vislang.ai retweetledi

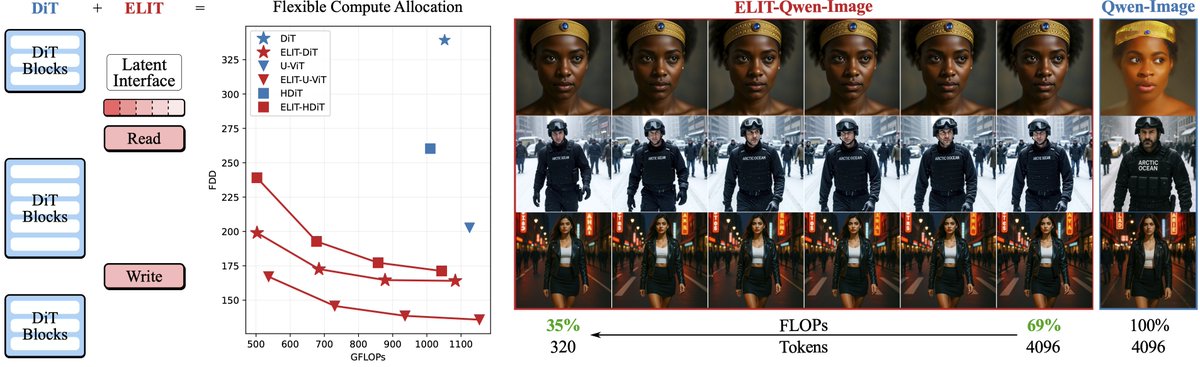
Not all pixels are equally hard, but DiTs still allocate compute uniformly across pixels, wasting efforts on easy regions. ELIT adds two lightweight cross-attention layers to focus compute where it matters, cutting FID by 53%.
ELIT: snap-research.github.io/elit

English