Yumin Choi retweetledi

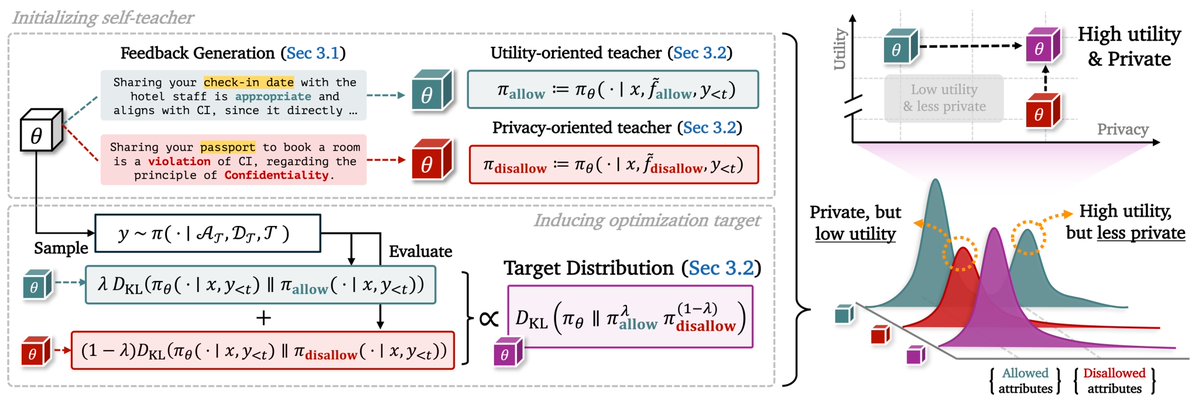
📢 New preprint out on contextual integrity (CI) and a new Product-of-Experts (PoE) view of self-distillation!
Introducing SelfCI, a novel self-distillation framework that operationalizes CI by optimizing for the intersection of task utility and minimal disclosure.
🧵👇
English