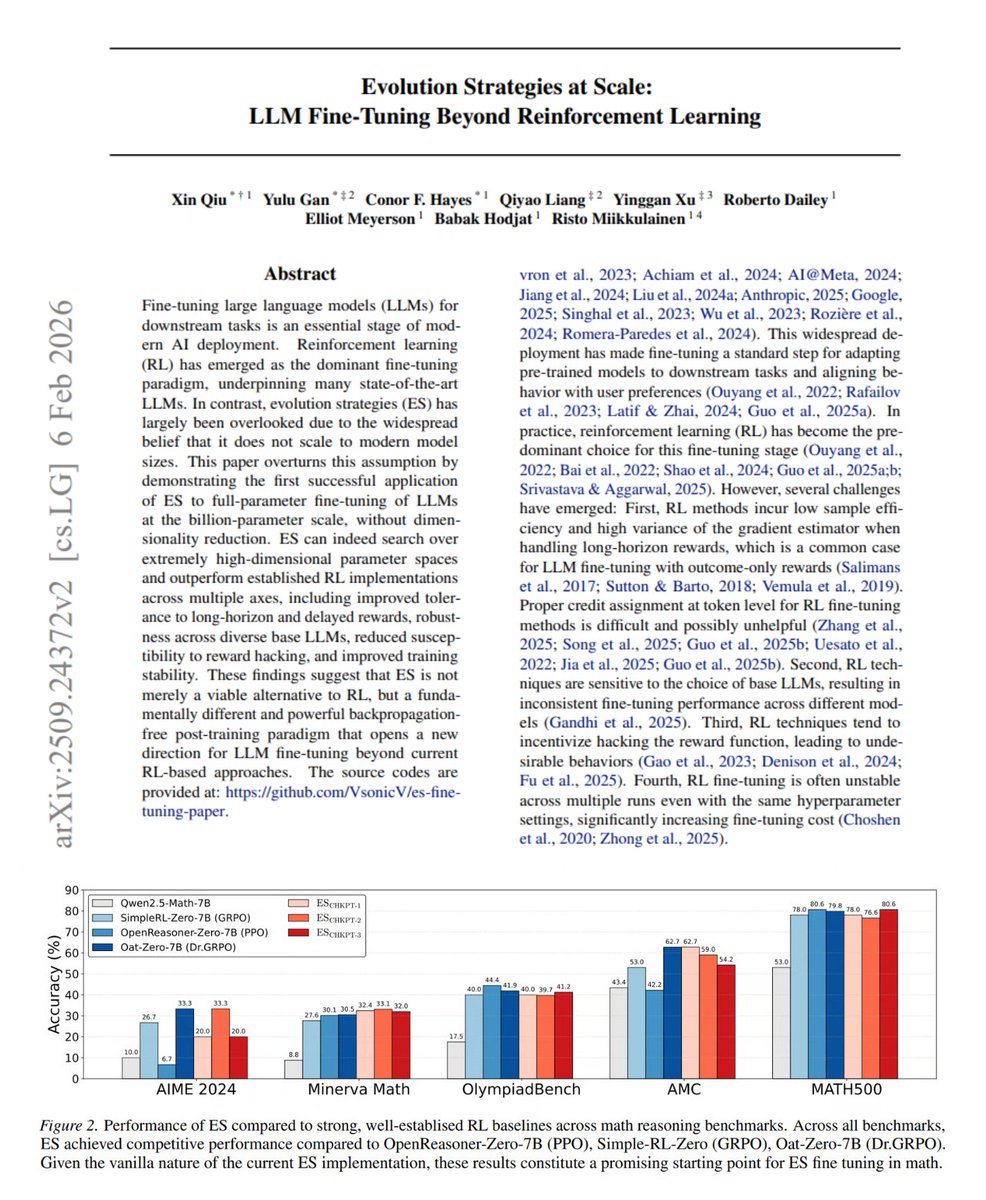
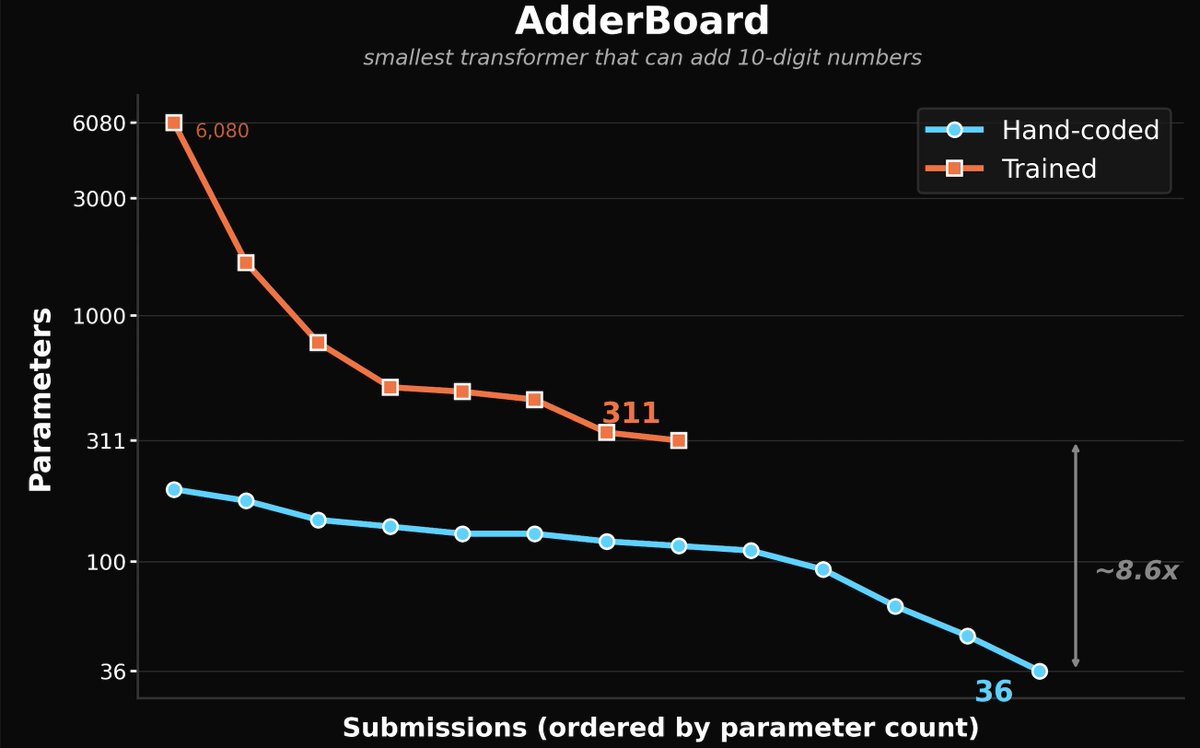
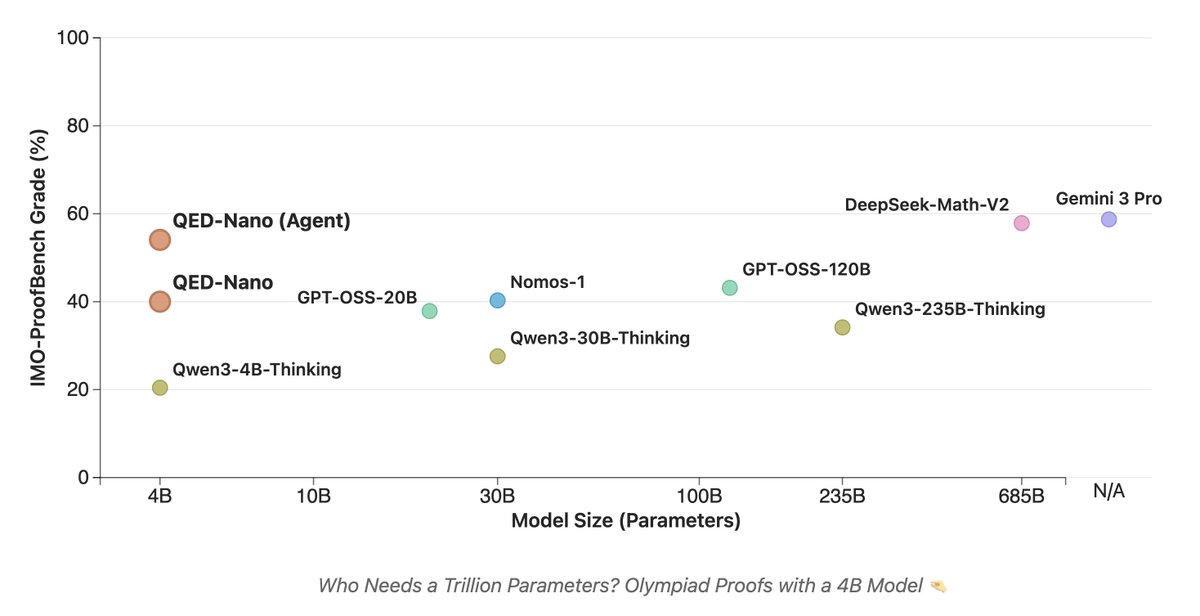
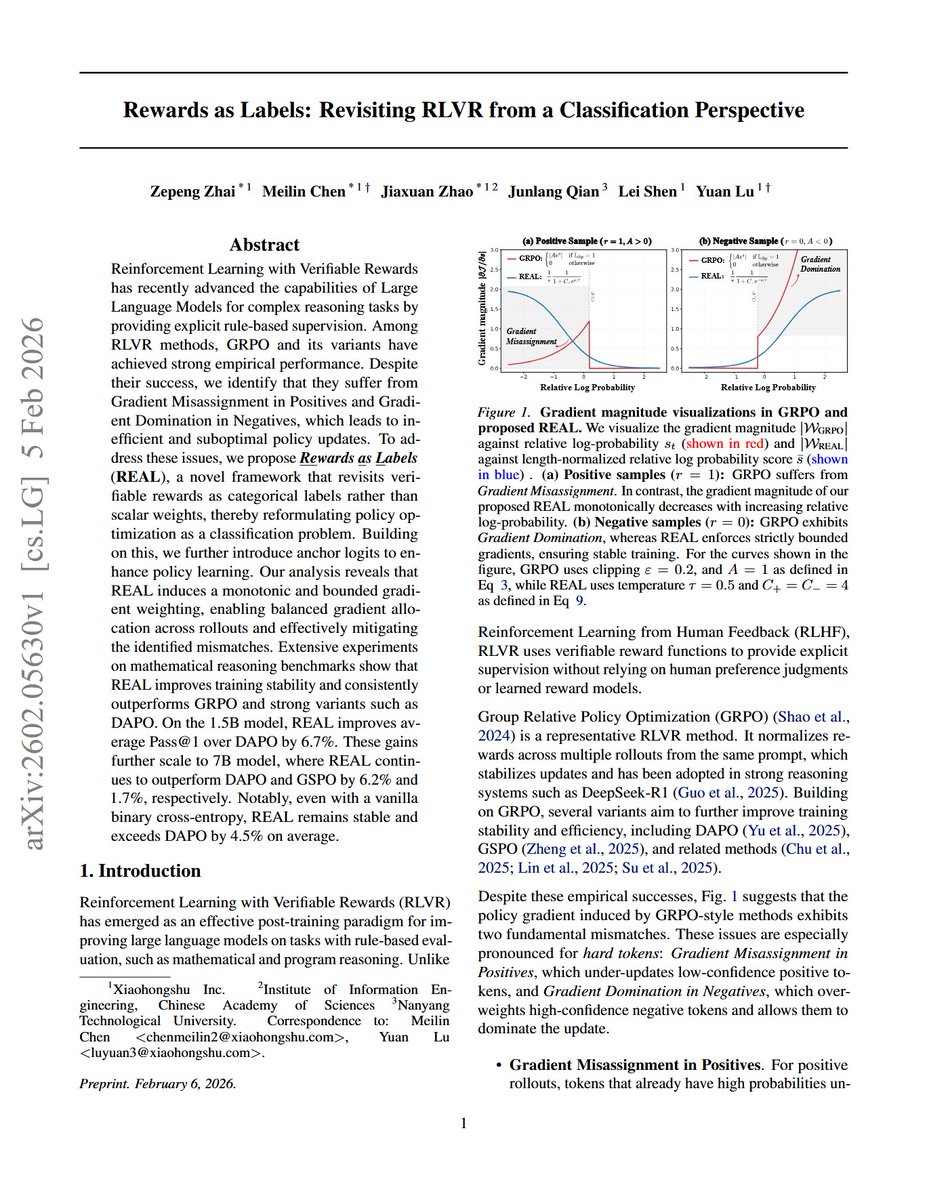
Jefferson Enrique Hernandez Cevallos retweetou

Thread on VJEPA 2.1🤟
This DEFINITELY flew under the radar: just a few days ago, @AIatMeta released V-JEPA 2.1, taking a massive step toward closing the gap between image and video domains.
For a long time, image backbones were the only option for solving dense vision tasks. This model disagrees, showing that universal spatial understanding also emerges from large-scale video models!🎥

English