
Yu Hao (郝宇)
85 posts
Yu Hao (郝宇)
@yuhao2222
System Security Researcher. CS Ph.D. @UCR_CSE. #SystemSecurity #Fuzzing #ProgramAnalysis
Riverside, CA Katılım Temmuz 2016
382 Takip Edilen347 Takipçiler


Yu Hao (郝宇) retweetledi

Ep5. Rebuttal MLFuzz
Thanks Irina’s response. We never heard back from you and @AndreasZeller since last month when we sent the last email to ask if you guys were willing to write an errata of MLFuzz to acknowledge the bugs and wrong conclusion. So I am happy to communicate with you in the public channel about this issue and clarify the misleading conclusions in your paper MLFuzz in front of the fuzzing community.
Our first email pointed out 4 bugs in MLFuzz and we showed that if you fixed the 4 bugs you can successfully reproduce our results. We also provide a fixed version of your code and preliminary results on 4 FuzzBench programs. Your first response confirmed 3 bugs but refused to acknowledge the most severe one – an error in training data collection. For any ML model, garbage in, garbage out. If you manipulate the training data distribution, you can cook any arbitrary poor results for an ML model.
Why are you reluctant to fix the training data collection error? Instead, you insist on running NEUZZ with the WRONG training data and cooking invalid results even though we already notified you of this issue. We suspect maybe that’s the only way to keep reproducing your wrong experiment results and avoid acknowledging your error in MLFuzz.
Your research conduct raised a serious issue about how to properly reproduce fuzzing performance in the Fuzzing community. Devil’s advice: blindly, deliberately or stealthily run it with WRONG settings or patch it with a few bugs and claim its performance does not hold? Only an ill-configured fuzzer is a good baseline fuzzer.
We think a fair and scientific way to reproduce/revisit a fuzzer should ensure running a fuzzer properly as the original paper did, rather than free-style wrong settings and bug injections.
The fact is you guys wrote buggy code (you confirmed in the email) and cooked invalid results and wrong conclusions published in a top-tier conference @FSEconf 2023. We wrote a rebuttal to point out 4 fatal bugs in your code and wrong conclusions.
A responsible and professional response should directly address our questions about the 4 fatal bugs and wrong conclusions. But your response discussed the inconsistent performance number issue of NEUZZ (due to a different metric choice), the benchmark, seed corpus, IID issue of MLFuzz. They are research questions about NEUZZ and MLFuzz, but they are not the topic of this post: MLFuzz rebuttal.
They can only shift the audience's attention but cannot fix the bugs and errors in MLFuzz. I promise I will address every question in your response in a separate post on X, but not in this one. Stay tuned! @is_eqv @moyix @thorstenholz @mboehme_

English
Yu Hao (郝宇) retweetledi

Zheng will present his work at @USENIXSecurity on Thursday morning about the accurate bisection of bugs found by fuzzers -- figuring out which commit introduced the bug. Useful for #aixcc potentially, but unfortunately we didn't get a chance to use it ourselves. #usesec24

English
Yu Hao (郝宇) retweetledi

syzkaller, our award-winning kernel fuzzer
github.com/google/syzkall…
got snapshot-based mode
github.com/google/syzkall…
It's not very fast but based 100% on stock qemu: savevm/loadvm+ivshmem
Significantly improves reproducibility for corpus&crashes but we just started evaluating it
English
Yu Hao (郝宇) retweetledi


Yu Hao (郝宇) retweetledi
SyzRetrospector: A Large-Scale Retrospective Study of Syzbot
arxiv.org/pdf/2401.11642…
by @pkqzy888 @arrdalan13
Lots of great detailed data and insights on kernel fuzzing bugs found by syzbot
English
Yu Hao (郝宇) retweetledi

📣📣Today is the first day of #HotSoS2024! Opening remarks will take place at 10am CT, to be followed by a keynote speech by @TaliaRinger (Language Models for Formal Proof.")! Register now and join us!

English
English

Excited to share that I’ve been selected as an Apple Scholar in AI/ML this year! Thanks Apple and all my mentors, collaborators, and friends at @uwdub @uw_ischool @uwcreate, especially @wobbrockjo! machinelearning.apple.com/updates/apple-…
Bellevue, WA 🇺🇸 English
Yu Hao (郝宇) retweetledi
The latest generation LLMs are very good, but they cannot work all by themselves to replace program analysis. I believe it is a promising direction to understand how LLMs can complement program analysis (in selective settings). This study is really only scratching the surface.
Haonan Li@haonanli0
A lot of people are skeptical about how useful LLMs are in bug finding, but our latest work accepted by OOPSLA improves static analysis with LLMs to detect UBI bugs in practice. We've uncovered some new bugs in the Linux kernel! #LLift #BugDetection #LLM #StaticAnalysis #Linux
English
@degrigis @gannimo @IEEESSP @patrickgtraynor @willenck I think the same for @acm_ccs @USENIXSecurity @NDSSSymposium .
English

@gannimo @IEEESSP Same! 2 accepts and a (debunked) bogus review. And yeah, reviewers have the last word, but they MUST add a comment if they reject after discussion. This has to change @patrickgtraynor @willenck or I'm willing to never submit again to @IEEESSP. It's so disrespectful!
English
Got a rejection notification with as much explanation as a magic trick: now you see it, now you don't. 🎩 Very happy about the time invested in writing a nice doc for that "interactive rebuttal". This is bad @IEEESSP #PeerReviewFail
English
Yu Hao (郝宇) retweetledi
The first author of the paper @XingyuLi816
is looking for internships. Give him a shot if you are hiring😀
English
Yu Hao (郝宇) retweetledi
We tried hard to understand many aspects of how the ecosystem works in the industry. Unfortunately the paper was not published in a top academic venue. But the practical relevance of the work is what motivated us -- bridging the gap between academia and industry is a lot of fun.
Brad Spengler@spendergrsec
Tons of great info in "An Investigation of Patch Porting Practices of the Linux Kernel Ecosystem": arxiv.org/pdf/2402.05212… that, if you've been listening to me, shouldn't come as much of a surprise. Will share a few snippets/comments in thread:
English
Yu Hao (郝宇) retweetledi
syzbot now provides historic fuzzing code coverage reports for #Linux kernel, see "coverage report" here:
syzkaller.appspot.com/upstream/manag…
These allow to asses what's covered and what's not.
But also how a particular line of code can be reached (it shows test cases that reached each line)
English
@DongdongShe I remember there was a paper called Evaluating fuzz testing, which is also great.
English
How do you conduct a SCIENTIFIC evaluation for fuzzing research?
Blindly run different fuzzers regardless of their settings for 24 hours and compare their raw coverage number?
Here are a few tips I found that fuzzer practitioners and researchers often ignore.
English
Yu Hao (郝宇) retweetledi

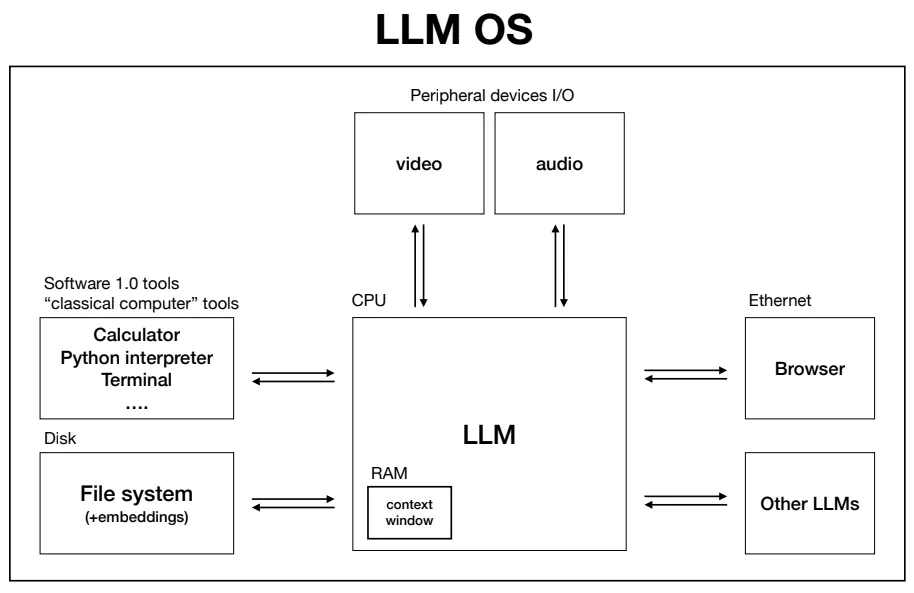
I summarized Andrej's talk and added my personal anecdotes to write this curious beginner's guide on:
- How LLMs work
- How LLMs are trained
- How LLMs can be tailored for each company
- How LLMs can evolve into an operating system
📌 Here's the link, I hope you enjoy it: creatoreconomy.so/p/curious-begi…
English