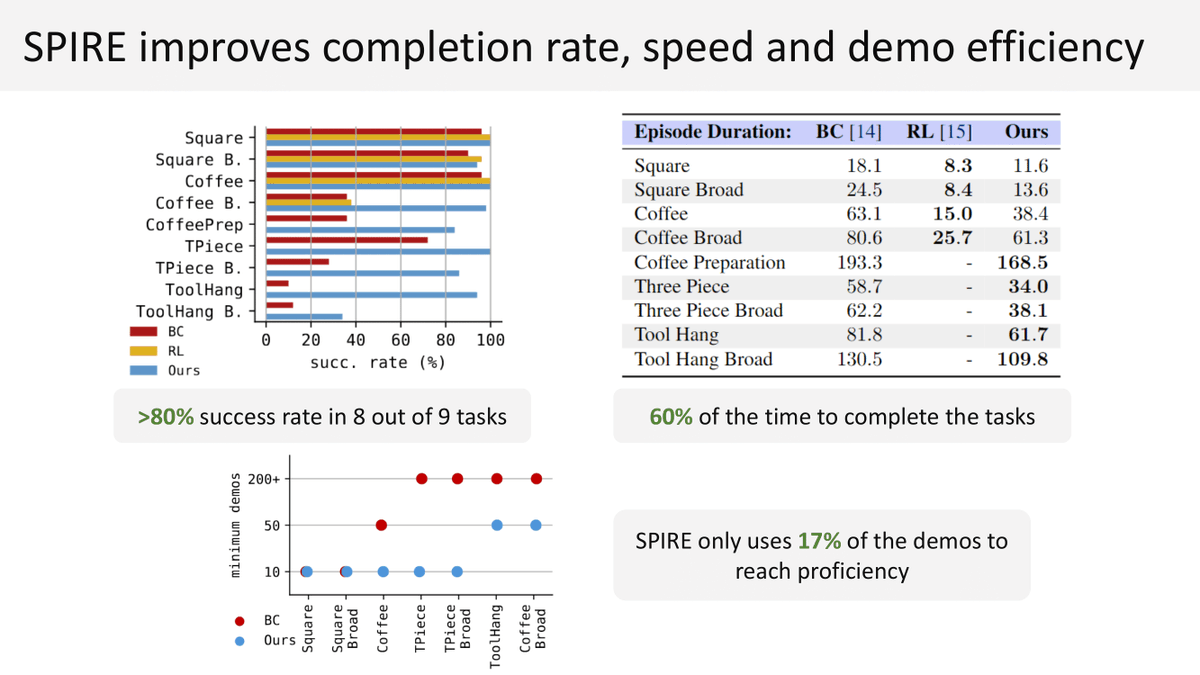
SPIRE agents reach an 80% success rate in 8 out of 9 challenging long-horizon tasks while only using 60% of the time needed by BC agents to finish the task. SPIRE achieves the same level of proficiency as alternatives using only 17% of the demonstrations.
🧵 8/
One common issue with using RL-based finetuning is that new behavior does not preserve safety considerations implicit in the human teleoperation data. In contrast, our RL finetuning scheme allows SPIRE agents to preserve human behavior, allowing for safe deployments.
🧵 6/
With RL fine-tuning, SPIRE massively improves both the success rate and task completion speed over a naive BC agent, allowing us to train superior policies with as few as 10 demos.
🧵 5/
SPIRE trains a residual policy with RL to fine-tune the BC policy. A KL penalty term prevents it from deviating from the BC policy. This allows for structured exploration and use of sparse task completion rewards - no more painful reward tuning!
🧵 4/
Want your robot to make a cup of coffee but don’t want to spend hours collecting demos?
We introduce SPIRE, a system that solves long-horizon manipulation tasks with limited demos through planning, Behavior Cloning, and Reinforcement Learning.
#CoRL2024#NVIDIAResearch 👇
🧵 1/
SPIRE decomposes long-horizon tasks into shorter subtasks using task and motion planning. Challenging subtasks not solvable by planning are deferred to a human teleoperator. Then, it trains behavior cloning policies with the collected data and fine-tunes them with RL.
🧵 2/
Exploration in complex environments has always been a major challenge in RL, especially in procedurally-generated environments where state-oriented methods can be ineffective. In our ICLR 2023 submission, we propose to explore the concept of achievements as a solution. (1/n)