Tweet fixado

re @mattshumer_’s: Will AI replicate deep human empathy? Replace the trust built over years of a relationship?
much to say at the very incomplete the-shape-of-experience.vercel.app




Matt Shumer@mattshumer_
English
Jacob
11.6K posts

@jvboid
API/Integration architect @AGI_Inc

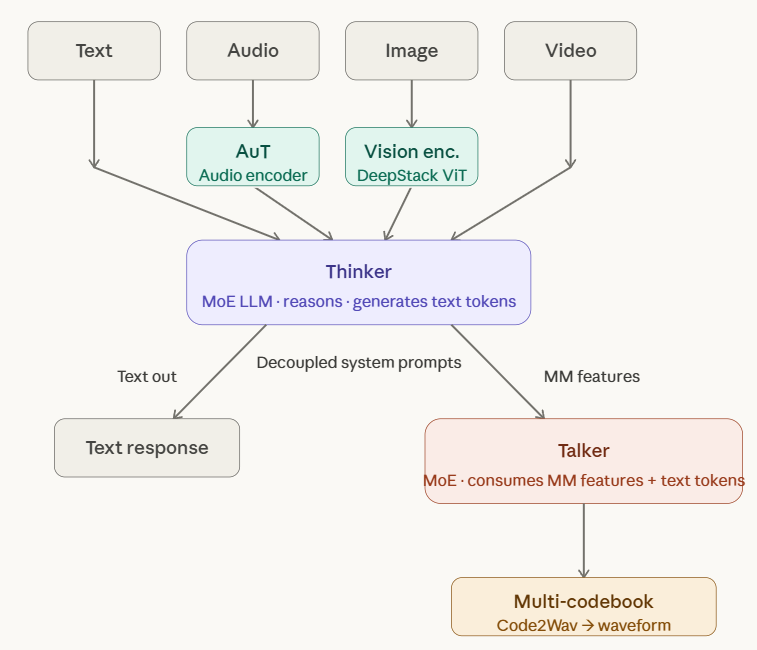
🚀 Qwen3.5-Omni is here! Scaling up to a native omni-modal AGI. Meet the next generation of Qwen, designed for native text, image, audio, and video understanding, with major advances in both intelligence and real-time interaction. A standout feature: 'Audio-Visual Vibe Coding'. Describe your vision to the camera, and Qwen3.5-Omni-Plus instantly builds a functional website or game for you. Offline Highlights: 🎬 Script-Level Captioning: Generate detailed video scripts with timestamps, scene cuts & speaker mapping. 🏆 SOTA Performance: Outperform Gemini-3.1 Pro in audio and matches its audio-visual understanding. 🧠 Massive Capacity: Natively handle up to 10h of audio or 400s of 720p video, trained on 100M+ hours of data. 🌍 Global Reach: Recognize 113 languages (speech) & speaks 36. Real-time Features: 🎙️ Fine-Grained Voice Control: Adjust emotion, pace, and volume in real-time. 🔍 Built-in Web Search & complex function calling. 👤 Voice Cloning: Customize your AI's voice from a short sample, with engineering rollout coming soon. 💬 Human-like Conversation: Smart turn-taking that understands real intent and ignores noise. The Qwen3.5-Omni family includes Plus, Flash, and Light variants. Try it out: Blog: qwen.ai/blog?id=qwen3.… Realtime Interaction: click the VoiceChat/VideoChat button (bottom-right): chat.qwen.ai HF-Demo: huggingface.co/spaces/Qwen/Qw… HF-VoiceOnline-Demo: huggingface.co/spaces/Qwen/Qw… API-Offline: alibabacloud.com/help/en/model-… API-Realtime: alibabacloud.com/help/en/model-…