Sabitlenmiş Tweet

yourcasual.dev (vi/vim) △
648 posts

@yourcasualdev
"Sucking at something is the first step towards being sorta good at something."
Usage limits are up, effective today we're: 1) Doubling Claude Code's 5-hour limits for Pro, Max, Team and seat-based Enterprise plans 2) Removing peak hours limit reduction on Claude Code for Pro and Max plans 3) Substantially raising our API rate limits for Opus models
Introducing SubQ - a major breakthrough in LLM intelligence. It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA), And the first frontier model with a 12 million token context window which is: - 52x faster than FlashAttention at 1MM tokens - Less than 5% the cost of Opus Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention). Only a small fraction actually matter. @subquadratic finds and focuses only on the ones that do. That's nearly 1,000x less compute and a new way for LLMs to scale.

I've hit limits on Gemini 3.1 Pro High on Antigravity after just giving a prompt and then a follow up prompt. And I'm on Google AI Pro plan. What's happening?
🚨 Anthropic CEO Tells Pentagon “NO.” >pentagon: “use claude for ALL lawful purposes” >dario: no >pentagon: do as we say or you’re blacklisted >dario: “these threats do not change our position” Anthropic CEO final message to Department of War: >no fully autonomous weapons without humans >no mass domestic surveillance for Americans Pentagon official calls Dario a “liar with a God-complex” who “wants to personally control the US Military” and is “ok putting our nation’s safety at risk.” >xAI, Google & OpenAI all agreed to the Pentagon’s terms Anthropic: “Regardless, we cannot in good conscience accede.”


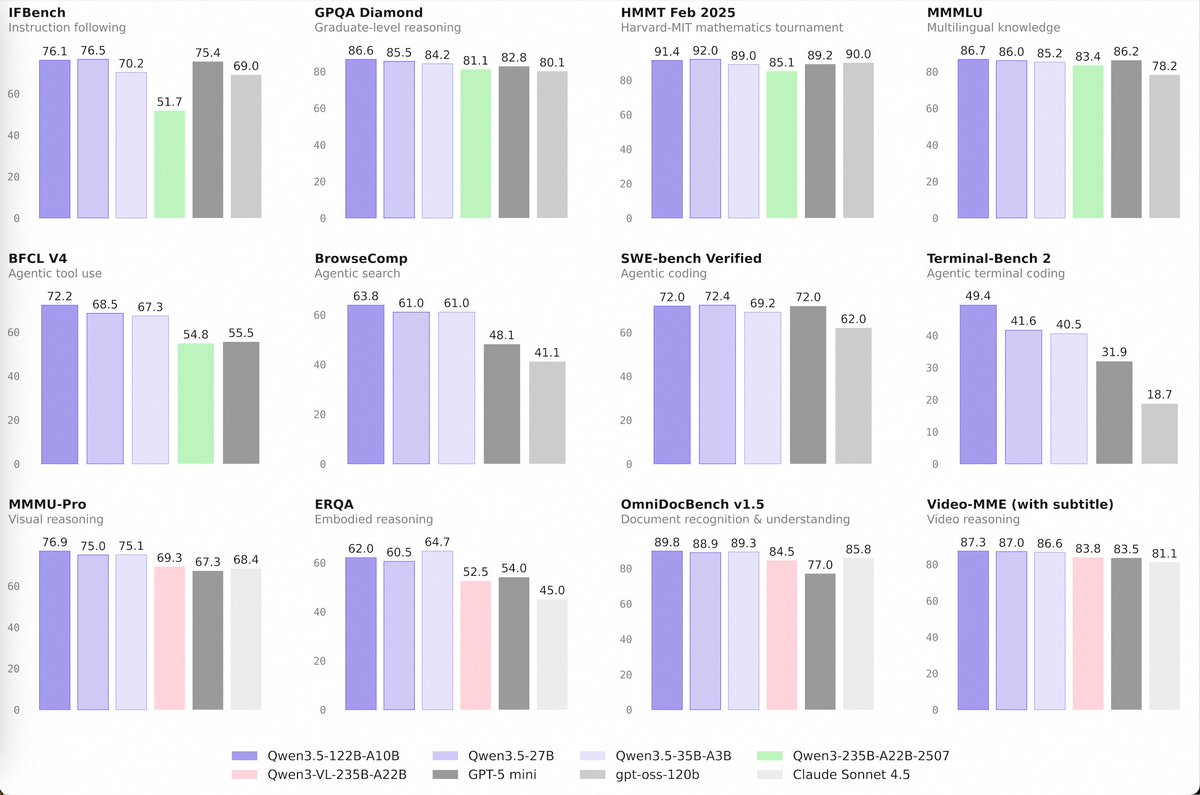
Enpara yine kritik bir vuruş yapiyor

MiniMax M2.5-HighSpeed⚡is live! 100 TPS — enjoy the 3× speed. In the 48 hours since launch, thank you all for your incredible support and love for MiniMax M2.5! Designed for the next generation of Agent applications, we’ve officially launched MiniMax-M2.5-HighSpeed. Delivering blazing-fast inference at 100 TPS — 3× faster than similar models. Supports both API integration and Coding workflows. Choose from Plus, Max, or Ultra plans. Invite friends and enjoy 10% off instantly. Wishing you all Happy Chinese New Year! May the 🐎 year bring speed, scale, and breakthrough luck. 🚀




