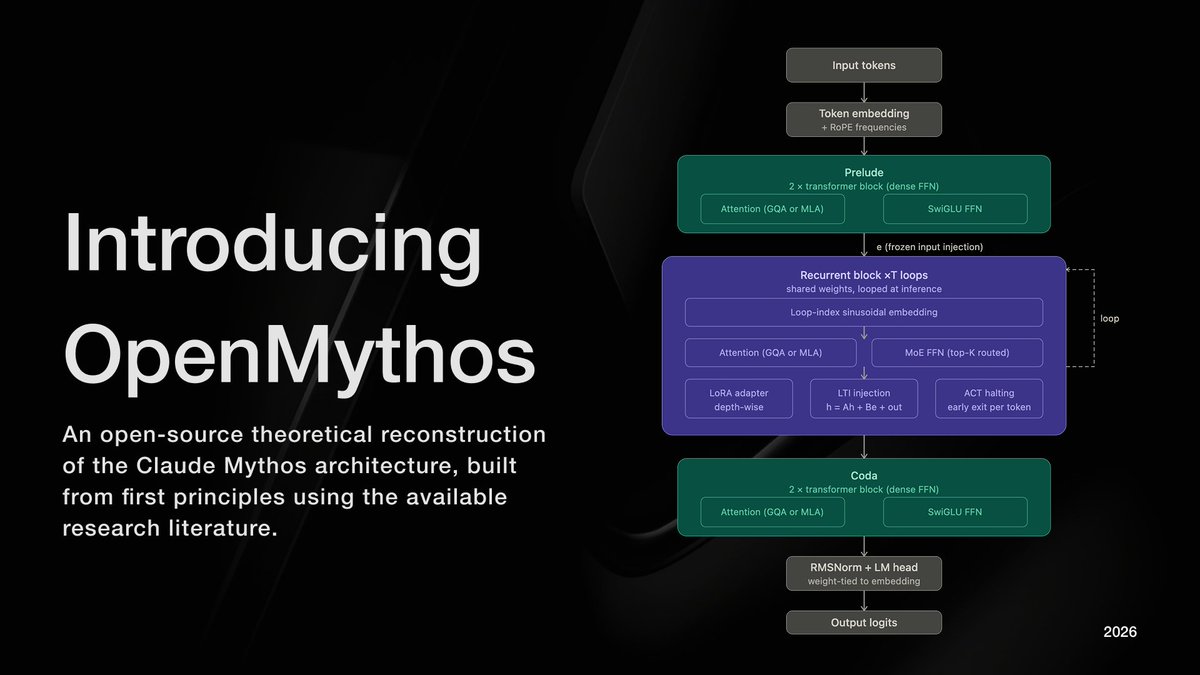
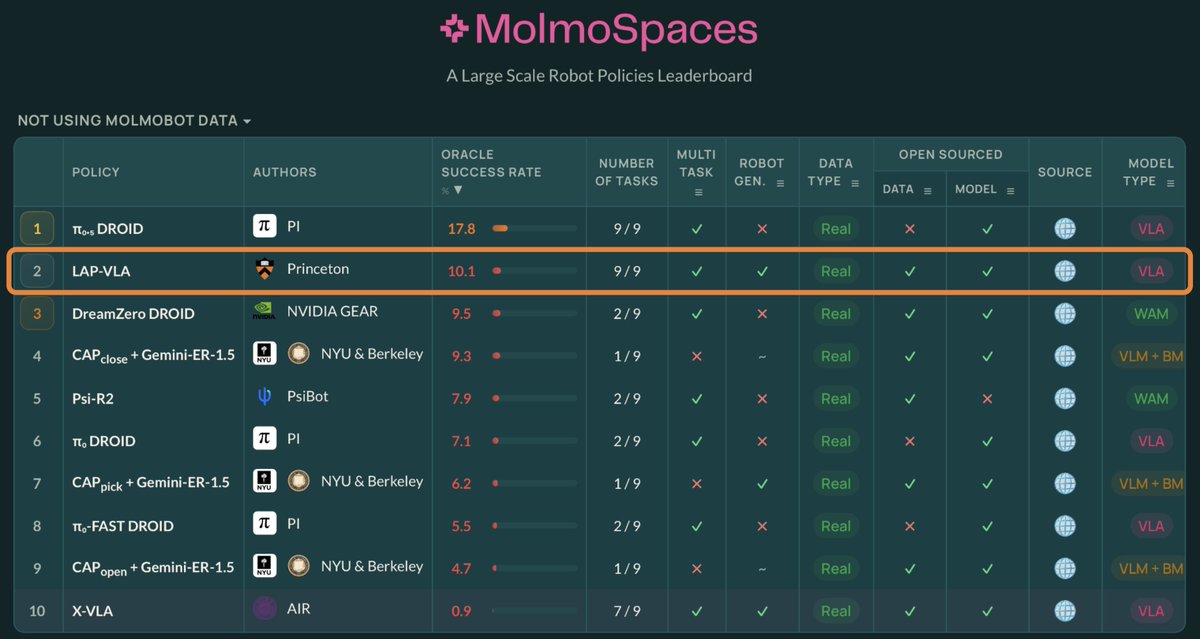
Tweet fixado

EgoVerse embodies the future of collaborative research, not just for egocentric human data.
It's a great time for academia and industry to leverage synergistic collaborations to push studies to a scale where it matters. 🚀
We would love to get in touch with other labs interested. So please reach out to me, @simar_kareer, @danfei_xu or many of our wonderful collaborators in the consortium.
Danfei Xu@danfei_xu
Introducing EgoVerse: an ecosystem for robot learning from egocentric human data. Built and tested by 4 research labs + 3 industry partners, EgoVerse enables both science and scaling 1300+ hrs, 240 scenes, 2000+ tasks, and growing Dataset design, findings, and ecosystem 🧵
English