Sabitlenmiş Tweet

🚨 New Paper Alert! 🚨
How can we align language models without drowning in prompt engineering or falling into reward hacking traps?
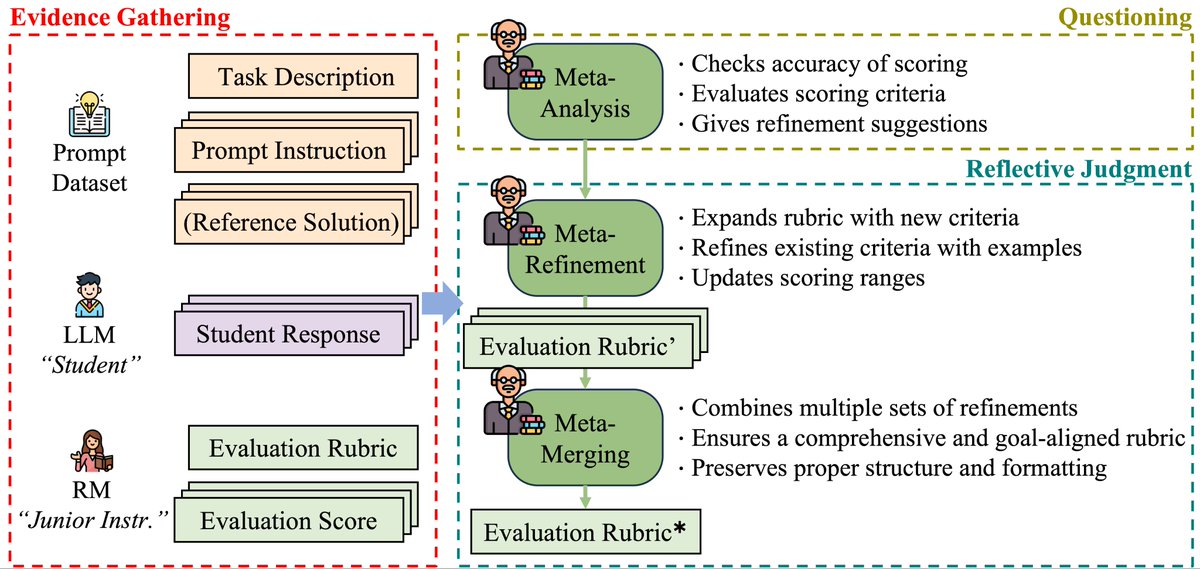
We introduce Meta Policy Optimization (MPO)—a new reinforcement learning framework that evolves its own reward model rubrics through meta-level reflection. Inspired by metacognition and evaluative thinking, MPO trains models to think about how they evaluate, not just what they generate.
🔥 Why it matters:
✔️ Boosts stability and robustness in RLAIF
✔️ Reduces human labor in prompt crafting
✔️ Generalizes across tasks: essays, summarization, ethical and mathematical reasoning
Check it out: huggingface.co/papers/2504.20…
Big thanks to co-authors @chanwoopark20 (MIT), @_vipulraheja (Grammarly), and @dongyeopkang (UMN)!
#AI #LLMs #ReinforcementLearning #MetaLearning #NLP #Alignment #RLHF #RLAIF #EvaluativeThinking #PromptEngineering


English