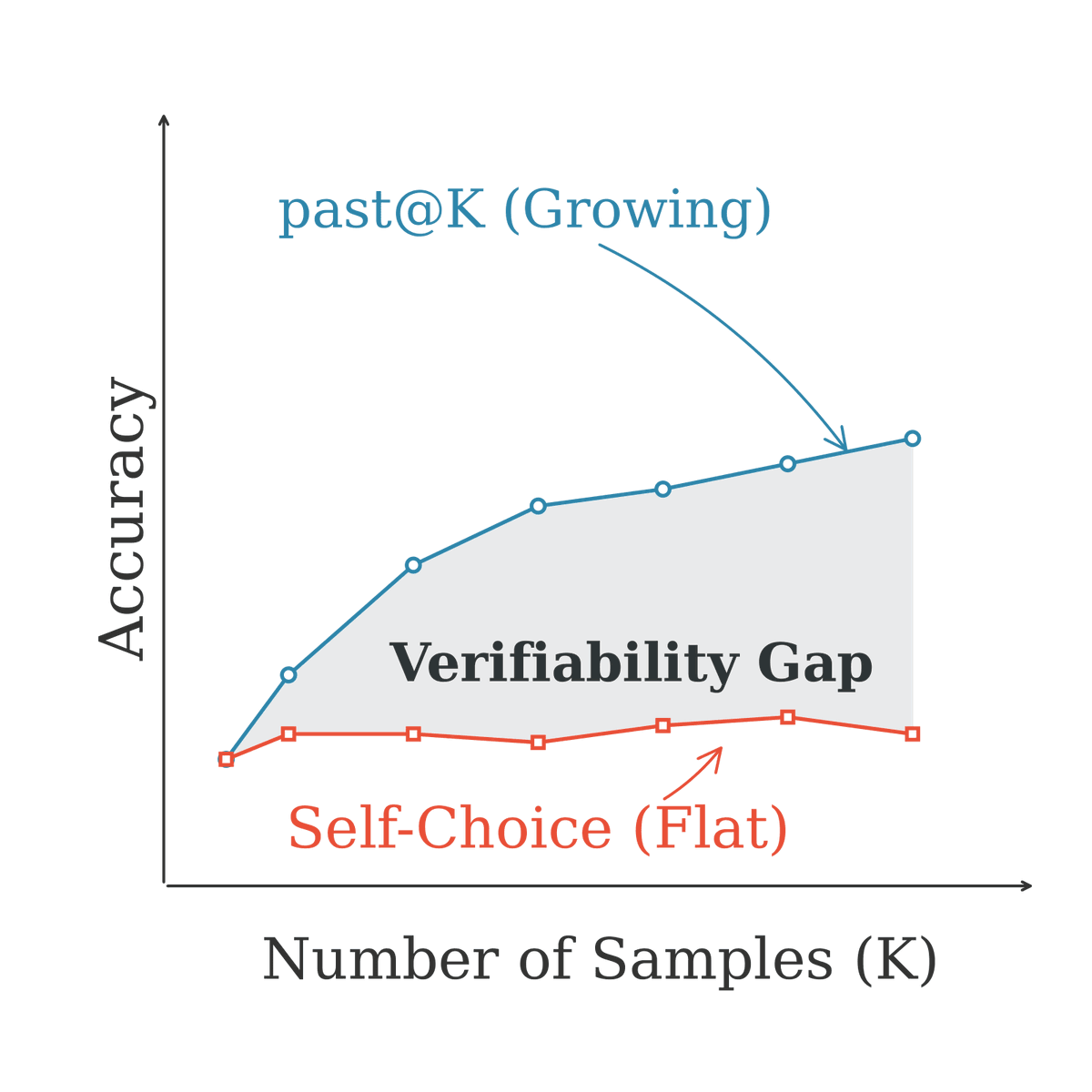
2. Parallel scaling (sampling multiple trajectories) looks good on paper (pass@K improves), but agents cannot reliably pick their own best answer. The 'verification gap' means real world gains are minimal.
Models also showed 10 to 30% performance drops just from moving to a general agent setting vs. domain specific benchmarks.
Source: arXiv 2602.18998