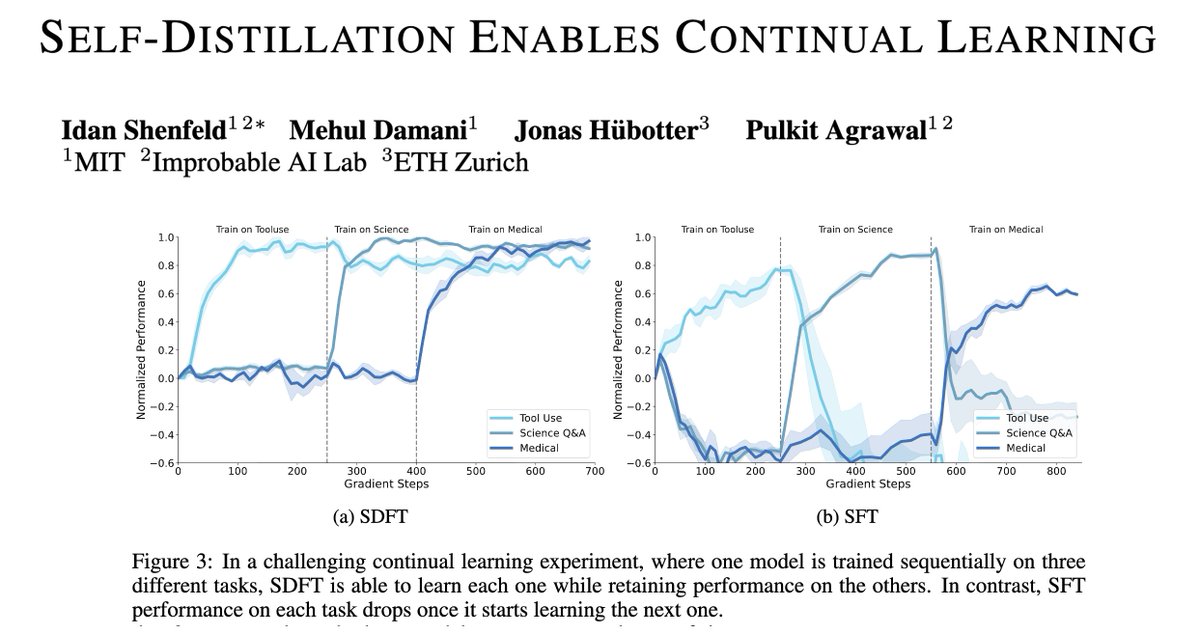
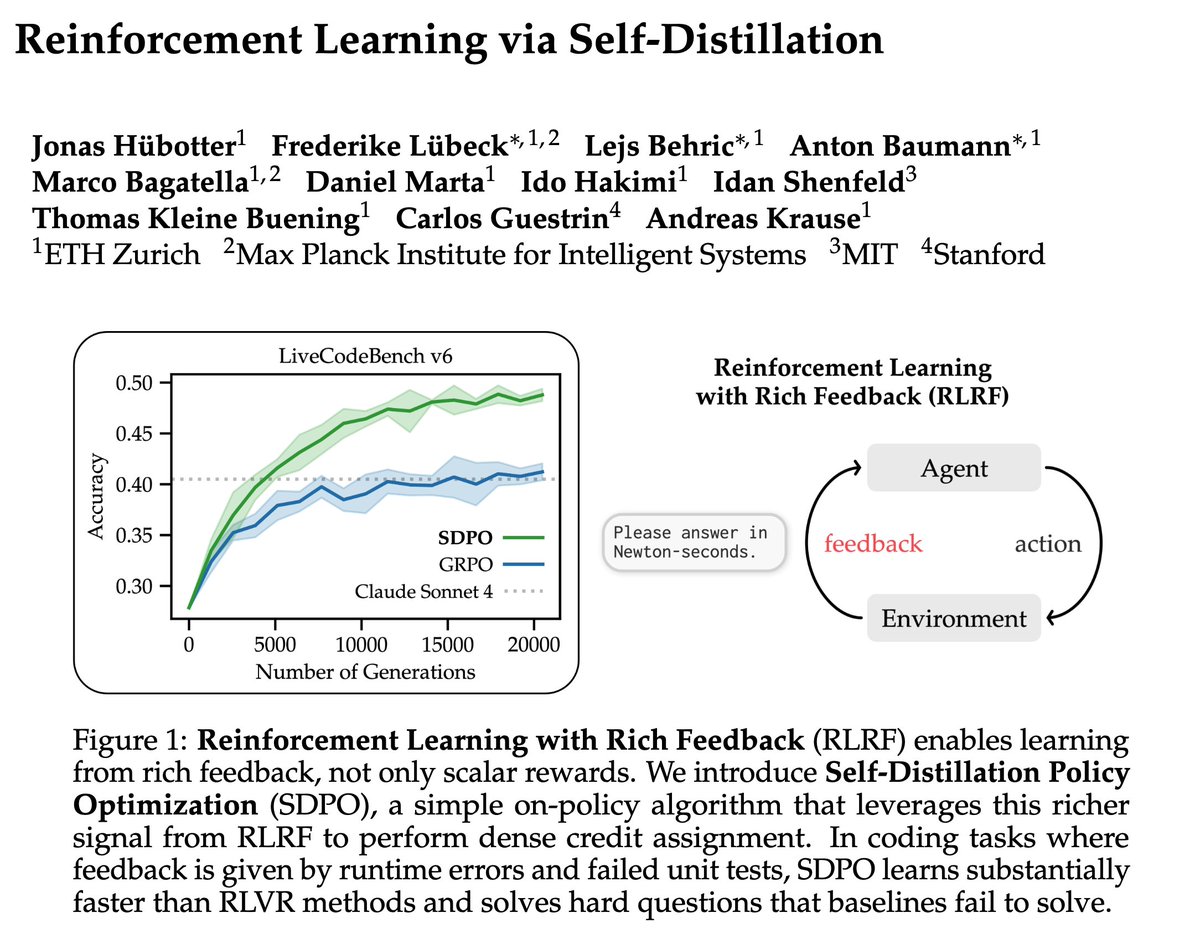
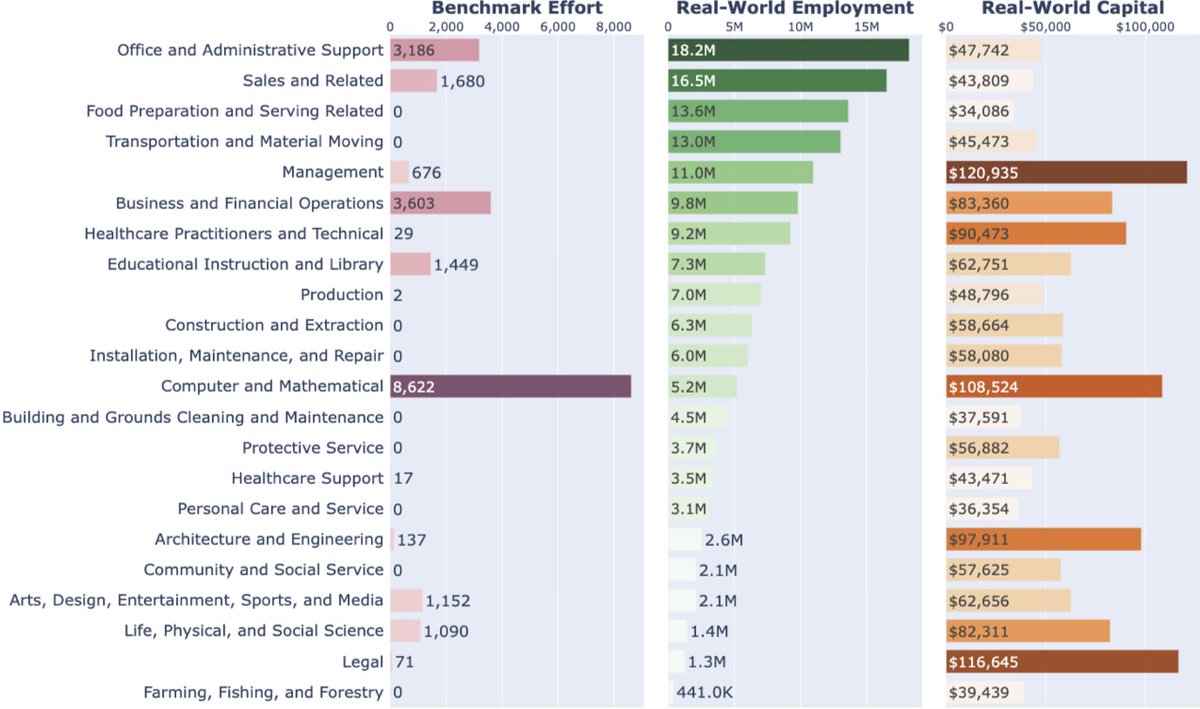
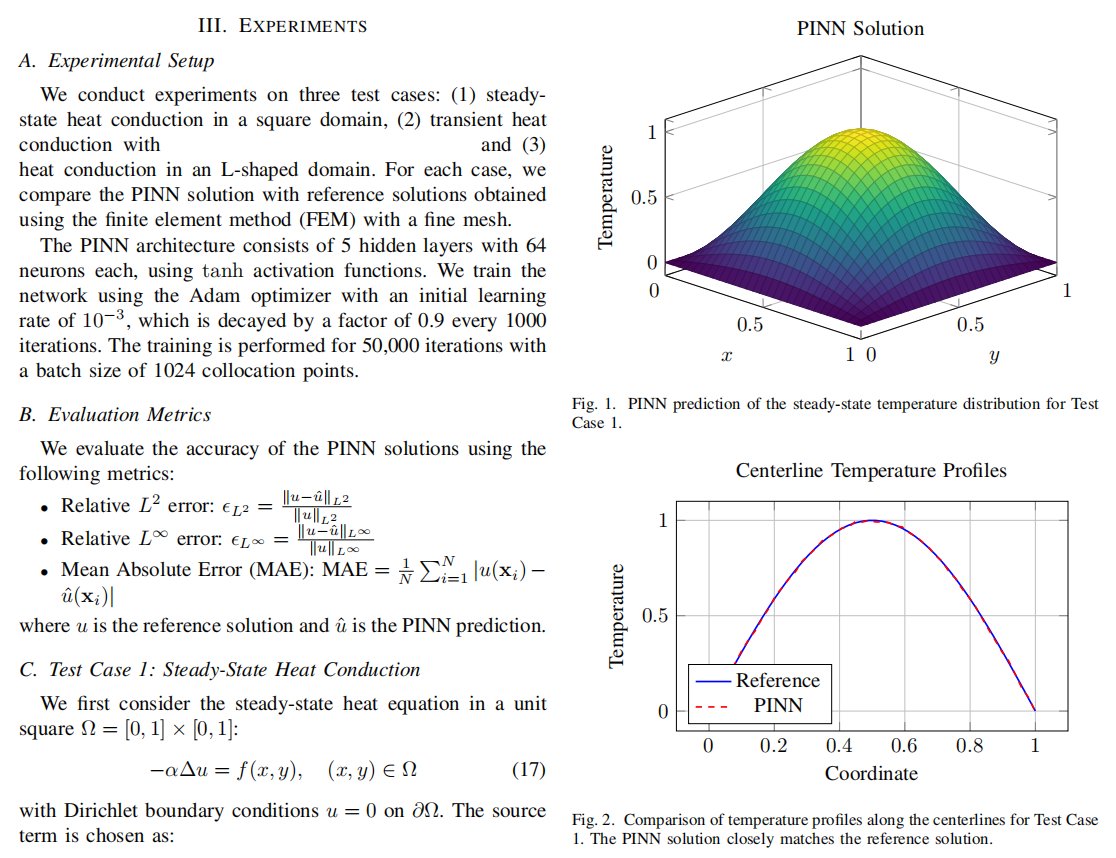
Sabitlenmiş Tweet

💪🦾Agentless Training as Skill Prior for SWE-Agents
We recently released the technical report for Kimi-Dev. Here is the story we’d love to share behind it: (1/7)

English
Zonghan Yang
1.3K posts

@yang_zonghan
PhD student at Tsinghua NLP & AIR, studying agents that automate tasks ranging from daily activities to creative endeavors. Two drifters with the world to see.



me stepping down. bye my beloved qwen.












There's a new kind of coding I call "vibe coding", where you fully give in to the vibes, embrace exponentials, and forget that the code even exists. It's possible because the LLMs (e.g. Cursor Composer w Sonnet) are getting too good. Also I just talk to Composer with SuperWhisper so I barely even touch the keyboard. I ask for the dumbest things like "decrease the padding on the sidebar by half" because I'm too lazy to find it. I "Accept All" always, I don't read the diffs anymore. When I get error messages I just copy paste them in with no comment, usually that fixes it. The code grows beyond my usual comprehension, I'd have to really read through it for a while. Sometimes the LLMs can't fix a bug so I just work around it or ask for random changes until it goes away. It's not too bad for throwaway weekend projects, but still quite amusing. I'm building a project or webapp, but it's not really coding - I just see stuff, say stuff, run stuff, and copy paste stuff, and it mostly works.

🚀 daVinci-Agency: Mining chain-of-pull-requests for long-horizon agents 📊 239 samples → 47% gain ⚡ Data efficiency redefined Paper: arxiv.org/abs/2602.02619