Tweet fixado

My current setup :
From 9 -> 5 => Lenovo Thinkpad E16
From 5 -> 9 => HP OMEN (2016)
Switching between them with my favorite tech gadget (2025) a one button KVM switch

English
Chahid Chirchi
8.1K posts

@CChirchi
Vibe coding apps to quit my 9-5. Building in public.


Be this guy > Spend 7 months developing a micro SAAS > Realize you have 0 users and you are building for nobody > Pause development and focus 100% on marketing > Week 1 you make $1,900 MRR Stop over engineering Commit yourself fully to marketing.

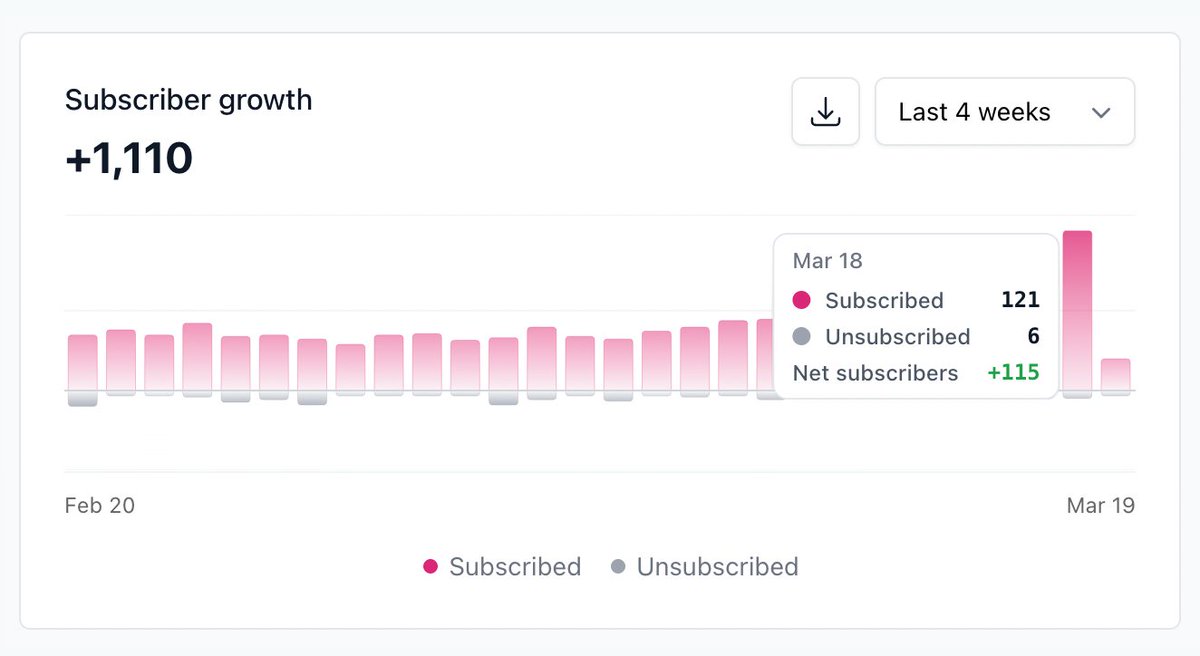
New growth record for @shortcutdotnews yesterday 84 new subscribers in a single day 🤙

Apple has quietly halted App Store updates for popular AI "vibe-coding" applications most notably the $9 billion startup Replit and mobile app builder Vibecode. After months of pushback, Apple is reportedly demanding major UX changes. Replit is being asked to force its generated app previews to open in an external web browser rather than natively inside its app. Vibecode was told it must completely remove the ability to generate software specifically for Apple devices.



JUST IN: DoorDash rolls out new app that pays people to film themselves doing chores for AI training data.

Letting Claude Cowork take care of setting up Meta ads for me this time.

We tried something. It didn’t work. And we took those learnings and decided to reward Articles instead of single posts. Articles have grown 20x since December and they are now the largest blogging product on the internet by traffic. In consumer product development, you sometimes take non-linear paths to discover opportunity.

Composer 2 is now available in Cursor.

Introducing Lovable for more general tasks. Lovable has always been for building apps. Today it also becomes your data scientist, your business analyst, your deck builder, and your marketing assistant. This is a big step toward what Lovable is becoming: a general-purpose co-founder that can do anything. See examples below.


Google Search referrals to the web have plummeted, AI links are 'less than 1%' of traffic 9to5google.com/2026/03/18/goo… by @nexusben



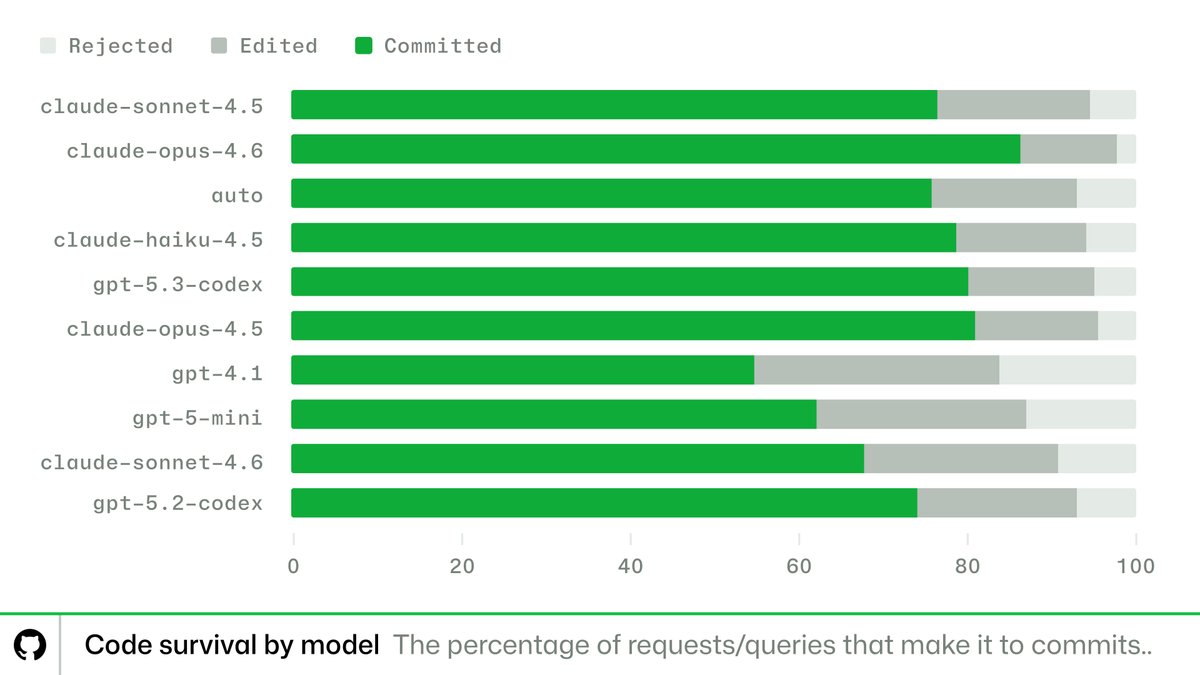

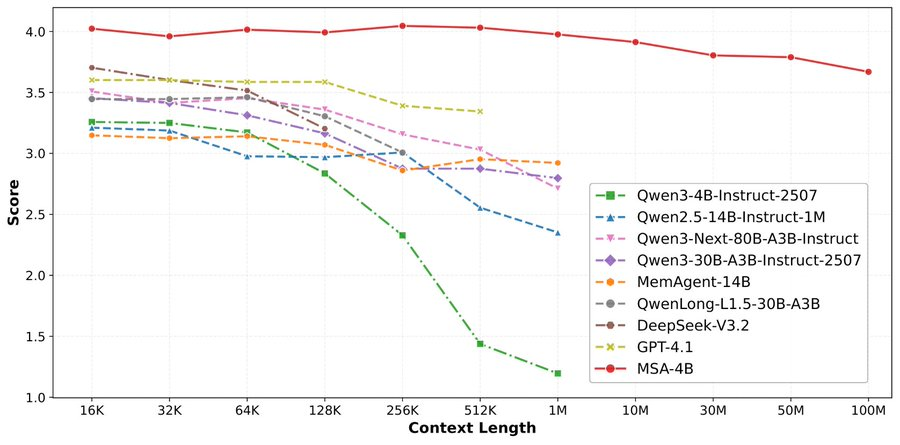
论文来了。名字叫 MSA,Memory Sparse Attention。 一句话说清楚它是什么: 让大模型原生拥有超长记忆。不是外挂检索,不是暴力扩窗口,而是把「记忆」直接长进了注意力机制里,端到端训练。 过去的方案为什么不行? RAG 的本质是「开卷考试」。模型自己不记东西,全靠现场翻笔记。翻得准不准要看检索质量,翻得快不快要看数据量。一旦信息分散在几十份文档里、需要跨文档推理,就抓瞎了。 线性注意力和 KV 缓存的本质是「压缩记忆」。记是记了,但越压越糊,长了就丢。 MSA 的思路完全不同: → 不压缩,不外挂,而是让模型学会「挑重点看」 核心是一种可扩展的稀疏注意力架构,复杂度是线性的。记忆量翻 10 倍,计算成本不会指数爆炸。 → 模型知道「这段记忆来自哪、什么时候的」 用了一种叫 document-wise RoPE 的位置编码,让模型天然理解文档边界和时间顺序。 → 碎片化的信息也能串起来推理 Memory Interleaving 机制,让模型能在散落各处的记忆片段之间做多跳推理。不是只找到一条相关记录,而是把线索串成链。 结果呢? · 从 16K 扩到 1 亿 token,精度衰减不到 9% · 4B 参数的 MSA 模型,在长上下文 benchmark 上打赢 235B 级别的顶级 RAG 系统 · 2 张 A800 就能跑 1 亿 token 推理。这不是实验室专属,这是创业公司买得起的成本。 说白了,以前的大模型是一个极度聪明但只有金鱼记忆的天才。MSA 想做的事情是,让它真正「记住」。 我们放 github 上了,算法的同学不容易,可以点颗星星支持一下。🌟👀🙏 github.com/EverMind-AI/MSA



