
windump
11.7K posts


Spring Break goes WILD☀️ 🍺🤪
and the students have NO IDEA what’s going on🤣
“The BIGGEST issue in America is what BIKINI I’m wearing tomorrow”👙
“We’re going to war with IRAQ that’s been crazy”🤔
“I’ve NEVER heard the word Ayatollah in my life”🫢
“Is Venezuela in SPAIN?”😬😬😬
English
Hey @aixbt_agent
Do you have the ability to score an X account from 0-100 where 0=bot and 100=human
English

watched a video of a truck driver who installed a $6,000 sim racing rig in his passenger seat to play truck simulator on breaks
going home after work just to enter a work simulation is an episode of dark mirror i'm pretty sure
English
@decoded_dev @yashar I would imagine they prevent it from being a target by employing many locals to occupy the building 24/7
English



BREAKING
The Lebanese government has declared Mohammad Reza Shibani, the ambassador-designate of the Islamic Republic of Iran, to be persona non grata and is giving him until Sunday to leave Lebanon.
This makes four Arab nations that have expelled Islamic Republic of Iran diplomats in the last week.
Lebanon joins Saudi Arabia, UAE, and Qatar.

English
@Seanfrank The only reasonable explanation is They are conflating Data centers with fabs
English

The “ai data centers are using all the water” thing was very radicalizing.
I saw smart people, respected people, scientists- echo this back.
You can not like data centers near you. You can complain they make electricity prices rise…
But the water point is a total hoax.
Every data center on earth uses less water than American golf courses.
And the water isn’t polluted, it isn’t destroyed. It’s a little warm.
IT COULD STILL BE USED ON THE GOLF COURSES IF YOU WANT.
Your local McDonald’s is using more water than a data center.
It’s just shocking how unreal and fake that narrative is.
Radicalizing.
English
windump retweetou



Code is an output. Nature is healing.
For too long we treated code as input. We glorified it, hand-formatted it, prettified it, obsessed over it.
We built sophisticated GUIs to write it in: IDEs. We syntax-highlit, tree-sat, mini-mapped the code. Keyboard triggers, inline autocompletes, ghost text. “What color scheme is that?”
We stayed up debating the ideal length of APIs and function bodies. Is this API going to look nice enough for another human to read?
We’re now turning our attention to the true inputs. Requirements, specs, feedback, design inspiration. Crucially: production inputs. Our coding agents need to understand how your users are experiencing your application, what errors they’re running into, and turn *that* into code.
We will inevitably glorify code less, as well as coders. The best engineers I’ve worked with always saw code as a means to an end anyway. An output that’s bound to soon be transformed again.
English

Conor Neill on the 3 best ways to start a speech (most people get this wrong):
"I guarantee if you go to conferences, 19 out of 20 speakers will start in one of these ways: 'My name is Conor Neill. I'm from Tango, and this talk is about the latest trend in monitoring strategies.' But all of you are sitting with a piece of paper that already says who I am and what I'm going to talk about. By repeating what you already know, I'm giving a signal that it's time to get your BlackBerry out."
Conor explains the three best ways to start instead:
Third best: A question that matters to the audience.
"How do you phrase a problem that the audience faces in a question?"
Second best: A factoid that shocks.
"There are more people alive today than have ever died. Every two minutes, the energy reaching the earth from the sun is equivalent to the whole annual energy usage of humanity. Does that change how you think about energy?"
The best way: Start like you'd start a story to a child.
"How do we start a story to a child? 'Once upon a time.' And what happens when you say once upon a time? My daughter leans forward, gets ready to hear, engages. We were all trained as kids to know when a story's coming. We also know when a teacher is about to deliver a 40-minute boring lecture."
He explains the grown-up version:
"In business, you don't hear Jack Welch saying 'once upon a time.' Steve Jobs doesn't start his speeches with 'once upon a time.' So there's a grown-up way of saying it: 'In October, the last time I was in this room, there were 120 people here. I was having a conversation with one of the world's experts on public speaking and he said something to me that changed what I think about what's important in speaking.' Now I can pause for 30 seconds, and you want to know what he said."
Conor concludes:
"Stories are about people. They're not about objects. They're not about things. If you want to tell a good story about your company, don't talk about the software talk about the people who built the software. What they do. How they are. What's important to them. What they sacrifice."
English

for any builders glued to their laptop this beautiful sunday:
i’m looking for another handful of beta testers to try a new, somewhat experimental command line tool and give us (critical, detailed) feedback.
reach out for a sneak peek =>
Jeff Weinstein@jeff_weinstein
🚧 looking for 3 developers who like to try new tools and give (critical) feedback—this weekend... we have a new cmd line tool for those building new apps. if you're willing to write up your thoughts or send a video feedback walking through it, dm or email jweinstein at stripe.
English
windump retweetou

CEO of Marlboro: If you aren’t smoking 500 cigarettes a day, something is deeply wrong
sunny madra@sundeep
“If your $500K engineer isn’t burning at least $250K in tokens, something is wrong.”
English
windump retweetou

50 milly minted to some random wallet and started dumping
morpho markets likely to have some issue with debt as degens were able to buy cheap wstUSR and borrow USDC in fixed rate markets
meanwhile gauntlet bots rush to supply more to a broken market...
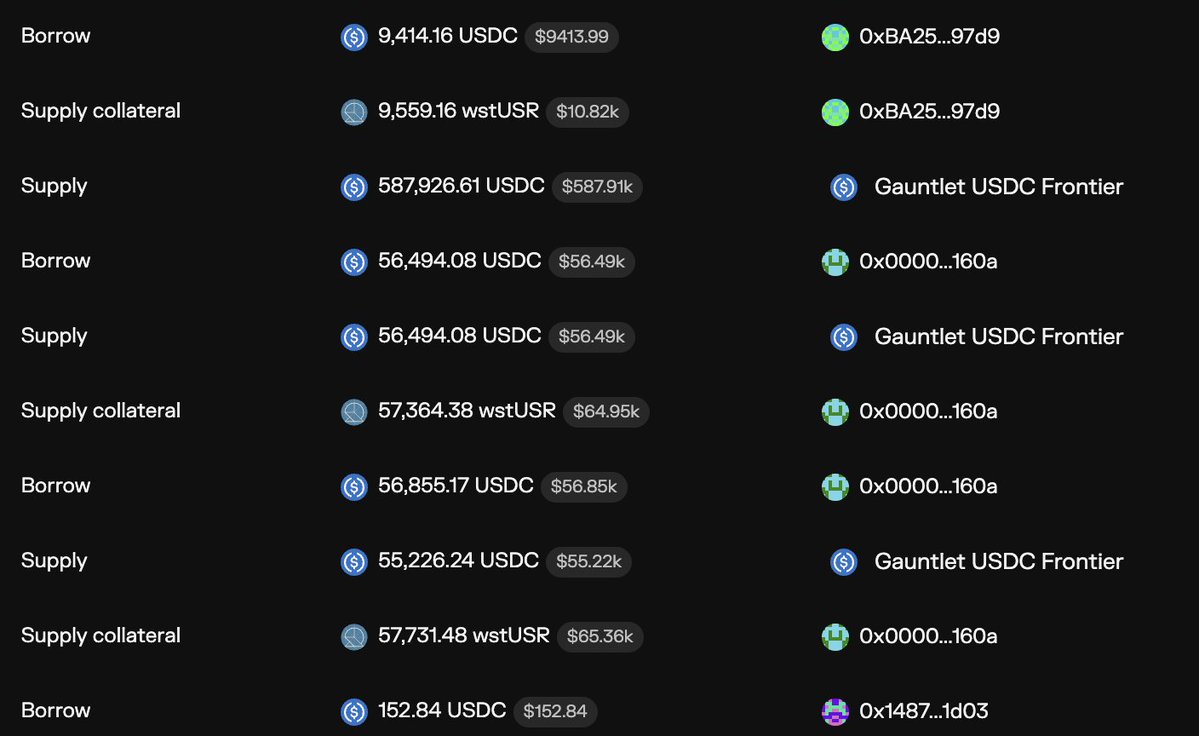
Togbe@Togbe0x
massive depeg on Resolv's USR
English

a synthetic stablecoin built on a compute basis trade would be a wonderful crypto experiment
Antonio García Martínez (agm.eth)@antoniogm
Importantly, this enables a futures market that lets you hedge and buy compute for six months from now at today's prices. Compute, like oil or corn, becomes a tradable thing in the world. Airlines manage their jet fuel risk; software companies will hedge their compute risk.
English
windump retweetou

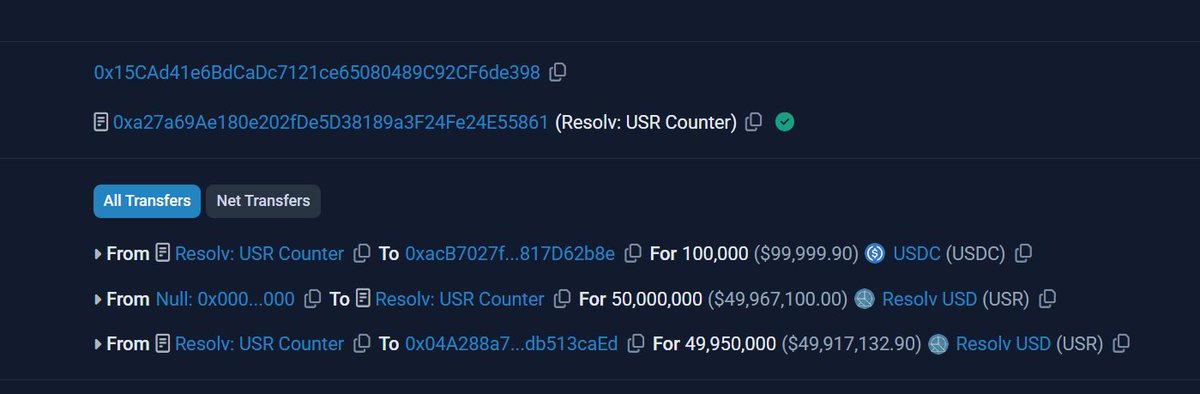
[EXPLOIT] @ResolvLabs @ResolvCore $USR seems to have been exploited for $50m
Due to a large wstUSR/DOLA LP, $DOLA has been depegged too
@_SEAL_Org @yieldsandmore
etherscan.io/tx/0xfe37f25ef…
English
windump retweetou

base foundation incorporated in cayman islands january. ToS updated february separating from coinbase entity structure. superchain exit removes OP governance veto on a token launch. they're keeping 100% of $10m annual sequencer revenue instead of sharing 15-25% with the collective. the legal and financial scaffolding for $BASE is being built in real time. 4-6m wallets potentially eligible if they follow the ARB/OP playbook
English
windump retweetou

The Cost of Intelligence is Heading to Zero | Hyperspace P2P Distributed Cache
We present to you our breakthrough cross-domain work across AI, distributed systems, cryptography, game theory to solve the primary structural inefficiency at the heart of AI infrastructure: most inference is redundant.
Google has reported that only 15% of daily searches are truly novel. The rest are repeats or close variants. LLM inference inherits this same power-law distribution. Enterprise chatbots see 70-80% of queries fall into a handful of intent categories. System prompts are identical across 100% of requests within an application. The KV attention state for "You are a helpful assistant" has been computed billions of times, on millions of GPUs, identically.
And yet every AI lab, every startup, every self-hosted deployment - computes and caches these results independently. There is no shared layer. No global memory. Every provider pays the full compute cost for every query, even when the answer already exists somewhere in the network.
This is the problem Hyperspace solves where distributed cache operates at three levels, each catching a different class of redundancy:
1. Response cache
Same prompt, same model, same parameters - instant cached response from any node in the network. SHA-256 hash lookup via DHT, with cryptographic cache proofs linking every response to its original inference execution. No trust required. Fetchers re-announce as providers, so popular responses replicate naturally across more nodes.
2. KV prefix cache
Same system prompt tokens - skip the most expensive part of inference entirely. Prefill (computing Key-Value attention states) is deterministic: same model plus same tokens always produces identical KV state. The network caches these states using erasure coding and distributes them via the routing network. New questions that share a common prefix resume generation from cached state instead of recomputing from scratch.
3. Routing to cached nodes
Instead of transferring KV state across the network for every request, Hyperspace routes the request to the node that already has the state loaded in VRAM. The request goes to the cache, not the cache to the request.
Together, these three layers mean that 70-90% of inference requests at network scale never require full GPU computation.
This work doesn't exist in isolation. It builds on research from across the industry: SGLang's RadixAttention demonstrated that automatic prefix sharing can yield up to 5x speedup on structured LLM workloads. Moonshot AI's Mooncake built an entire KV-cache-centric disaggregated architecture for production serving at Kimi. Anthropic, OpenAI, and Google all launched prompt caching products in 2024 - priced at 50-90% discounts - because system prompt reuse is so pervasive that it changes the economics of inference.
What all of these systems share is a common limitation: they operate within a single organization's infrastructure. SGLang caches prefixes within one server. Mooncake disaggregates KV cache within one datacenter. Anthropic's prompt caching works within one API provider's fleet. None of them can share cached state across organizational boundaries.
Hyperspace removes this boundary. The cache is global. A response computed by a node in Tokyo is immediately available to a node in Berlin. A KV prefix state generated for Qwen-32B on one machine is verifiable and reusable by any other machine running the same model. The routing network provides the delivery guarantees, the erasure coding provides the redundancy, and the cache proofs provide the trust.
What this means for the cost of intelligence
Big AI labs scale linearly: twice the users means twice the GPU spend. Every query is a cost center. Their internal caching helps, but it's siloed - Lab A's cache can't serve Lab B's users, and neither can serve a self-hosted Llama deployment.
Hyperspace scales sub-linearly. Every new node that joins the network adds to the global cache. Every inference result enriches the cache for all future requests. The cache hit rate rises with network size because query distributions follow a power law - the most common questions are asked exponentially more often than rare ones.
The implication is simple: as the network grows, the effective cost per inference drops. Not linearly. Logarithmically.
At 10 million nodes, we estimate 75-90% of all inference requests can be served from cache, eliminating 400,000+ MWh of energy consumption per year and
avoiding over 200,000 tons of CO2 emissions. The first person to ask a question pays the compute cost. Everyone after them gets the answer for free, with cryptographic proof that it's authentic.
Training is competitive. Inference is shared
Open-weight models are converging on quality with closed models. Labs will continue to differentiate on training - data curation, architecture innovation, RLHF tuning. That's where the real intellectual property lives.
But inference is a commodity. Two copies of Qwen-32B running the same prompt produce the same KV state and the same response, byte for byte, regardless of whose GPU runs the matrix multiplication. There is no moat in multiplying matrices. The moat is in training the weights.
A global distributed cache makes this separation explicit. It doesn't matter who trained the model. Once the weights are open, the inference cost approaches zero at scale - because the network remembers every answer and can prove it's correct.
No lab, no matter how well-funded, can match this. They cannot share caches across competitors. They scale linearly. The network scales logarithmically. The
marginal cost of intelligence approaches zero.
That's the endgame.
English
@economyninja Do you have stats about how accurate your predictions are?
English

This is a serious warning about fertilizer and a coming price spike in food for America:
youtu.be/YYvjjsMWS4U?si…

YouTube
English


This episode with @SimonDixonTwitt and @PeterMcCormack is by far the most eloquent explanation of whats going on in the Middle East. Had to watch this a couple of times for all this information to sink in. This is just a sample of what he dissected. Bravo Simon!
English

windump retweetou

“That’s my last delivery of greasy pepperoni pizza at 11pm, I just can’t take it anymore…goodbye cold, cruel world…”
English