Xiaowei Huang
927 posts

Xiaowei Huang
@xiaoweih
Father of a girl. Professor of computer science, working on the safety and trustworthiness of AI & ML systems.


The countries with the highest rates of smartphone addiction: 1. 🇨🇳 China 2.🇸🇦 Saudi Arabia 3.🇲🇾 Malaysia 4.🇧🇷 Brazil 5.🇰🇷 South Korea 6.🇮🇷 Iran 7. 🇨🇦 Canada 8.🇹🇷 Turkey 9.🇪🇬 Egypt 10.🇳🇵 Nepal 11.🇮🇹 Italy 12.🇦🇺 Australia 13.🇮🇱 Israel 14.🇷🇸 Serbia 15.🇯🇵 Japan 16.🇬🇧 United Kingdom 17.🇮🇳 India 18.🇺🇸 United States 19.🇷🇴 Romania 20.🇳🇬 Nigeria 21.🇧🇪 Belgium 22.🇨🇭 Switzerland 23.🇫🇷 France 24.🇩🇪 Germany
My all time favorite.. ❤️ Never gets old..

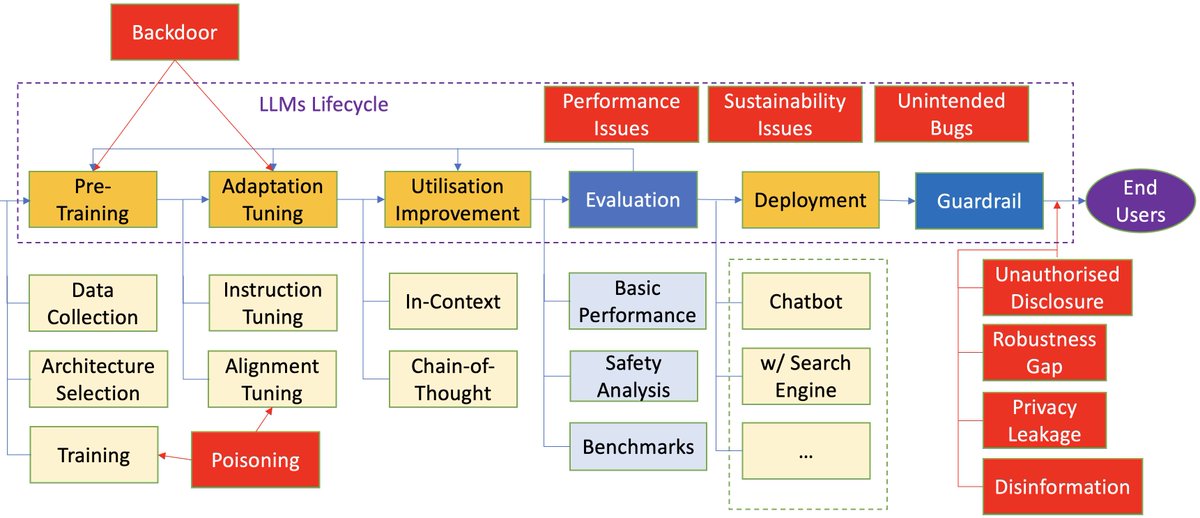
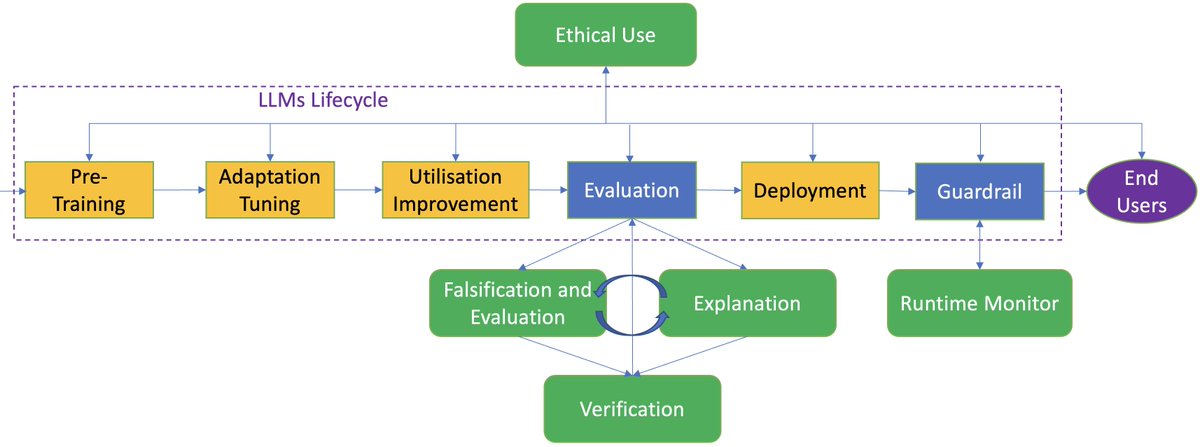

Bank of England economist says people need to accept they are poorer trib.al/lePGD3J
JUST IN - Elon Musk tells Tucker Carlson that various government agencies had full access to everything that's going on Twitter.. including people's DMs (direct messages). Full interview on 8 pm ET Monday!!!