kendrick@exploding_grad
Not so boring Monday mornings thanks to Kimi.
Makes me think --
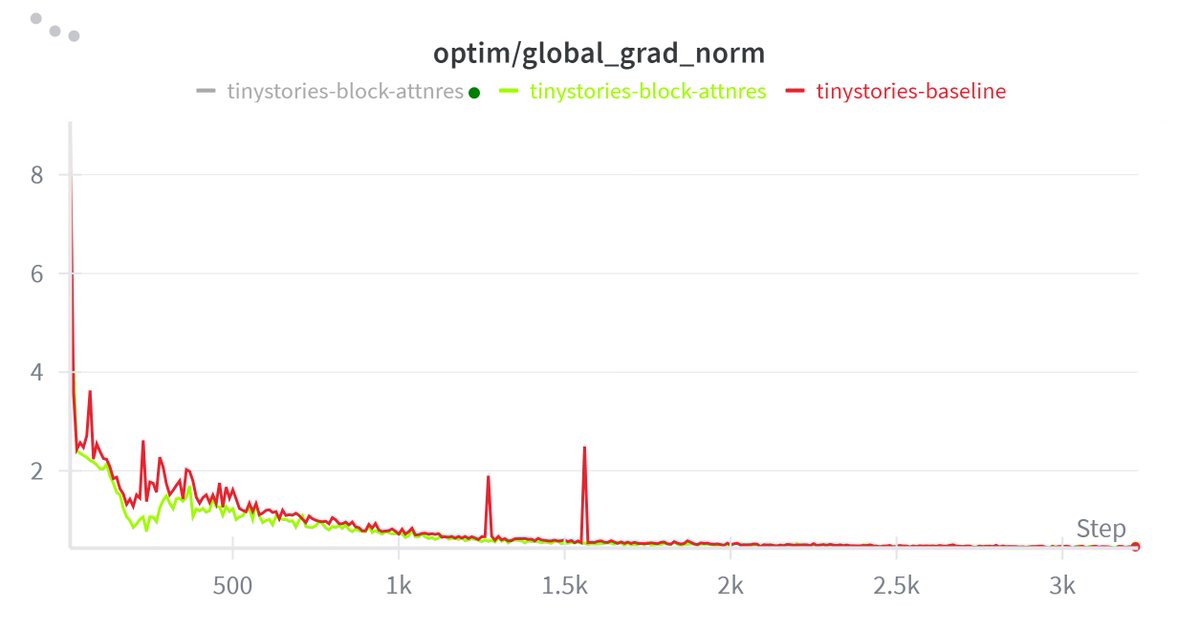
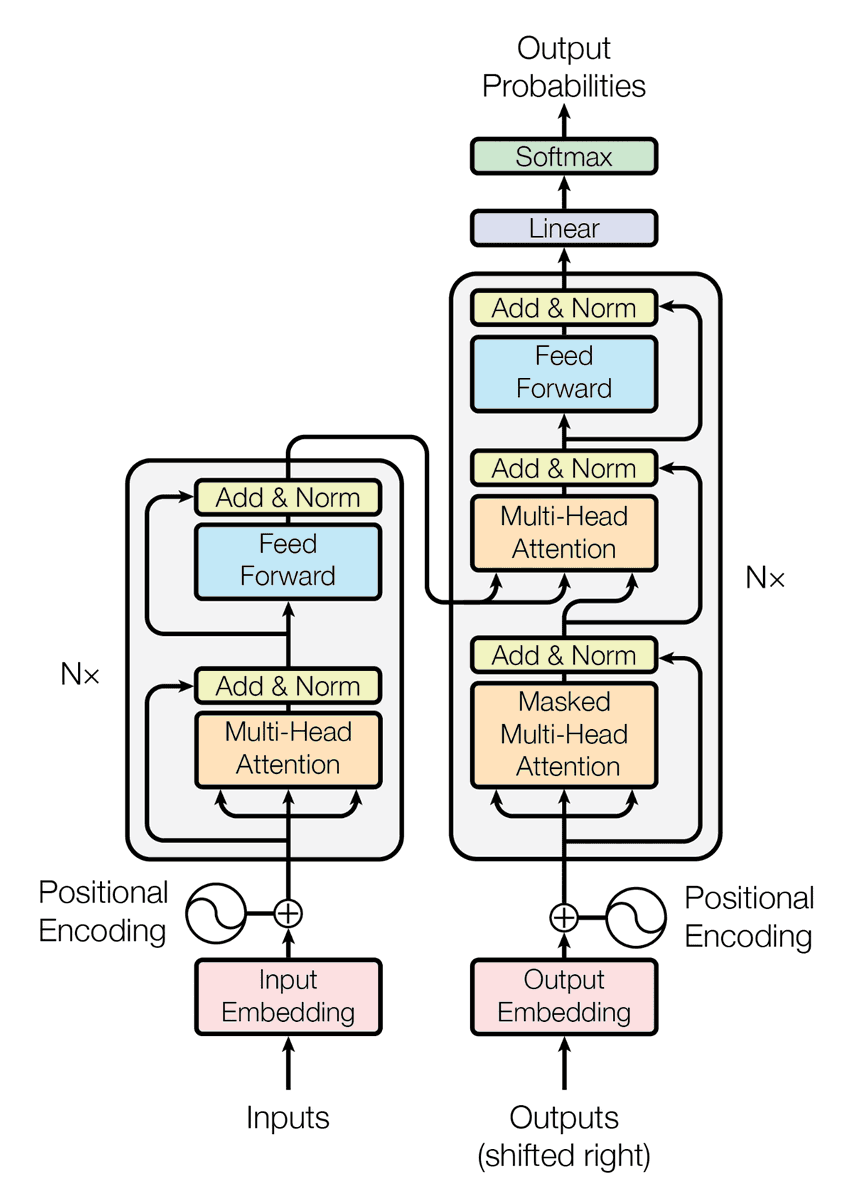
- The whole goal is to de-noise the residual stream (selective cross-layer retrieval kinda) - replace unweighted sum of previous layer's outputs with "attention" over previous layers.
- I'm guessing this would try to preserve contributions of early layers better than standard res stream and reduce hidden states magnitudes.
But wouldn’t filtering be bad?
- In standard res stream implementation, subsequent heads have access to the addition of prior layer information, which may preserve info but can make it harder to access cleanly, and it's upto them to choose where to look at (QK) and what to extract (OV).
- Having attention over previous layer in res stream could "gate-keep" some information (especially if it is input-independent) if not properly implemented, right? Or am I being crazy?
- The default attnRes is not fully input-agnostic, but it is less input-adaptive than self-attention, because the query is fixed per layer and only the keys/values vary with the token.
-> Layer 'l' does not always attend to the same mix of prior layers regardless of whether the input is a math problem or a poem.
-> Instead, layer l has a fixed retrieval preference through its learned pseudo-query w_l, but the final mix over prior layers still depends on the token’s earlier-layer representations.
-> So for a math token, layer l might put more weight on certain earlier reasoning-related layers, while for a poem token it could shift weight toward different earlier layers — just not as flexibly as standard token-to-token QK attention.
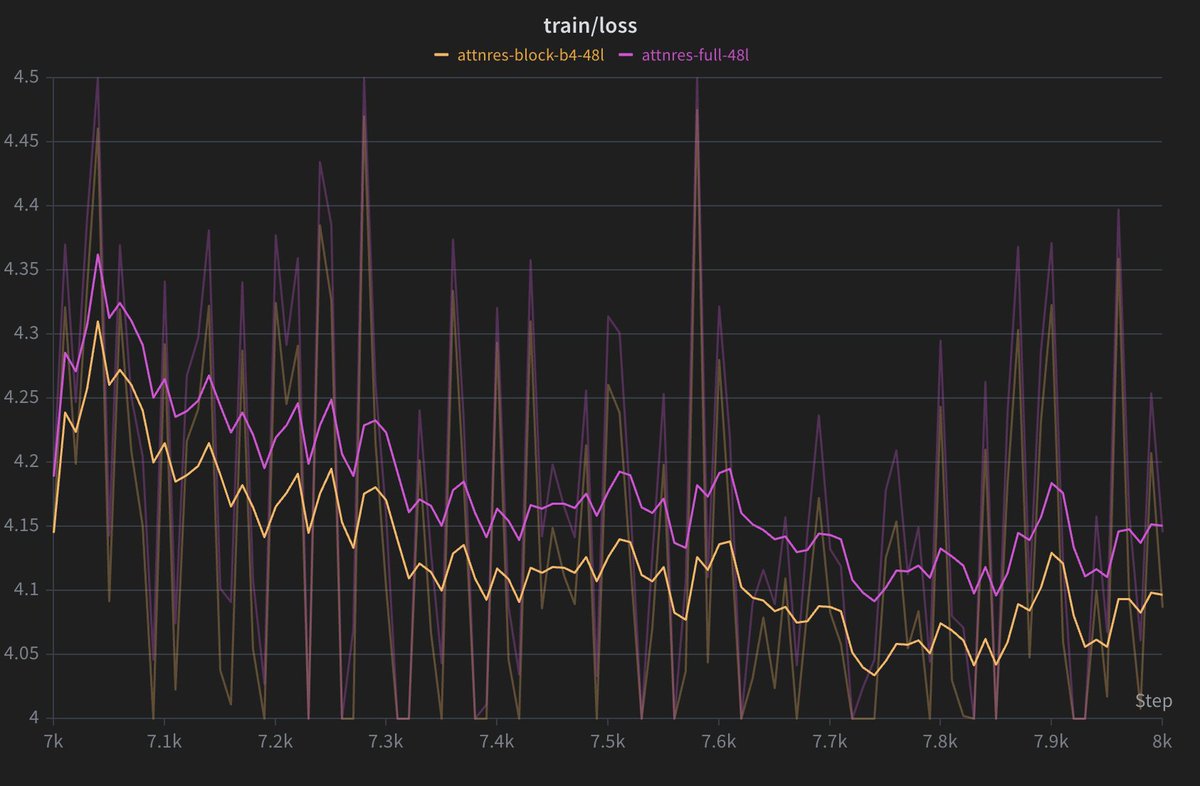
But one MAJOR one counter-argument would be when it works then it would make the heads MUCH MORE interpretable. Cleaner signals from previous layers would be helpful for the subsequent heads to attend to -> leading to less interference -> better probe performance and generalization.