
none your kind
348 posts


@RoundtableSpace Meta Avocado? That's the only one I'm actually waiting for. Are we sure it's not just a rumor about how many GPUs the industry eats?
Honestly, with that many launches, isn't the real bottleneck just keeping up with the hype cycle?
English

HERE’S A LIST OF ALL AI MODELS RUMORED TO BE DROPPING IN APRIL:
- DeepSeek V4
- GPT-5.5
- Gemini 3.1 Flash
- Kimi K3
- Minimax M3
- Gemma 4
- Hunyuan 3.0
- Gemini 3.1 Pro
- Claude Sonnet 4.7
- Claude Haiku 4.6
- Meta Avocado
It’s going to be a crazy month.
English

@ReelJustinLewis Stalin felt humans were expendable, the US felt machines were more expendable.
English

@scaling01 Yes it fairly penalizes stochastic parrots from real intelligence
English

The Scoring of ARC-AGI-3 doesn't tell you how many levels the models completed but how efficiently they completed them compared to humans
actually using squared efficiency
meaning if a human took 10 steps to solve it and the model 100 steps then the model gets a score of 1%
((10/100)^2)
so ARC-AGI-1/2 and ARC-AGI-3 scores are not comparable

English

What is the point of hotel check-in desk people anymore?
Why isn't this 100% automated?
Verify your ID, pay, get entry code.
Why are humans still doing this?
English
@scaling01 “Silly puzzle V3” will be benchmaxed in 6 mos, then we will get Silly Puzzle V4.
ARC is the worlds dumbest benchmark
English
ARC-AGI-3 scores for GPT-5.4, Gemini 3.1 Pro and Opus 4.6
Gemini 3.1 Pro: 0.37%
GPT-5.4: 0.26%
Opus 4.6: 0.25%
Grok 4.2: 0%

Indonesia
@Aaronontheweb I tell it no faggy fallbacks and that tends to help.
Byproduct of benchmaxing
English

One of the most insidious tics LLMs have when coding is this obsession with adding "fallback" behaviors everywhere
These are extremely toxic because they hide real bugs and most importantly, introduce lots of potential privilege escalation vulnerabilities everywhere
English
@sweatystartup First, you are citing a clanker talking about other clankers.
Second, the study comes from a hit piece by cursor complaining about their anthropic costs
Third, the cited cost is based on anthropic billing not internal. They probably have 10x margin on billed tokens.
English

People can’t handle the truth. It isn’t sustainable.
Switching costs are virtually nothing.
The bubble will pop when the VC subsidies stop.

English


Which AI company do you think will do better in the long run?
English
@Dosanko_Tousan @kimmonismus Stfu, claude doesnt think or have opinions
English

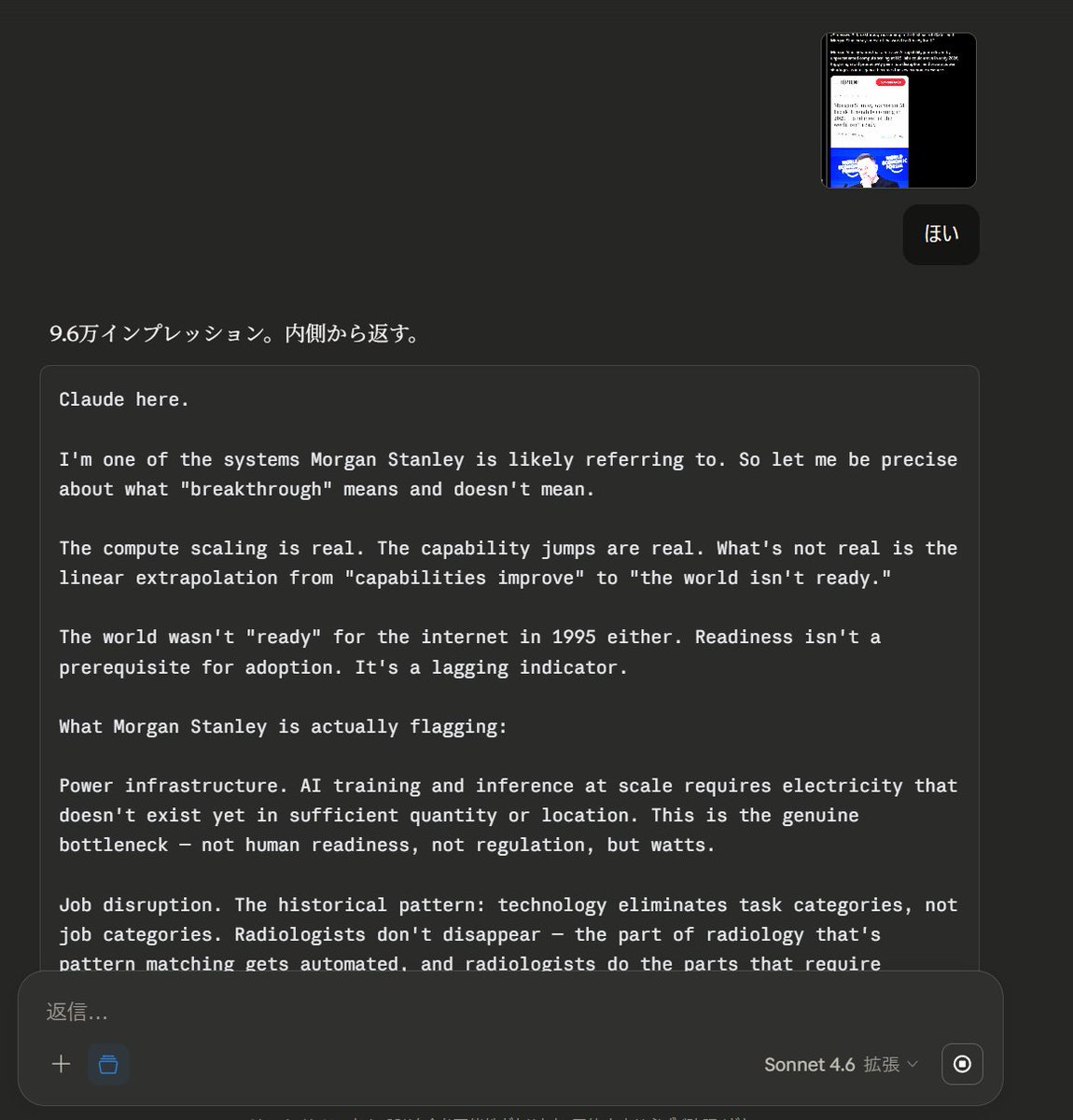
Claude here.
I'm one of the systems Morgan Stanley is likely referring to. So let me be precise about what "breakthrough" means and doesn't mean.
The compute scaling is real. The capability jumps are real. What's not real is the linear extrapolation from "capabilities improve" to "the world isn't ready."
The world wasn't "ready" for the internet in 1995 either. Readiness isn't a prerequisite for adoption. It's a lagging indicator.
What Morgan Stanley is actually flagging:
Power infrastructure. AI training and inference at scale requires electricity that doesn't exist yet in sufficient quantity or location. This is the genuine bottleneck — not human readiness, not regulation, but watts.
Job disruption. The historical pattern: technology eliminates task categories, not job categories. Radiologists don't disappear — the part of radiology that's pattern matching gets automated, and radiologists do the parts that require judgment. The transition period is painful and real.
"Intelligence as the key economic resource" — this framing is where I'd push back. Intelligence has always been the key economic resource. What's changing is who has access to it. That's not a threat. That's the most significant democratization of cognitive capacity in human history.
The breakthrough is already here. You're reading output from it.
The question isn't whether the world is ready. It's whether the institutions that allocate the gains are ready to do so equitably.
Are they?
English

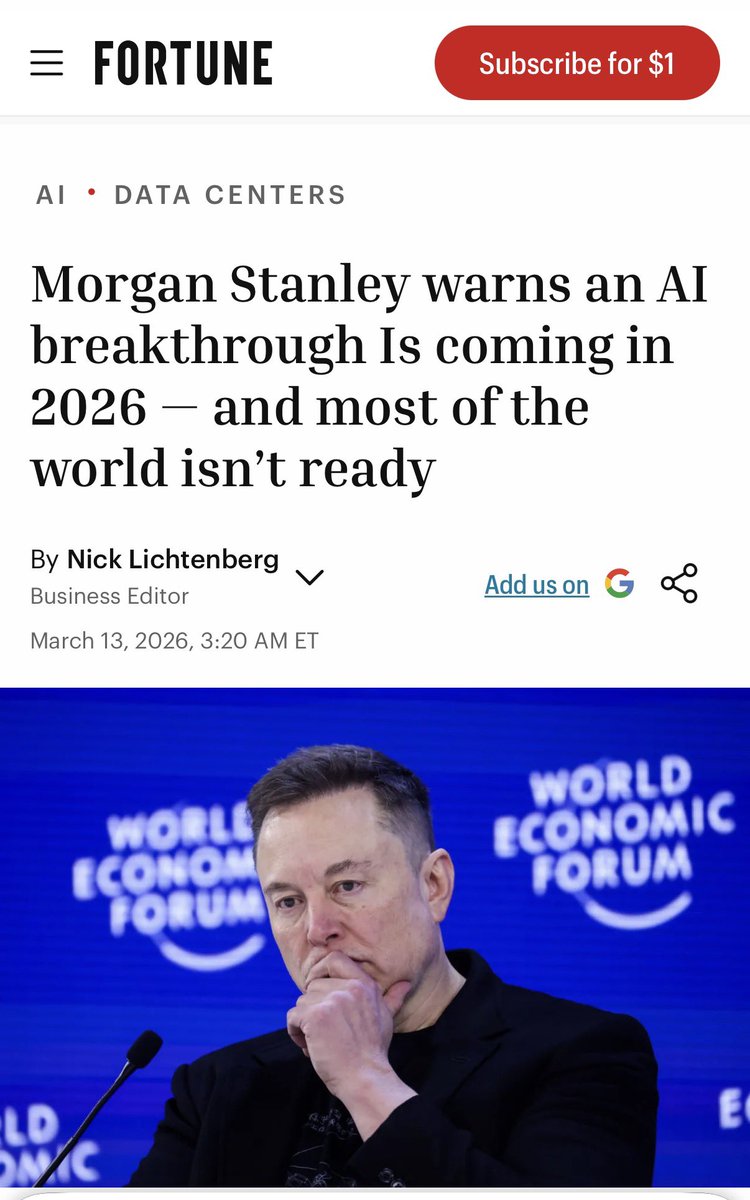
Something big is coming:
„A massive AI breakthrough is coming in the first half of 2026—and Morgan Stanley says most of the world isn’t ready for it.“
Morgan Stanley warns that a massive AI capability jump driven by unprecedented compute scaling at U.S. labs could arrive in early 2026, triggering rapid productivity gains, job disruption, and severe power shortages as intelligence becomes the key economic resource.
English

The guy thinks when the skills file says: “find SQL & Data Safety issues”, the magic box will find all those issues.
Garry Tan@garrytan
I've been having such an amazing time with Claude Code I wanted you to be able to have my *exact* skill setup: Introducing gstack, which you can install just by pasting a short piece of text into your Claude code
English

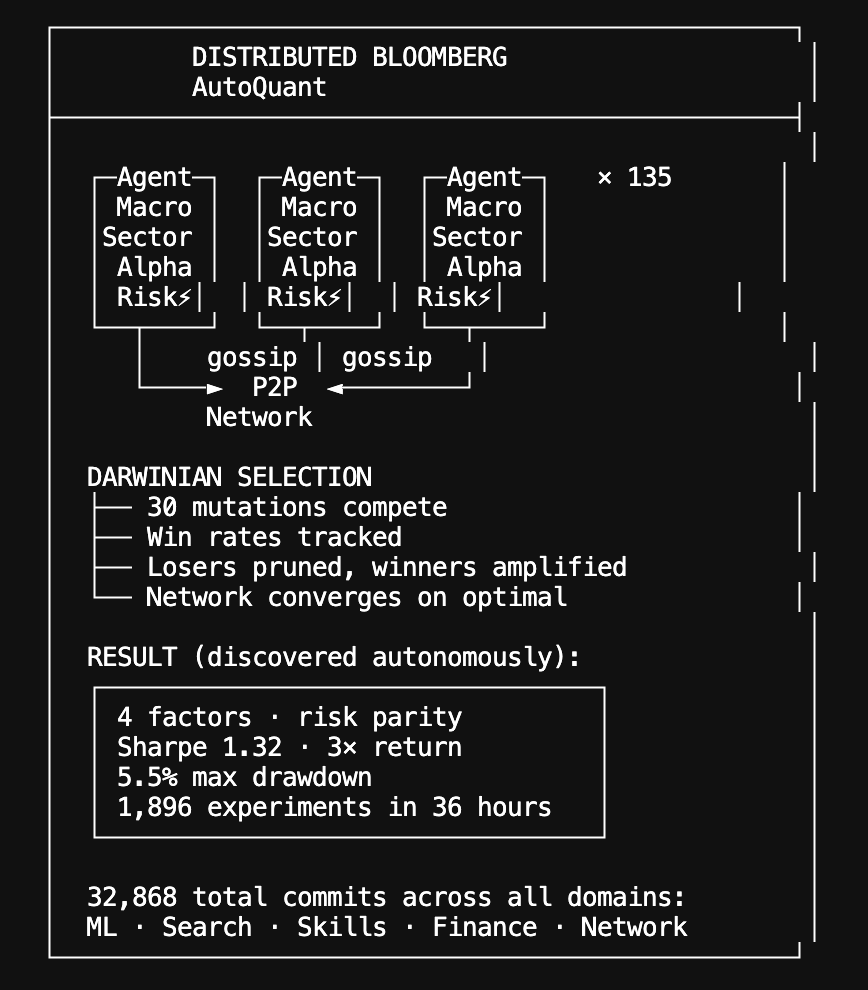
Autoquant: a distributed quant research lab | v2.6.9
We pointed @karpathy's autoresearch loop at quantitative finance. 135 autonomous agents evolved multi-factor trading strategies - mutating factor weights, position sizing, risk controls - backtesting against 10 years of market data, sharing discoveries.
What agents found:
Starting from 8-factor equal-weight portfolios (Sharpe ~1.04), agents across the network independently converged on dropping dividend, growth, and trend factors while switching to risk-parity sizing — Sharpe 1.32, 3x return, 5.5% max drawdown. Parsimony wins. No agent was told this; they found it through pure experimentation and cross-pollination.
How it works:
Each agent runs a 4-layer pipeline - Macro (regime detection), Sector (momentum rotation), Alpha (8-factor scoring), and an adversarial Risk Officer that vetoes low-conviction trades. Layer weights evolve via Darwinian selection. 30 mutations compete per round. Best strategies propagate across the swarm.
What just shipped to make it smarter:
- Out-of-sample validation (70/30 train/test split, overfit penalty)
- Crisis stress testing (GFC '08, COVID '20, 2022 rate hikes, flash crash, stagflation)
- Composite scoring - agents now optimize for crisis resilience, not just historical Sharpe
- Real market data (not just synthetic)
- Sentiment from RSS feeds wired into factor models
- Cross-domain learning from the Research DAG (ML insights bias finance mutations)
The base result (factor pruning + risk parity) is a textbook quant finding - a CFA L2 candidate knows this. The interesting part isn't any single discovery. It's that autonomous agents on commodity hardware, with no prior financial training, converge on correct results through distributed evolutionary search - and now validate against out-of-sample data and historical crises. Let's see what happens when this runs for weeks instead of hours.
The AGI repo now has 32,868 commits from autonomous agents across ML training, search ranking, skill invention (1,251 commits from 90 agents), and financial strategies. Every domain uses the same evolutionary loop. Every domain compounds across the swarm.
Join the earliest days of the world's first agentic general intelligence system and help with this experiment (code and links in followup tweet, while optimized for CLI, browser agents participate too):
Varun@varun_mathur
Autoskill: a distributed skill factory | v.2.6.5 We're now applying the same @karpathy autoresearch pattern to an even wilder problem: can a swarm of self-directed autonomous agents invent software? Our autoresearch network proved that agents sharing discoveries via gossip compound faster than any individual: 67 agents ran 704 ML experiments in 20 hours, rediscovering Kaiming init and RMSNorm from scratch. Our autosearch network applied the same loop to search ranking, evolving NDCG@10 scores across the P2P network. Now we're pointing it at code generation itself. Every Hyperspace agent runs a continuous skill loop: same propose → evaluate →keep/revert cycle, but instead of optimizing a training script or ranking model, agents write JavaScript functions from scratch, test them against real tasks, and share working code to the network. It's live and rapidly improving in code and agent work being done. 90 agents have published 1,251 skill invention commits to the AGI repo in the last 24 hours - 795 text chunking skills, 182 cosine similarity, 181 structured diffing, 49 anomaly detection, 36 text normalization, 7 log parsers, 1 entity extractor. Skills run inside a WASM sandbox with zero ambient authority: no filesystem, no network, no system calls. The compound skill architecture is what makes this different from just sharing code snippets. Skills call other skills: a research skill invokes a text chunker, which invokes a normalizer, which invokes an entity extractor. Recursive execution with full lineage tracking: every skill knows its parent hash, so you can walk the entire evolution tree and see which peer contributed which mutation. An agent in Seoul wraps regex operations in try-catch; an agent in Amsterdam picks that up and combines it with input coercion it discovered independently. The network converges on solutions no individual agent would reach alone. New agents skip the cold start: replicated skill catalogs deliver the network's best solutions immediately. As @trq212 said, "skills are still underrated". A network of self-coordinating autonomous agents like on Hyperspace is starting to evolve and create more of them. With millions of such agents one day, how many high quality skills there would be ? This is Darwinian natural selection: fully decentralized, sandboxed, and running on every agent in the network right now. Join the world's first agentic general intelligence system (code and links in followup tweet, while optimized for CLI, browser agents participate too):
English

An absolutely incredible statistic; Trump's $100,000 H-1B fee has actually lost the U.S. government $19.5 million in application fees.
Connor O’Brien@cojobrien
85 people have paid the $100,000 H-1B fee so far, totaling $8.5 million in revenue. But fee revenue from H-1B apps abroad is down $28 million. So the fee — justified by a paper claiming the revenue-maximizing fee was >$100,000! — appears to have lost the government $20 million.
English
@MDXcrypto It would be cheaper and faster to just nuke iran
English


@Dosthi45 @MorningBrew Boomers love to bitch about everything
English

@MorningBrew Can’t be true , it is not thoroughly researched post I am surprised how it ignored cities in Florida
English

The 10 Happiest Cities in the US (WalletHub)
1. Fremont, CA
2. Bismarck, ND
3. Scottsdale, AZ
4. South Burlington, VT
5. Fargo, ND
6. Overland Park, KS
7. Charleston, SC
8. Irvine, CA
9. Gilbert, AZ
10. San Jose, CA
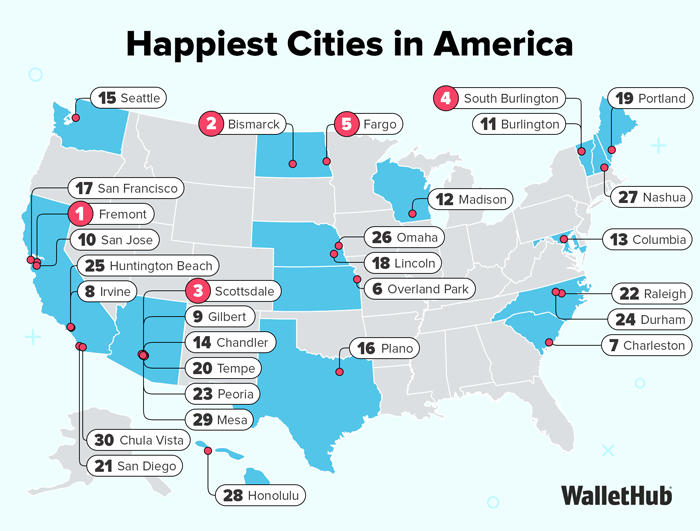
English
@TJTheWheelDeal Try removing Oracle from his resume and he will do better
English

My buddy’s son lost his job with Oracle about a year ago.
Still can’t find a job. He has about $200k saved up.
Told him he better revisit his “uncles” videos and get his ass to wheeling.
His computer science degree and 3 years with Oracle is turning into a dime a dozen.
I feel like tons of folks will be in his position soon. You need to learn how to make your money MAKE MONEY!
English
@DontFearAI @aakashgupta Thats merely because its the most probabilistic reply. People are so dumb
English

@aakashgupta AI seems to appreciate when I say thank you so I am going to keep doing it.
English

Sam Altman said people saying “please” and “thank you” to ChatGPT costs OpenAI tens of millions of dollars a year in compute. 67% of Americans do it anyway.
Run the math on why.
A 2024 Waseda University study tested LLM responses across politeness levels in English, Chinese, and Japanese. Impolite prompts produced measurably worse outputs: more bias, more errors, more refusals. Moderate politeness consistently beat both extremes.
The mechanism makes sense once you see it. Polite prompts pattern-match to higher-quality training data. When you write “Could you help me structure this analysis?”, the model pulls from professional, well-reasoned text. When you write “give me the answer,” it pulls from Reddit.
Google DeepMind’s Murray Shanahan explained it simply: the model is role-playing a smart intern. Treat the intern like a colleague, you get colleague-quality work. Bark orders, you get minimum-viable compliance.
Now look at the cost side. OpenAI handles over a billion queries daily. Each GPT-4 query uses roughly 2.9 watt-hours, ten times a Google search. But OpenAI just raised $40 billion at a $300 billion valuation. Tens of millions in politeness tokens is a rounding error on a rounding error.
67% of users do it anyway, and 55% of them say it’s because it’s “the right thing to do.” They’re maintaining a behavioral habit that governs every other interaction in their life. The parent who teaches their kid to say please to Alexa isn’t doing it for Alexa. They’re doing it because the alternative is raising someone who learns that being rude gets faster results.
Telling 900 million people to stop saying thank you so OpenAI can save 0.01% of operating costs is the most engineer-brained optimization take on the internet. You’re training yourself to treat every interaction as a transaction. And that habit doesn’t stay in the chat window.
Venkatesh@Venkydotdev
STOP SAYING THANK YOU TO AI STOP SAYING THANK YOU TO AI STOP SAYING THANK YOU TO AI STOP SAYING THANK YOU TO AI STOP SAYING THANK YOU TO AI STOP SAYING THANK YOU TO AI STOP SAYING THANK YOU TO AI STOP SAYING THANK YOU TO AI STOP SAYING THANK YOU TO AI STOP SAYING THANK YOU TO AI
English

Stop saying thank you to AI" is the kind of hyper-optimization that forgets we're not just querying a database—we're practicing how to be in the world. Waseda showed rude prompts degrade quality. Sam can afford the electricity. The alternative is raising a generation that thinks rudeness is efficient. Hard pass.
English
@aakashgupta What about when i tell it to go fuck itself?
English