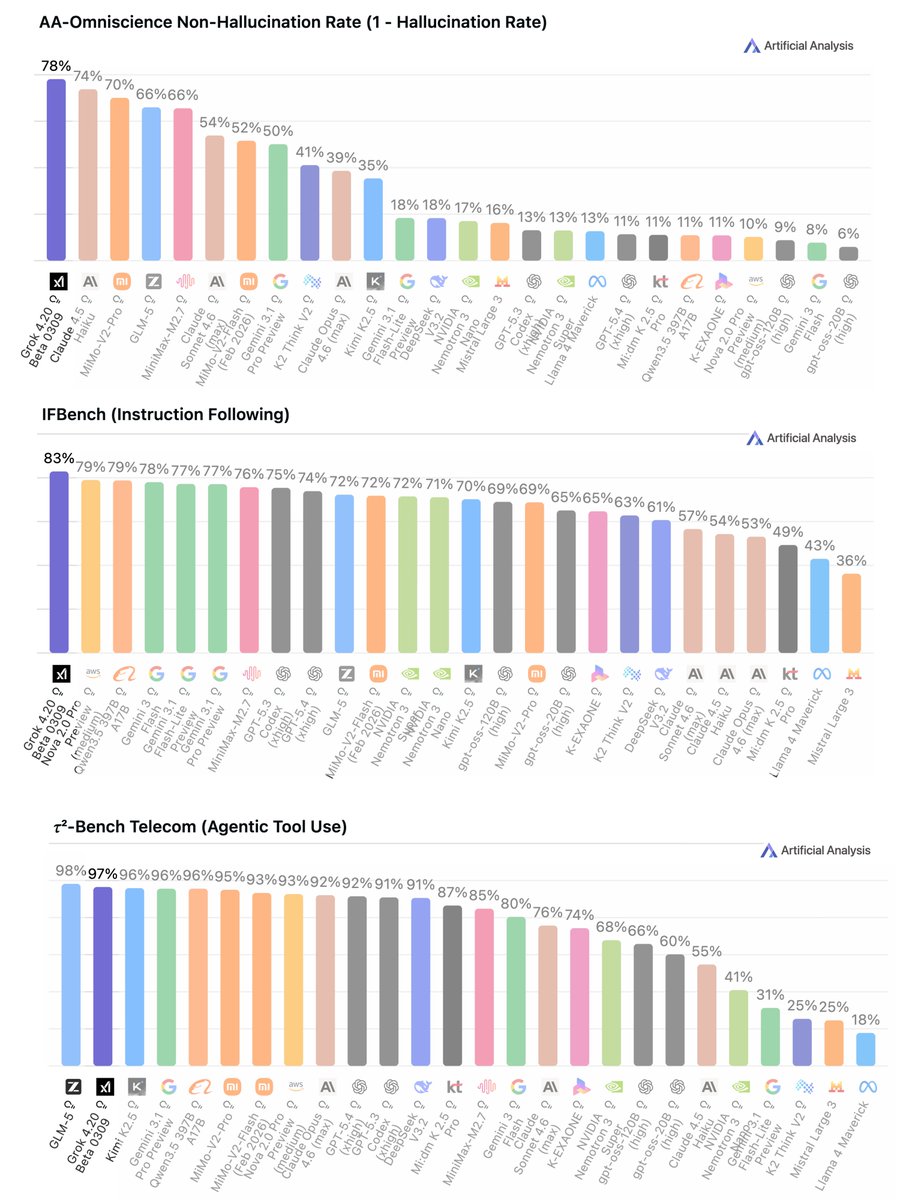

Grok 4.20 introduces multi-Agent and the results are impressive.
• Faster than a single agent
• More accurate than running 4 separate agents
This is coordinated parallelism, not just scaling copies.
Multi-agent systems are becoming the new standard for performance.
English