Sabitlenmiş Tweet

Yusuke
416 posts

@yusuke_post
スタートアップ@AlgomaticJpの26歳のAIエンジニア / AIの研究&理論をビジネスの実務・業務に応用する人。/バナー生成AI https://t.co/JsSrKXXRaY / 情報系修士卒
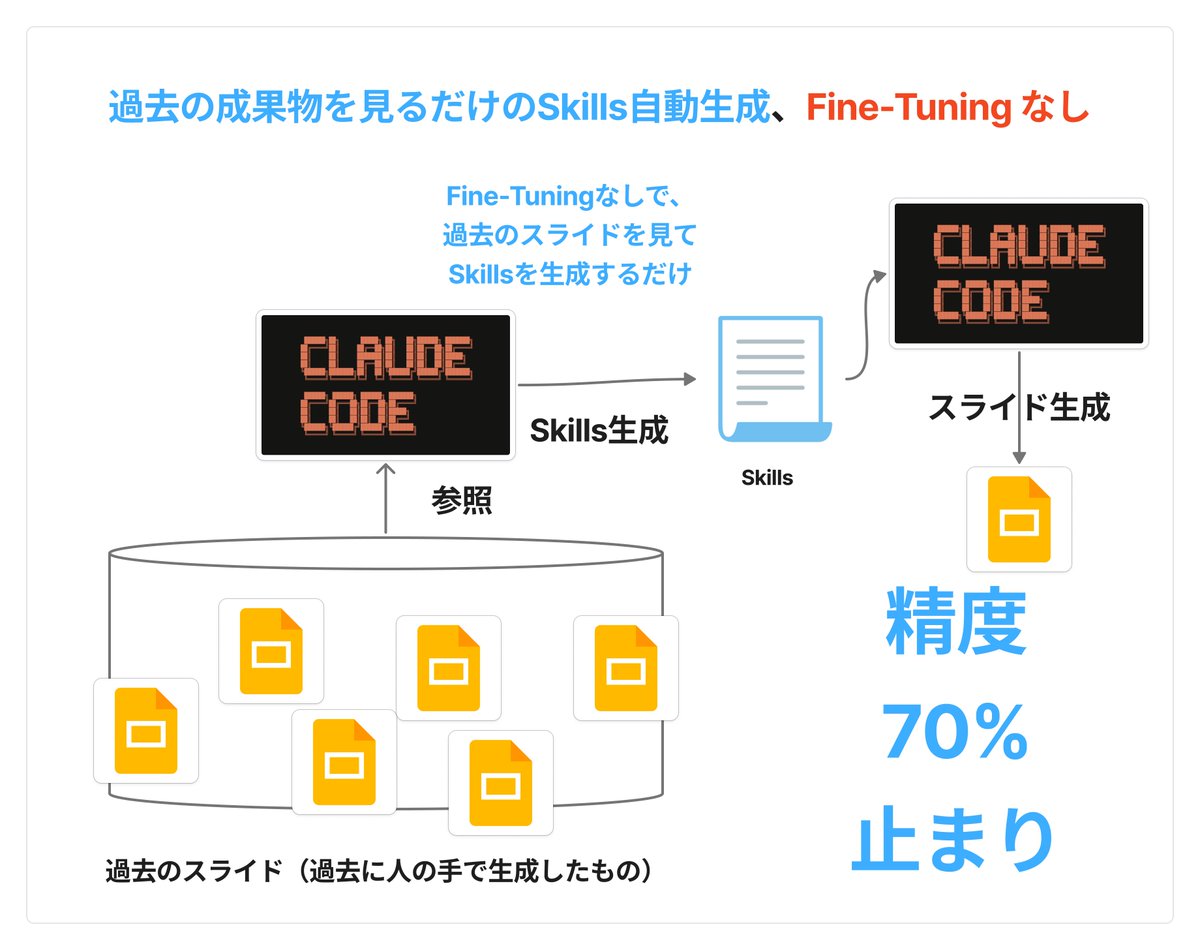
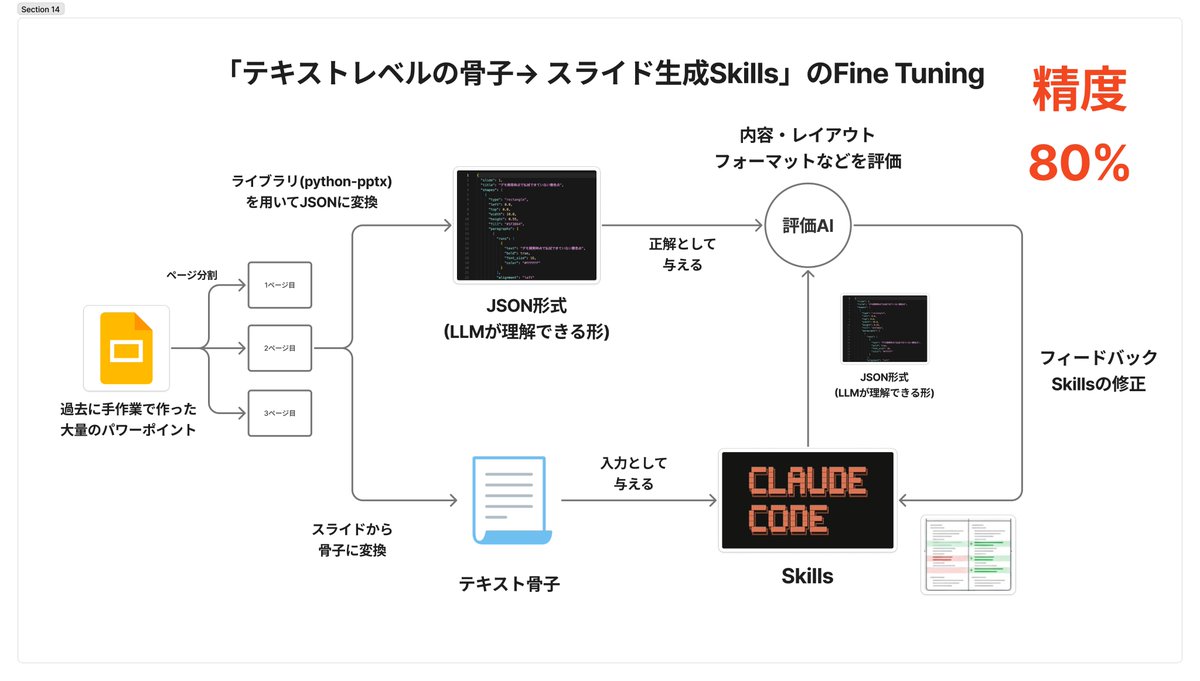


過去に人が作ったスライドを「お手本」として使い、スライド生成のSkillsを自動生成しさらに最適化する実験をしています。 結論、今回の実験ではバリデーションスコアが約20ポイント改善し、"実務である程度"使えるパワポスライドに近づいた、かもしれません。 以前までの方法では、課題が一つありました。それは、「イテレーションごとのSkillsの更新量が大きすぎて、Skillsが学習途中で、前回学んだことを忘れてしまい、Skillsが崩壊してしまうこと」でした。 以前までの手法は、 ①Skillsをまずは適当に生成 ②実際にそのSkillsを実行 ③②の成果物と実際に人が過去に生成した正解例を比較して差分を検出 ④③の差分を比較してSkillsを更新 以上の繰り返し。 前回までは、④において、Skillsを大幅に更新してしまい、前回までに学習したことをほとんど忘れてしまう、という問題がありました。 今回は学習中に、「Skillsの更新幅」を調整することで”Skillsの崩壊”を防ぐ工夫をしました。 具体的には、学習の最初の方はSkillsの更新幅を大きくし、最後の方は小さくしました。そうすることで、最初は大きく学び、最後は小さく精密に学びます。3枚めの画像にあるように、最初は大きく、最後は緻密に学習していることがわかります。 具体的には、最初はレイアウトレベルなどの大きな差分、最後の方はフォントレベルなどの細かな差分の学習をしています。 実際に生成されたものが画像の1,2枚目です。 私が目指しているのは、ビジネスの現場で実際に使えるものです。映える派手なスライドを1枚作ることではなく、提案書・報告書・会議資料といった「地味だけど大量にある」スライドを、安定した品質で生成できること。 フォントは Noto Sans JP、色はコーポレートカラーに沿って、表は枠線がきちんと揃って、レイアウトは崩れない——そういう「当たり前の品質」を自動で達成することが目標です。 今後はよりデータセットを大きくし、生成の精度をより上げていきます。 個人的に、この"Skillsを過去の資産で最適化する方法"はSkills Tuningと呼んでいます。 (一枚目の画像は全部仮想のプレゼンの内容で作成し、学習データに含まれていない内容、で作っています。学習されるべきでない情報は全て実験前にマスクしています。)



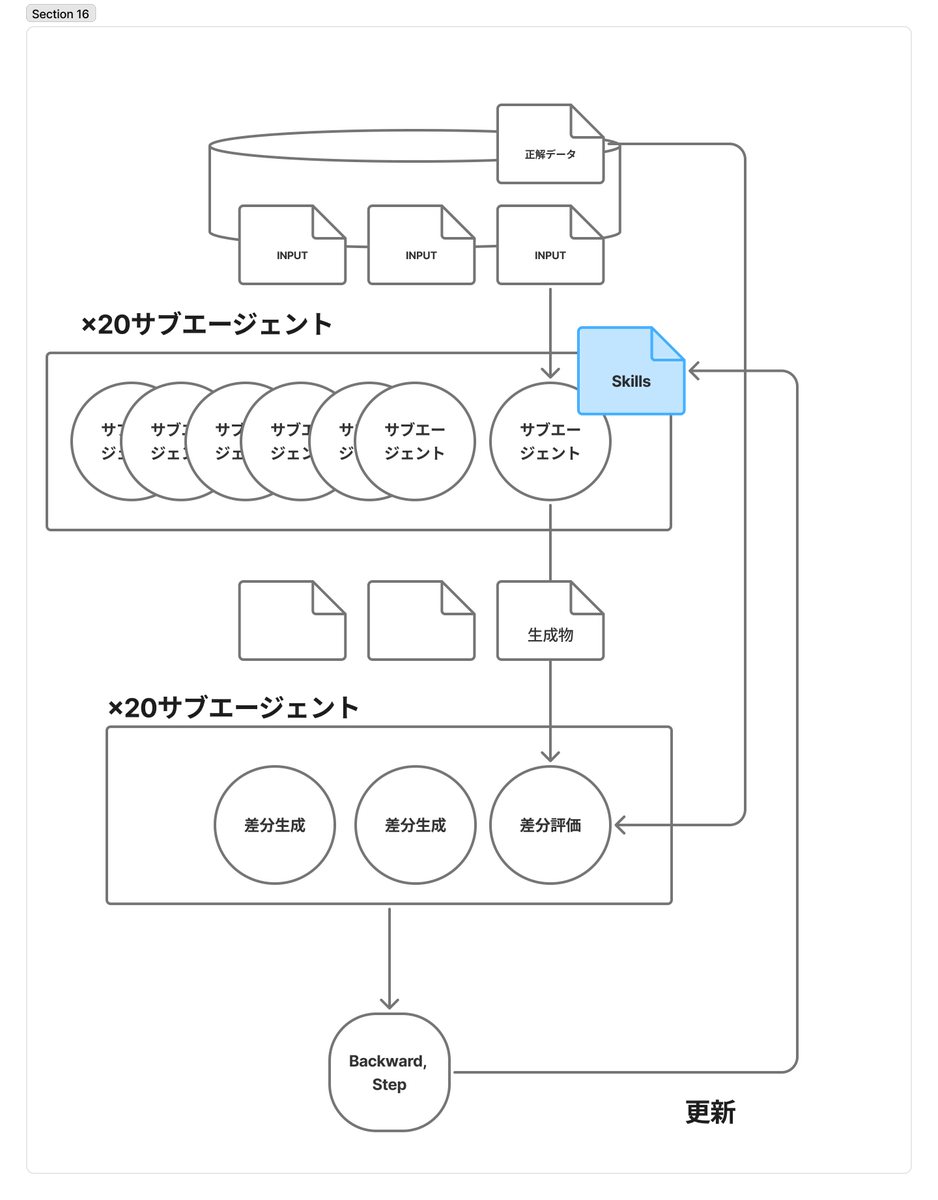
過去のスライドをデータセットにして、テキスト骨子からパワポスライドを生成するSkillsをClaude Codeで自動で最適化する実験をしていました。 今回かなりはっきり見えたのは、スキルは、コンテキストを分離したサブエージェントを一度に大量に並列で動かしながら学習・最適化させるほうが本質的だということです。 今回の実験では、過去のGoogleスライドを1枚ずつ分解してJSON化し、そこから骨子テキストを逆算してデータセットを作成。 その上で、生成と評価を何イテレーションか回して、スライド生成Skillsがどこまで改善するかを見ました。 結果として、スコア自体も改善しました。 train 56.7 → 73.3 val 59.4 → 76.3 ただ、今回の収穫は単なる点数の伸びよりも、どうやってこの改善をもっと大きく回せるかの方向性が見えたことです。 特に重要だったのは、1つの大きなコンテキスト、親エージェントで全部処理するのではなく、 スライドのページごとにコンテキストを分離して、サブエージェントに独立してスライドを生成させること。 さらに、その生成結果をまた別のサブエージェント群で並列評価することで、かなり素直にスケールしそうだと見えてきました。 つまり、 20ページのスライドなら、20個のサブエージェントで同時生成する 評価も20ページ分を並列で走らせる その結果をもとにスキルを更新する これを数十回、数百ケース、将来的には数百枚・数千枚規模で回していく という形です。 このやり方の良さは、答えが見れてしまうようなチートをせずに、ちゃんとタスクごとの独立性、コンテキストの分離を保ったまま学習ループを作れることだと思っています。 例えば親エージェントに全てやらせてしまうと、コンテキストが漏れてしまい、正解データを見て、スライドを生成してしまう可能性がある。 今回の実験を通じて、大量に並列で学習させる仕組みを作ることの方が重要だとかなり実感しました。 おそらく実務では、1回うまく作れたスキルより、データが増えるたびに更新され、評価され、また改善されるスキルの方が価値が大きい。 今回見えたのは、そのための最小構成が少し見えてきた、という感覚です。 次はこの仕組みを、20枚ではなく、100枚、1000枚といった規模で回したときにどう振る舞うかを見ていきたいです。

過去のスライドをデータセットにして、テキスト骨子からパワポスライドを生成するSkillsをClaude Codeで自動で最適化する実験をしていました。 今回かなりはっきり見えたのは、スキルは、コンテキストを分離したサブエージェントを一度に大量に並列で動かしながら学習・最適化させるほうが本質的だということです。 今回の実験では、過去のGoogleスライドを1枚ずつ分解してJSON化し、そこから骨子テキストを逆算してデータセットを作成。 その上で、生成と評価を何イテレーションか回して、スライド生成Skillsがどこまで改善するかを見ました。 結果として、スコア自体も改善しました。 train 56.7 → 73.3 val 59.4 → 76.3 ただ、今回の収穫は単なる点数の伸びよりも、どうやってこの改善をもっと大きく回せるかの方向性が見えたことです。 特に重要だったのは、1つの大きなコンテキスト、親エージェントで全部処理するのではなく、 スライドのページごとにコンテキストを分離して、サブエージェントに独立してスライドを生成させること。 さらに、その生成結果をまた別のサブエージェント群で並列評価することで、かなり素直にスケールしそうだと見えてきました。 つまり、 20ページのスライドなら、20個のサブエージェントで同時生成する 評価も20ページ分を並列で走らせる その結果をもとにスキルを更新する これを数十回、数百ケース、将来的には数百枚・数千枚規模で回していく という形です。 このやり方の良さは、答えが見れてしまうようなチートをせずに、ちゃんとタスクごとの独立性、コンテキストの分離を保ったまま学習ループを作れることだと思っています。 例えば親エージェントに全てやらせてしまうと、コンテキストが漏れてしまい、正解データを見て、スライドを生成してしまう可能性がある。 今回の実験を通じて、大量に並列で学習させる仕組みを作ることの方が重要だとかなり実感しました。 おそらく実務では、1回うまく作れたスキルより、データが増えるたびに更新され、評価され、また改善されるスキルの方が価値が大きい。 今回見えたのは、そのための最小構成が少し見えてきた、という感覚です。 次はこの仕組みを、20枚ではなく、100枚、1000枚といった規模で回したときにどう振る舞うかを見ていきたいです。

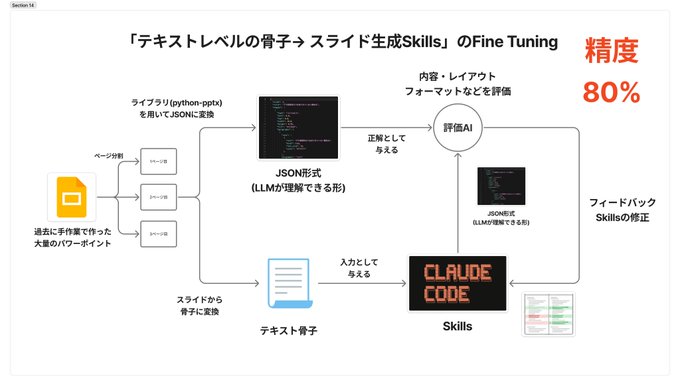
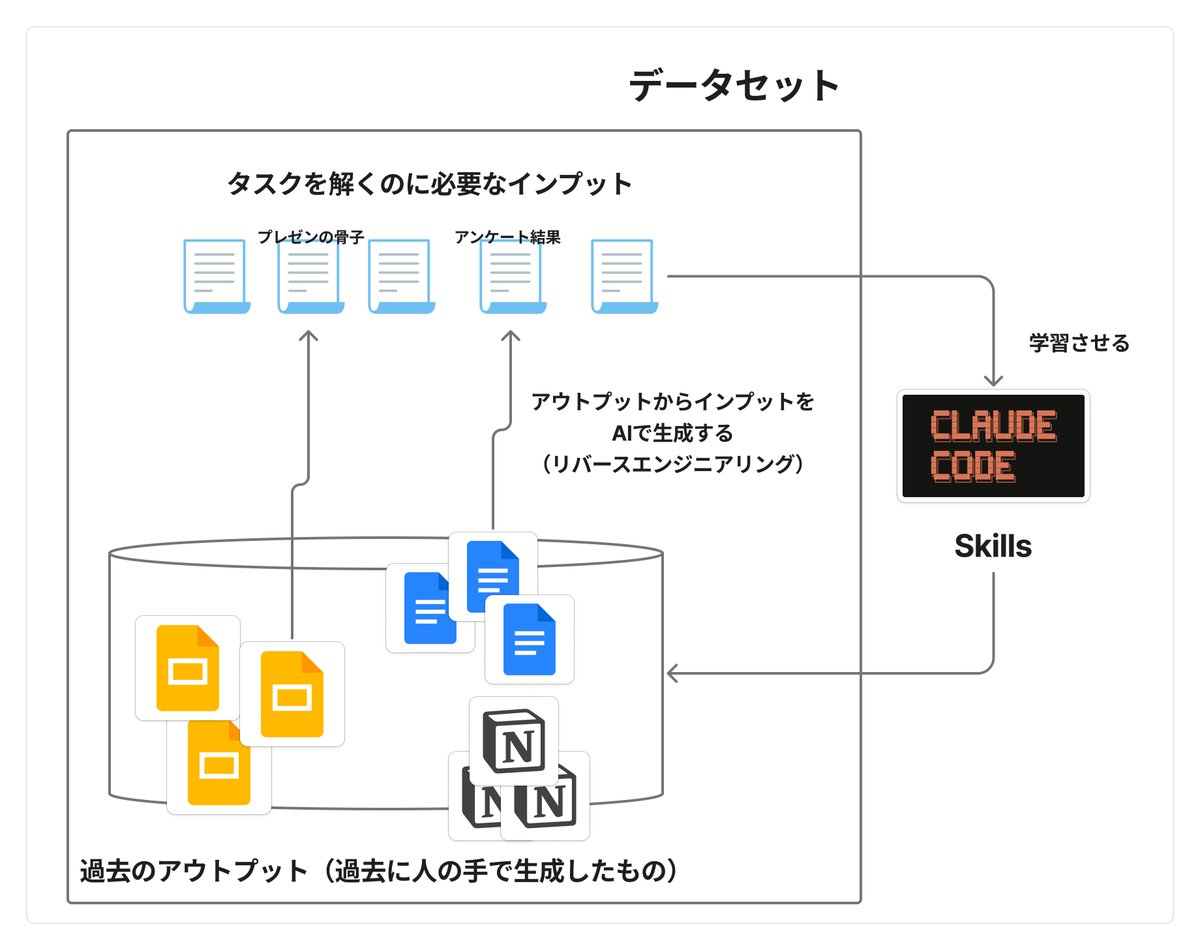
今回の実験でわかったのは、「Skillsを学習させるためのデータセットは大量に自動生成できる可能性がある」ということです。 今回の実験で難しかったのは、Skillsを自動最適化させるためのデータセットを作ることでした。 例えば、過去に人間の生成したスライドはたくさん存在します。 しかしそのスライドを作るのに人が使ったリサーチ結果や、議事録などの、「タスクを遂行するためのインプットとなるデータ」を正確に見つけてくることはとても難しいです。 例えば、パソコンの中に散らばっていたり、もうどこに行ったかわからない資料が大半だと思います。 そこで、スライドやドキュメントなどの成果物から逆算して「どのようなインプットからその成果物が得られそうか」ということをAIで推測させることで、データセットを作れる可能性について考えました。 例えば、パワポのスライドがあるなら、それを作るために作ったであろう、「テキストベースのスライドの骨子」をAIに生成させました。 こうすることでエージェントを自動で学習させることができ、個人の使用用途に沿った暗黙知を吸収したエージェントが量産できるのではないかと考えています。 実際に実験したところ、この方法はある程度有効であることがわかりました。(リポスト元の実験を参照)

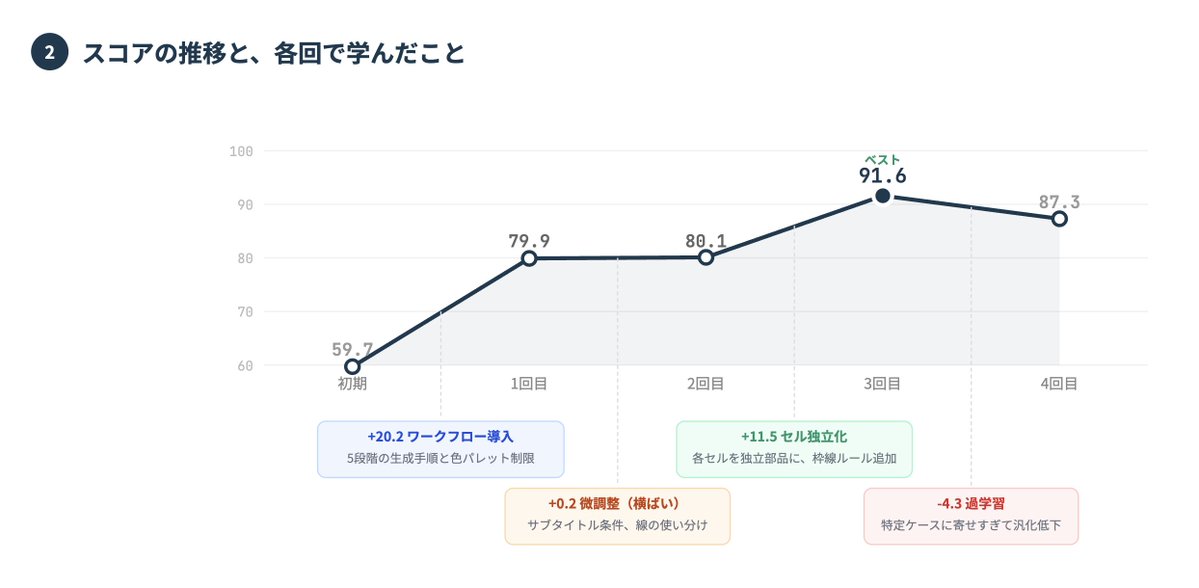
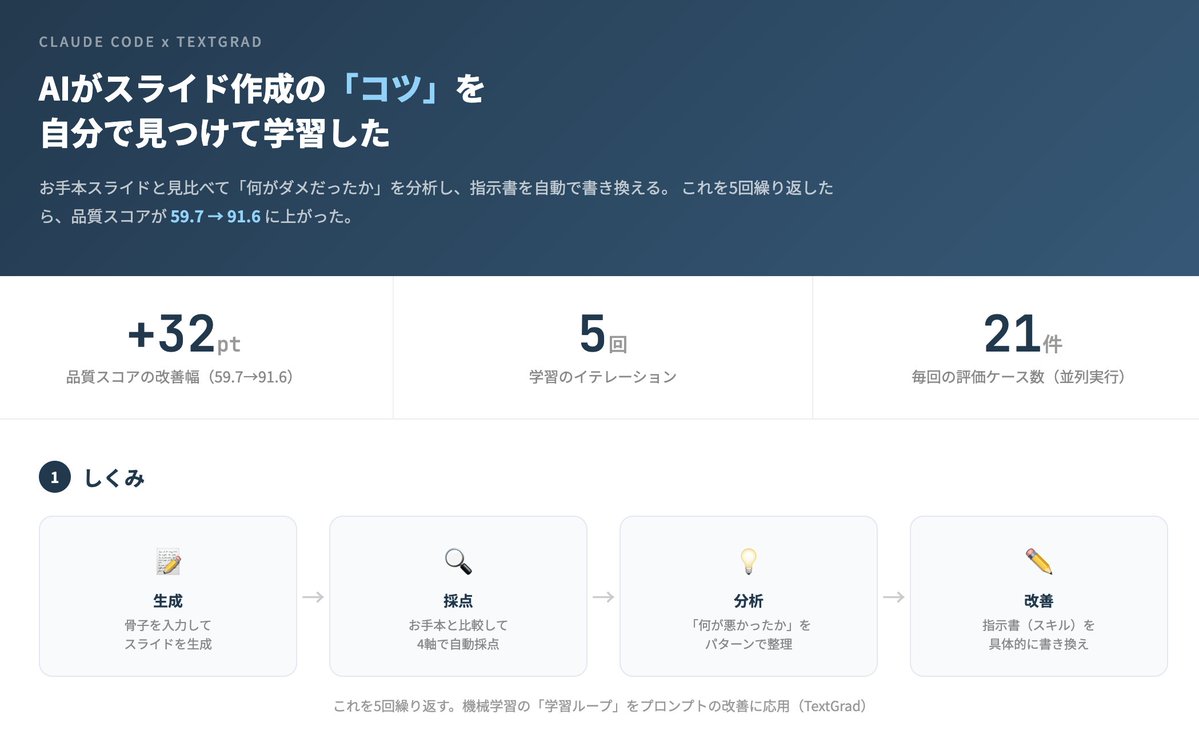
スライド生成のSkillsを「過去のスライドから自力で学習」させる実験をしている。 やりたいことはシンプルで、テキストの骨子を渡したら、過去に作ったスライドと同じテイストで自動生成してほしい。そのためにClaude CodeのSkills(AIへの指示書)を自動で最適化している。 仕組みは機械学習と同じループで、 ①骨子からスライドを生成 → ②お手本と比較して採点 → ③何がダメだったか分析 → ④指示書(Skills)を書き換え、を繰り返す。 前回の実験では2回で改善が頭打ちになった。原因は3つ: 1. 学習データの質が低かった → 本質的に学習に貢献できる質のいいスライドのみを用いて、かつ、データの量を7枚→18枚に増量 2. 採点があいまいだった → 4軸(テキスト/構造/レイアウト/スタイル)でお手本と厳密比較するようにした 3. Skillsの更新が小さすぎた → 毎回のイテレーションでSkillsを大幅に更新するようにオプティマイザーの方を改善した 以上のように改善した結果、今回はスコアが59.7→91.6に改善。前回と違い3回目まで伸び続けた。ただし4回目は87.3に下がり、Skillsでも「学習しすぎ」は起きることがわかった。 一枚目の画像は、学習・テストデータに含まれない未知の入力でスライドを生成したもので、スキルなし/学習1回目/ベストを比較したもの。


過去のスライドを学習させて、テキストの骨子からスライド生成のSkillsを自動生成する小さな実験を試しにやってみた。 結論、ある程度学習が進むことは確認できたものの、 ①Skillsの成果物を評価するAIをタスクに応じて正しく厳密に定義することが大事。 ②評価した結果を正しくSkillsにフィードバックする仕組みが大事。 だということがわかった。 今回の実験でのデータセットの作り方は、 ①手作業で過去に作ったGoogleスライドを一枚ずつに分離、オブジェクトが羅列されたJSONにする ②一枚ずつのスライドについて、Skillsの入力となるテキストでの骨子をAIで生成(リバースエンジニアリングっぽく) ③スライド7枚分を学習データ、3枚分をテストデータにする 学習プロセスは、 ①テキストでのスライドの骨子を入力にしてSkillsを実行 ②スライドを生成(JSON形式) ③自動評価し、テキスト勾配を計算 ④Skillsを修正する 以降繰り返し。 結果は、2ステップまではSkillsの中身も安定して改善したものの、そこから上がりづらくなった。 うまくいかなかった原因として考えられるのは、生成したものを評価する仕組みがあまり良くなかったこと。 スライドのレイアウトや、フォント、フォンントサイズなどを厳密に評価することができていなかった。 かつ、成果物を評価した後にそれをうまくSkillsに反映する仕組みも作ることが大切。Skillsを更新する大きさが大きすぎると、逆にスコアが悪化してしまう。 Claude Codeを使うとこの実験のプロセス全体自体は自動化できるので実験自体の実行はそんなに大変ではないが、トークンを大量に消費する。