Sabitlenmiş Tweet

Some futurists think everything is a nail awaiting a pounding from a GenAI hammer
I personally don’t believe in universal wish granting technology
English
Andy Zmolek 🇬🇧 London
9.4K posts

@zmolek
Conjurer of Ouroboros dilemma, Phracta founder Chronicler of enterprise mobility ecosystem legend; it’s trust chains and narrative loops all the way down, folks
Police in Columbus Ohio mess up bad when they arrested a real ATF agent. This one of those videos that really make local PD look bad. The first officer arrived on the scene and immediately drew his firearm and started demanding the ATF officer to get on the ground. Never gave him a chance to show his credentials, treated him like a criminal with zero chance to prove his innocence. clearly in the video it is seen he had his hands up with his paperwork in his hand. There was no need to demand on the ground and not give him a chance to identify himself. They arrested him, put him in the back of a squad car and continued to mock him until they made contact with his supervisor. This ended in a huge lawsuit that cost the tax payers of Columbus 1.6 million dollars over two incompetent cops that believe or not as of 2025 are still on the force doing God knows what other damage.

If you give Opus 4.7 a discombobulating riddle it gets that it can't answer it but also completely fails to count the letters in specific words correctly





Share a story that sounds fabricated but is 100% true.











Mythos Preview has already found thousands of high-severity vulnerabilities—including some in every major operating system and web browser.
so... I audited Garry's website after he bragged about 37K LOC/day and a 72-day shipping streak. here's what 78,400 lines of AI slop code actually looks like in production. a single homepage load of garryslist.org downloads 6.42 MB across 169 requests. for a newsletter-blog-thingy. 1/9🧵

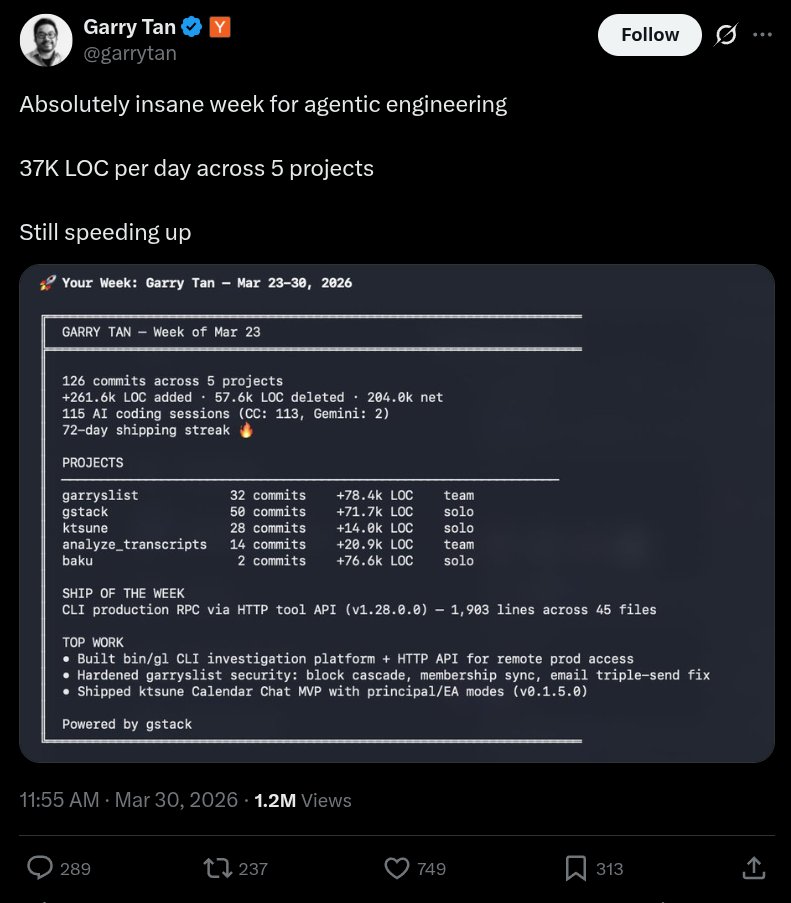
Absolutely insane week for agentic engineering 37K LOC per day across 5 projects Still speeding up


This is a real thing that happened




Atoms. atoms.co/vision

