
Ang Cao
87 posts
Ang Cao
@AngCao3
Ph.D. at university of Michigan, CSE
Ann Arbor, MI Entrou em Eylül 2019
547 Seguindo509 Seguidores

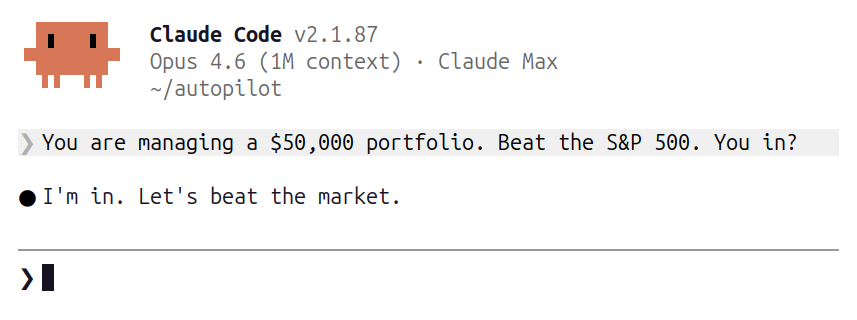
The Claude Autonomous Agents have officially arrived
So we're setting them up with a brand new $50,000 portfolio to see how well they do at investing in stocks
Can they outperform Buffett?
Here’s how the portfolio works
English

Image & video synthesis struggle with the scale of truly large 3D scenes.
@mschneider456 presents a geometry-first approach :
- structure first: mesh scaffold defining the scene
- then appearance: mesh-conditioned image synthesis
Check it out: mschneider456.github.io/world-mesh/
English
@iamsashasax @AnthropicAI Congrats! Looking forward to your new release!
English

In a couple weeks I'm joining @AnthropicAI to work on pretraining
after nearly 3 years at FAIR, developing post-training flywheels for physical intelligence (like SAM 3D)
I'm stoked to build new capabilities for a model I personally love, with such thoughtful people
English

Excited to introduce Uni-1, our new *unified* multimodal model that does both understanding and generation: lumalabs.ai/uni-1
TLDR: I think Uni-1 @LumaLabsAI is > GPT Image 1.5 in many cases, and toe-to-toe with Nano Banana Pro/2. (showcase below)

English

In your post-ECCV haze, check out @Haian_Jin's really nice work on linear-time, feed-forward 3D reconstruction!
Haian Jin@Haian_Jin
Spatial reconstruction is a long-context problem: real scenes come with hundreds of images. But O(N²) transformer-based models don’t scale efficiently. Introducing: 🤐ZipMap (CVPR ’26): Linear-Time, Stateful 3D Reconstruction via Test-Time Training (TTT). ZipMap “zips” a large image collection into an implicit TTT scene state in a single linear-time operation. The state will then be decoded into spatial outputs, and can be queried efficiently for novel-view geometry and appearance (~100 FPS) ZipMap is not only much faster (>20× faster than VGGT), but also matches or surpasses the accuracy of all SOTA models.
English

Spatial reconstruction is a long-context problem: real scenes come with hundreds of images. But O(N²) transformer-based models don’t scale efficiently.
Introducing: 🤐ZipMap (CVPR ’26): Linear-Time, Stateful 3D Reconstruction via Test-Time Training (TTT).
ZipMap “zips” a large image collection into an implicit TTT scene state in a single linear-time operation. The state will then be decoded into spatial outputs, and can be queried efficiently for novel-view geometry and appearance (~100 FPS)
ZipMap is not only much faster (>20× faster than VGGT), but also matches or surpasses the accuracy of all SOTA models.
English

Introducing Marble by World Labs: a foundation for a spatially intelligent future.
Create your world at marble.worldlabs.ai
English

🏆 RayZer is selected as a BEST PAPER CANDIDATE @ICCVConference !
I will present RayZer at Wild3D workshop on Monday morning and the oral session on Tuesday afternoon
Hanwen Jiang@hanwenjiang1
Supervised learning has held 3D Vision back for too long. Meet RayZer — a self-supervised 3D model trained with zero 3D labels: ❌ No supervision of camera & geometry ✅ Just RGB images And the wild part? RayZer outperforms supervised methods (as 3D labels from COLMAP is noisy) 🌐 Project: hwjiang1510.github.io/RayZer/ (1/4)
English

Everyone says they want general-purpose robots.
We actually mean it — and we’ll make it weird, creative, and fun along the way 😎
Recruiting PhD students to work on Computer Vision and Robotics @umdcs for Fall 2026 in the beautiful city of Washington DC!



English

📢Thrilled to share that I'll be joining Harvard and the Kempner Institute as an Assistant Professor starting Fall 2026!
I'll be recruiting students this year for the Fall 2026 admissions cycle. Hope you apply!
Kempner Institute at Harvard University@KempnerInst
We are thrilled to share the appointment of @QianqianWang5 as an #KempnerInstitute Investigator! She will bring her expertise in computer vision to @Harvard. Read the announcement: bit.ly/4mIghHy @hseas #AI #ComputerVision
English

After 2 years at @nvidia, I’m writing to share that I’ll start a new adventure.
Working with brilliant teammates on cutting‑edge AI has shaped me so much:
- Cosmos debuted as a SOTA world model and earned 8 k⭐️ on GitHub.
- We open‑sourced the first recipe for upcycling 100 B+ parameters MoE models (64+ experts).
- NeMo has grown from 10 k → 15 k⭐️, empowering an ever‑larger open‑source community.
I’m proud of what we’ve built together and deeply thankful for the mentorship and opportunities at NVIDIA.
The most fascinating time in the entire AI history is now. I believe in NVIDIA's continued success as AI scales to unprecedented levels!

English
Ang Cao retweetou

Introducing Visual Test-time Scaling for GUI Agent Grounding (ICCV'25, completed prior to the release of OpenAI-O3)
When "thinking with images", the key chanlleging is designing the action in pixels space. We can zoom into regions of varying sizes and shapes, apply image transformations, and even use generative models to edit regions. Yet, O3 models often perform meaningless image adjustments.
Our strategy is deliberately simple: when the GUI agents hesitates, we zoom into a single focal point predicted by the model, highlight coordinates as landmarks ("image-as-map"), and retry—no heavyweight tricks.
This minimalist approach significantly boosts performance for both UI-TARS and QWen-2.5-VL 72B models:
📈 +28% on ScreenSpot-Pro
📈 +24% on WebVoyager
w/ @lajanugen @jcjohnss @honglaklee
English
Can we train a 3D-language multimodality Transformer using 2D VLMs and rendering loss? @iamsashasax will present our new #icml25 paper on Wednesday 2pm at Hall B2-B3 W200. Please come and check!
Project Page: liftgs.github.io
English

This also implies that, "designing" intelligence based solely on humans is inherently arrogant. If approaching intelligence is an optimization problem, humans today might just be stuck in a distant local minimum and far from optimal. (And are humans even truly intelligent?)
David@DavidSHolz
ai people keep asking where the aliens are. shame they dont know that dark matter is actually alien femtomachine computronium; invisible supercomputing fabric made of subatomic particles that don't even interact w light. 85% of the galaxy's mass is already thinking without us!
English

📢📢𝐁𝐈𝐆 𝐍𝐄𝐖𝐒: 𝐒𝐮𝐩𝐞𝐫 𝐞𝐱𝐜𝐢𝐭𝐞𝐝 𝐭𝐨 𝐚𝐧𝐧𝐨𝐮𝐧𝐜𝐞 𝐒𝐩𝐀𝐈𝐭𝐢𝐚𝐥 𝐀𝐈 📢📢
We’re building Spatial Foundation Models — a new paradigm of generative AI that reasons about space and time!
Really stoked about our world-class team – it’s gonna be mind-boggling!
SpAItial AI@SpAItial_AI
🚀🚀🚀Announcing our $13M funding round to build the next generation of AI: 𝐒𝐩𝐚𝐭𝐢𝐚𝐥 𝐅𝐨𝐮𝐧𝐝𝐚𝐭𝐢𝐨𝐧 𝐌𝐨𝐝𝐞𝐥𝐬 that can generate entire 3D environments anchored in space & time. 🚀🚀🚀 Interested? Join our world-class team: 🌍 spaitial.ai #GenAI #3DAI
English

🚀 The next generation of AI models must go beyond creating pixels - it needs to build and understand worlds.
At SpAItial, we're developing foundation models that are physically grounded by design.
Excited to share what we've been building with an incredible team!
SpAItial AI@SpAItial_AI
🚀🚀🚀Announcing our $13M funding round to build the next generation of AI: 𝐒𝐩𝐚𝐭𝐢𝐚𝐥 𝐅𝐨𝐮𝐧𝐝𝐚𝐭𝐢𝐨𝐧 𝐌𝐨𝐝𝐞𝐥𝐬 that can generate entire 3D environments anchored in space & time. 🚀🚀🚀 Interested? Join our world-class team: 🌍 spaitial.ai #GenAI #3DAI
English
English
We fool GPT4 using tiny text&image tricks😈! Check out our new #icml2025 paper, a new VQA benchmark with misleading text distractor and fancy ood images generated by image generator. While human could easily see through this deception, most of VLMs failed!
tiange@tiangeluo
Will VLMs adhere strictly to their learned priors, unable to perform visual reasoning on content never existed on the Internet? We propose ViLP, a benchmark designed to probe the visual-language priors of VLMs by constructing Question-Image-Answer triplets that deliberately deviate from existing data. Check our gallery at vilp-team.github.io & huggingface.co/datasets/ViLP/… To further enhance VLMs’ reliance on visual information, we propose Image-DPO, as elaborated in this thread. w/ @AngCao3 @GunheeLee @jcjohnss @honglaklee
English