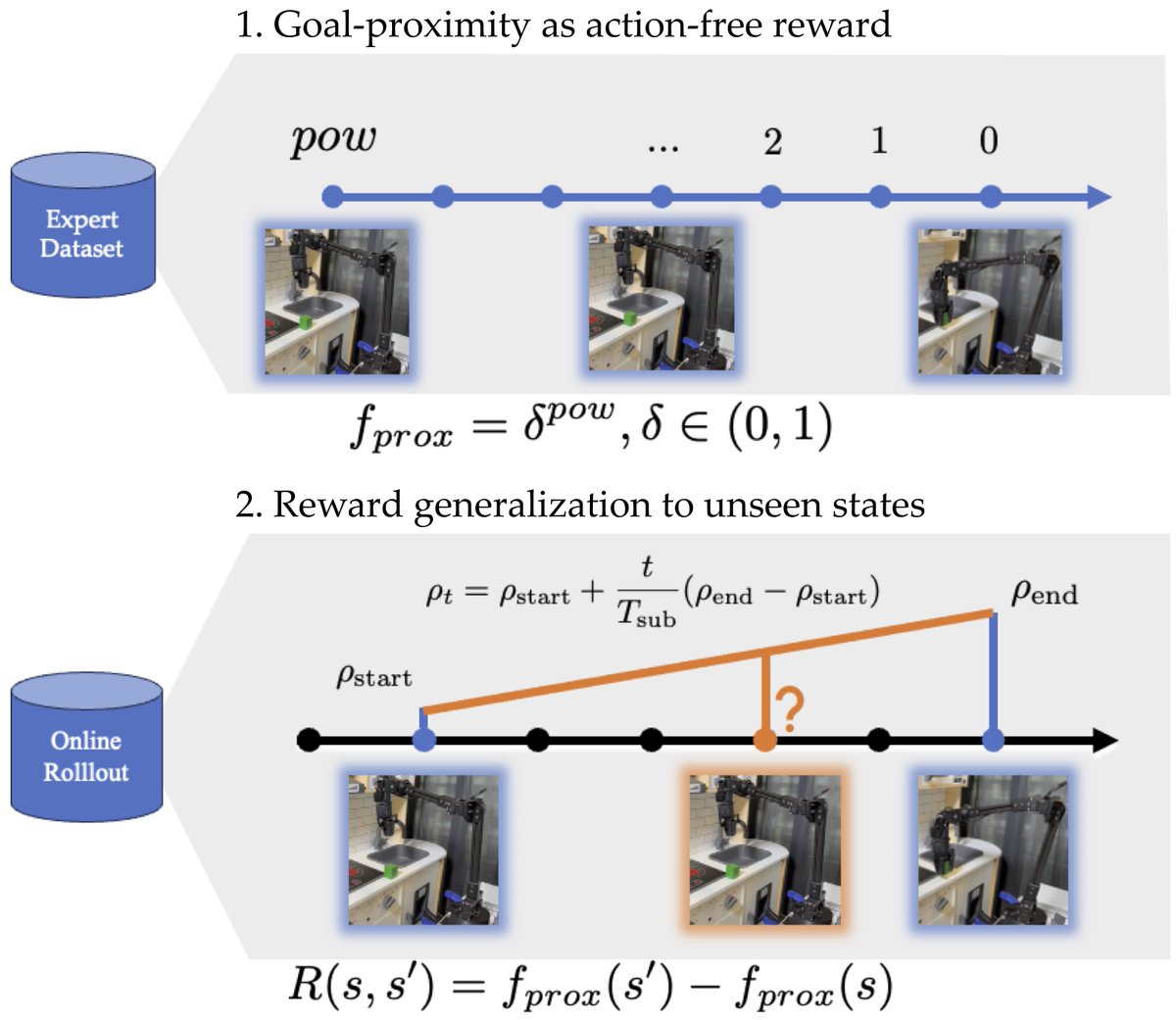
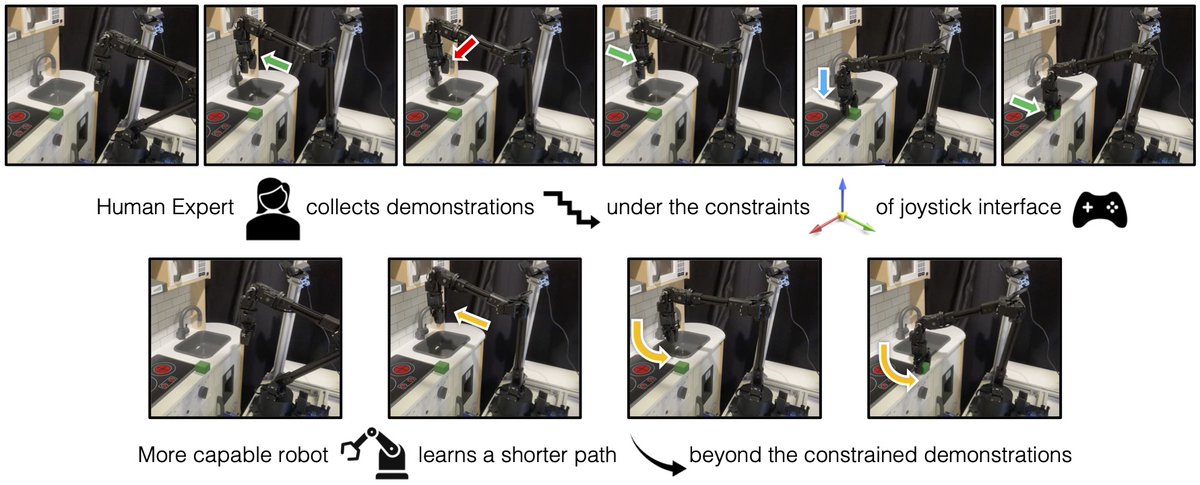
We are excited to be presenting LfCD at ICLR 2026! Please reach out if you want to chat!
Paper: arxiv.org/abs/2510.09096.
Website: sites.google.com/view/constrain…
Joint work with — @Ayushj240 @zhaojingy_1026 @yigitkkorkmaz @ebiyik_
— huge thanks to an amazing team!
English