
@teortaxesTex @_xjdr This is vibe research. They trained the 3B model for only 0.1 B tokens and the validation loss is > 5.0. Need much more pretraining tokens to draw any conclusions.
English
Yunfan Zhang
50 posts
@z4y5f3
PhD Student in Computer Science/NLP @Columbia | @DukeU '20

DeepSeek Engram: External Memory Claim Debunked — Disguised Regularization Insights from Zhihu Contributor 栀染👇 🔍 Our Research We tested DeepSeek Engram (reasoning-knowledge separation architecture) — its "billion-parameter external N-gram memory table" was hyped as a game-changer for knowledge lookup. Tech insight: a myth. 🧪 Controlled Experiments • Real: Original Engram (trained memory table) • Randomize: Memory = Gaussian white noise (frozen, no updates) • Uniform: All tokens hash to 1 shared vector (no meaningful lookup) • Dense Baseline: Pure Transformer, no Engram branch 😱Shocking Result & Tech Insight Real > Uniform ≈ Randomize >>>>> Dense Baseline Even "garbage memory" (noise/shared vector) CRUSHES the baseline. Engram is just regularization in memory’s clothing — the memory table is a dummy payload, not a real knowledge store. 📊 Scale Validation (3B Model) • Results hold on 3B-scale models: No strong retrieval behavior even on factual prompts. • The advantage persists during training, with pathway dominance (not memory content) becoming more obvious. 🚀Core Tech Takeaway • Gains come fromcontext-aware gating (dynamic feature adjustment) & an extra residual pathway (better gradient flow), NOT memory content. • No complex CPU offload/PCIe optimizations needed — 1 vector/random noise = same performance, GPU memory drops from hundreds of GB to bytes 📚Reproduction & Logs: transparency.chunjiang.dev 🔗Full Response (CN): zhuanlan.zhihu.com/p/202641983237… #LLM #DeepSeek #AI #Tech



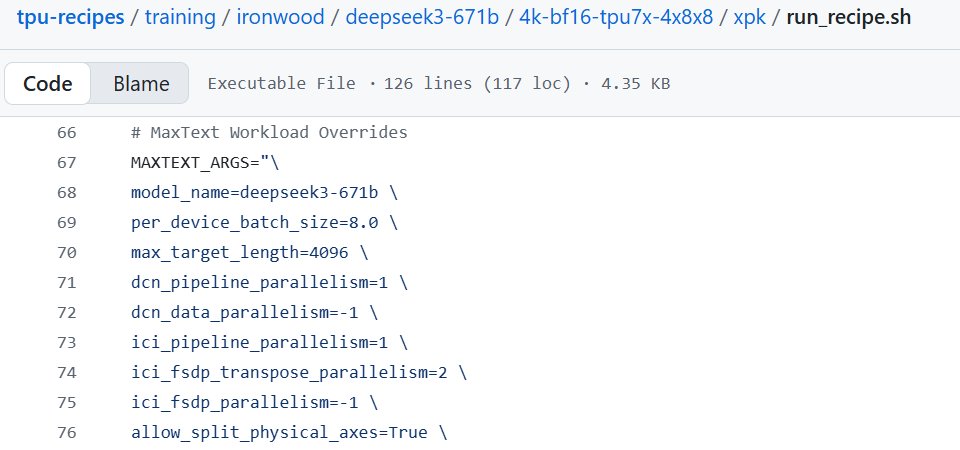
AI chip “top speed” metrics (FLOPS) look great, but real training is limited by memory, data movement, and synchronization bottlenecks. Steve Nouri on linkedIn claims vendor results show Blackwell Ultra up to 1.9× higher training performance per chip vs Ironwood TPU on heavy workloads - largely due to Nvidia’s integrated hardware+interconnect+software stack. NVIDIA still has a moat and they are clearly using it.

My new blog post discusses the physical reality of computation and why this means we will not see AGI or any meaningful superintelligence: timdettmers.com/2025/12/10/why…





deepseek v3.1发布,它明确支持anthropic协议,简单配置环境变量即可使Claude code接入deepseek-3.1 如图所示,这次更新的重点在于模型的编程和工具调用能力。SWE-Bench上的分值比V3和R1都高不少 以下是官方关于接入CC的文档: api-docs.deepseek.com/guides/anthrop… 另外,我让gemini deep research系统调研了kimi-k2/GLM4.5/Qwen3对CC协议的支持情况,如下链接: docs.google.com/document/u/1/d…
🕊️ Lifetime Achievement Award at #ACL2025NLP A standing ovation for Prof. Kathy McKeown, recipient of the ACL 2025 Lifetime Achievement Award! 🌟



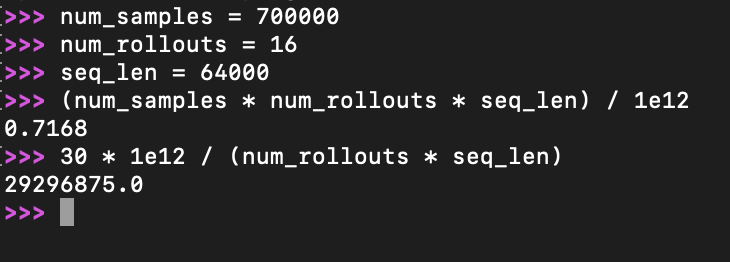
xAI spent the same amount of compute on RL as Pretraining? That is insane
