Sabitlenmiş Tweet
ZackC
15 posts


ZackC
@zackC_EE
Birder/Photographer | EE @ Waterloo | 18
Waterloo, ON Katılım Kasım 2021
25 Takip Edilen13 Takipçiler


man's made it out

anirudh bv@anirudhbv_ce
I implemented @GoogleResearch's TurboQuant as a CUDA-native compression engine on Blackwell B200. 5x KV cache compression on Qwen 2.5-1.5B, near-loseless attention scores, generating live from compressed memory. 5 custom cuTile CUDA kernels ft: - fused attention (with QJL corrections) - online softmax -on-chip cache decompression - pipelined TMA loads Try it out: devtechjr.github.io/turboquant_cut… s/o @blelbach and the cuTile team at @nvidia for lending me Blackwell GPU access :) cc @sundeep @GavinSherry
English

ZackC retweetledi
pip install turboquant-gpu
5.02x KV cache compression for ANY GPU (RTX, H100, A100, B200)
- works over @huggingface transformers
- dead-simple API: compress + generate in 3 lines
- 3-bit Lloyd-Max fused KV compression (0.98 cosine similarity)
- outperforms MXFP4 (3.76x) and NVFP4 (3.56x) on compression
Ran Mistral-7B: 1,408 KB → 275 KB KV cache (5.02x)
Quickstart: github.com/DevTechJr/turb…
Written in cuTile (CUDA 12, 13) with PyTorch fallbacks

English
ZackC retweetledi
I implemented @GoogleResearch's TurboQuant as a CUDA-native compression engine on Blackwell B200.
5x KV cache compression on Qwen 2.5-1.5B, near-loseless attention scores, generating live from compressed memory.
5 custom cuTile CUDA kernels ft:
- fused attention (with QJL corrections)
- online softmax
-on-chip cache decompression
- pipelined TMA loads
Try it out: devtechjr.github.io/turboquant_cut…
s/o @blelbach and the cuTile team at @nvidia for lending me Blackwell GPU access :)
cc @sundeep @GavinSherry
English
No idea what this means but if Anirudh did it, then it must be amazing!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
anirudh bv@anirudhbv_ce
I implemented @GoogleResearch's TurboQuant as a CUDA-native compression engine on Blackwell B200. 5x KV cache compression on Qwen 2.5-1.5B, near-loseless attention scores, generating live from compressed memory. 5 custom cuTile CUDA kernels ft: - fused attention (with QJL corrections) - online softmax -on-chip cache decompression - pipelined TMA loads Try it out: devtechjr.github.io/turboquant_cut… s/o @blelbach and the cuTile team at @nvidia for lending me Blackwell GPU access :) cc @sundeep @GavinSherry
English
@anirudhbv_ce @Matthew_Wu_ shipping from china takes too long unfortunately😓
English
ZackC retweetledi

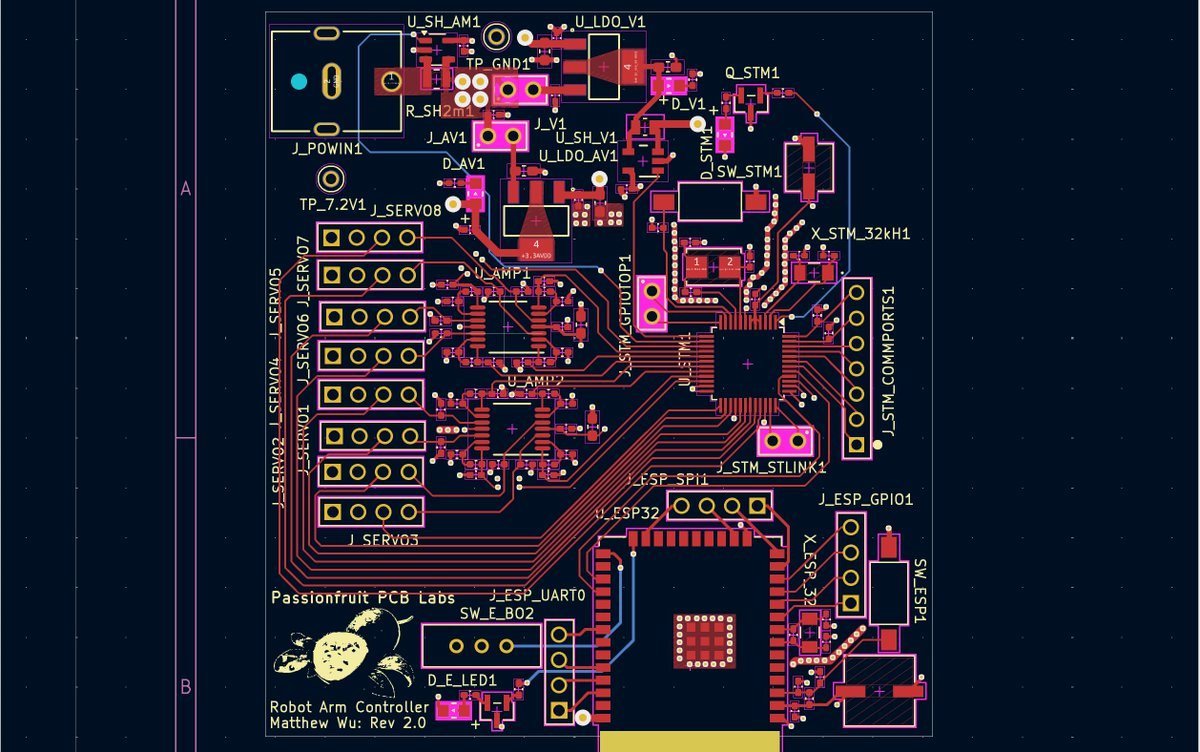
My 6-axis robotic arm controller PCB that I designed back in high school.
The v2 specs:
- 4-layer board, 12A max current
- Dual ESP32 + STM32 integration
- Custom op-amp servo feedback
- Optimized for thermals & signal integrity
- Fully validated
But getting to this point wasn't easy. I learned a lot the hard way.
v1 had major signal integrity issues that forced me to cut traces, add bodge wires, and do a ton of messy rework just to get basic functionality.
But that board forced me to learn:
power distribution, spacing, layout discipline, and hot loop control.
Now that exact stuff is the foundation for the RF + power electronics boards I design at UWaterloo.

English

I can't shake this feeling that there is a bunch ALT accounts following and responding to my posts that don't to include their main accounts in this kind of content. This is not an outlier, ordinarily I would say this is a bot flag, but their input is not bot driven, many of them have legit feedback that is human driven. lots of people use Alt accounts to separate different parts of themselves.
English


I made this layout to test all different sized components and density with the 3D printed stencil to answer all the questions.
In the last test the smallest component was 0805 and it worked perfectly. This next one has everything: QFN, 0201, 0402, 0603, and 0805.

Will@willreil
Yesterday I made the 3d printed stencil generator and many were saying that it wont work for smaller components or on more densely populated boards. I am going to test that today. I believe it could work down to 0201 with a 0.2mm nozzle and hole compensation in the slicer.
English
