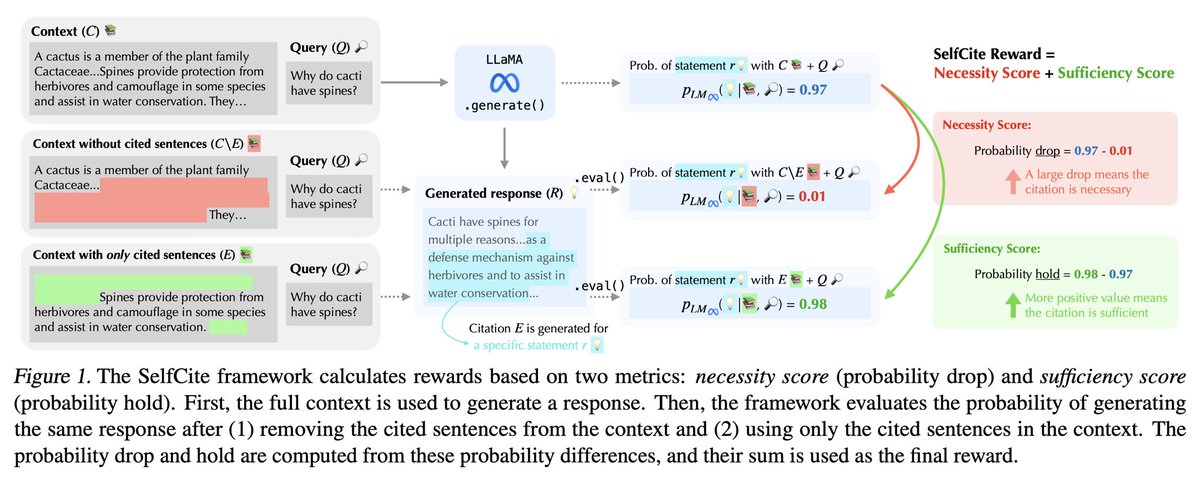
Learning from feedback is instrumental but human preference data can be expensive. How much reward supervision could we get from raw web text instead, without human labels? Our latest work, built on a year of incredible effort by @fjxdaisy, advances pure RLHF training across multiple models and tasks. Unsupervised Reward Modeling: split web docs into (prefix, true continuation); treat mismatched continuations in-batch as negatives; train w/ BT loss + score-centering. Findings: 📝 steady gains on RewardBench v1/v2 using just 11M tokens of math web text 📝 transfers across backbones (Llama-3.2 1B/3B, Qwen2.5 3B/7B Instruct) 📝 improves Best-of-N selection (math + safety) and provides a usable reward for GRPO policy optimization 📝 acts as a mid-training procedure that helps further RLHF 📑Paper: arxiv.org/abs/2603.02225 🌐Project: jingxuanf0214.github.io/reward-scaling Joint work with @lisali126, @ZhentingQi, @zdhnarsil, @xkianteb, @ShamKakade6