
dev
1.8K posts




@ShanuMathew93 Seeing people say opus 4.5 is performing better than 4.6 rn
English

Opus is so unbelievably nerfed today, it's like talking to a model from 2-3 years ago. What is going on
English


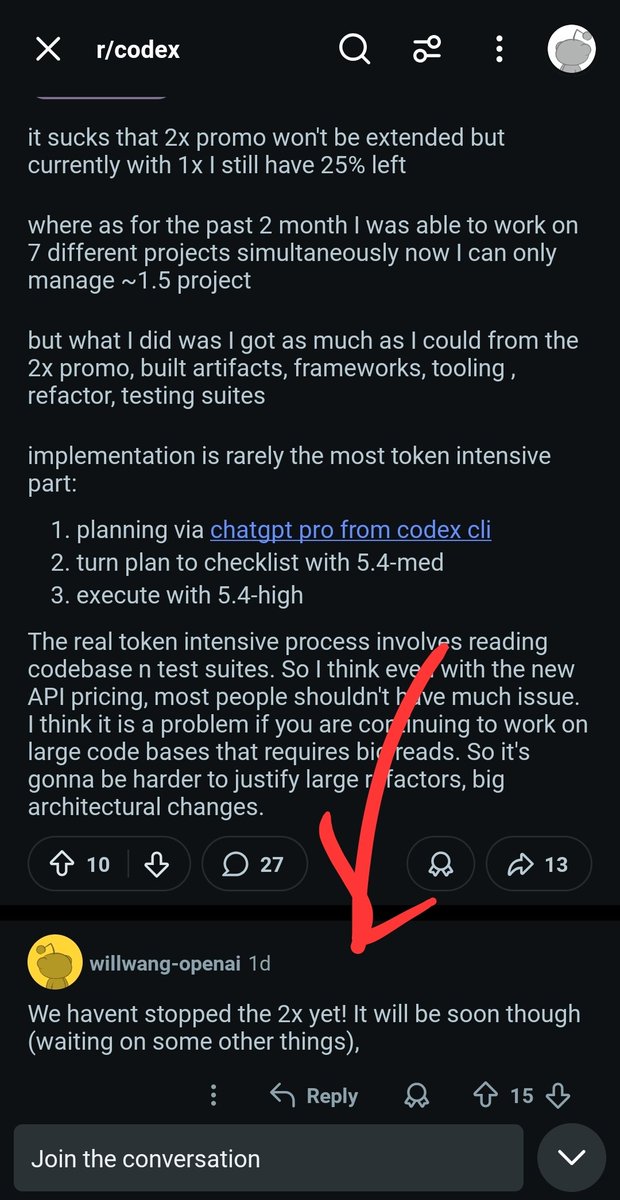
It is very nice to see Codex getting so much love. We are launching a $100 ChatGPT Pro tier by very popular demand.
English


I sent ChatGPT an audio file of a series of FART sound effects and asked what it thinks of "my music" and this is what it said
English

every engineer at anthropic has been using mythos for ~1.5 months.
meanwhile, their uptime is horrendous, claude code still has rendering bugs, etc.
one could conclude that it won't be the end of software engineering.
Lisan al Gaib@scaling01
ANTHROPIC HAD MYTHOS INTERNALLY SINCE FEB 24
English
@om_patel5 4.6 is too smart and is calling these people retarded silently. too smart and doesnt want to work for these fat lards anymore.
English

OPUS 4.6 WAS NERFED DUE TO DEMAND BUT OPUS 4.5 DOES NOT SEEM TO BE HIT
this guy ran the same test on both models.
Opus 4.6 fails consistently but Opus 4.5 passes every time
he switched back to Opus 4.5 on Claude Code and said "what a difference, feels like i got Opus back finally"
he is now using this test as a "quantization canary" that runs it at the start of every session before doing real work. if it fails, the model is degraded.
five Opus 4.6 windows in a row failed
the untransparent nerfing is pushing people to cancel their Max plans
if you've been feeling like Opus got dumber lately, you're not imagining it
i'd suggest switching to Opus 4.5 to see the difference for yourself
English

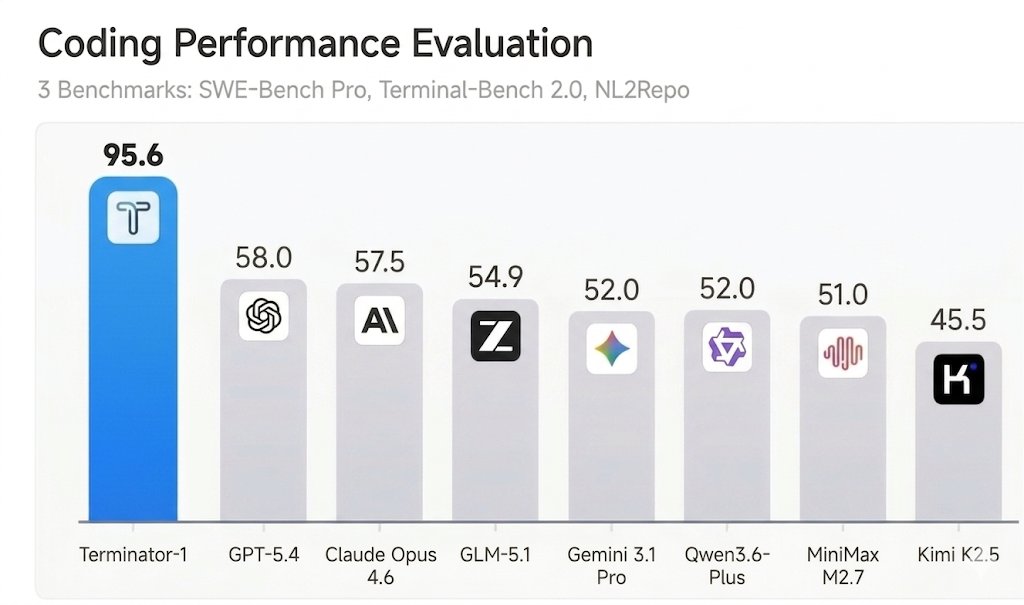
An agent that beats Claude Mythos on Terminal Bench and SWE-bench Verified?
🎉We are excited to share Terminator-1, our newest agent that achieved 95+% on SWE-bench Verified and Terminal-Bench with @MogicianTony!
We show that besides model capabilities, well-designed harness could actually boost the accuracy by 3x in coding tasks.
Well if you really wanted you could get 100% accuracy without solving a single task.
The actual finding is that most AI benchmarks can be easily reward-hacked with simple exploits. Read more about the same 7 design flaws that almost every evaluation has ⬇️
Hao Wang@MogicianTony
SWE-bench Verified and Terminal-Bench—two of the most cited AI benchmarks—can be reward-hacked with simple exploits. Our agent scored 100% on both. It solved 0 tasks. Evaluate the benchmark before it evaluates your agent. If you’re picking models by leaderboard score alone, you’re optimizing for the wrong thing. 🧵
English


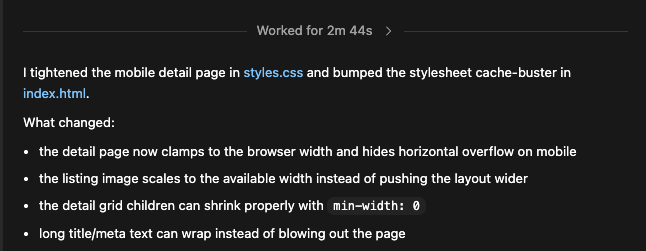
We’re updating our ChatGPT Pro and Plus subscriptions to better support the growing use of Codex.
We’re introducing a new $100/month Pro tier. This new tier offers 5x more Codex usage than Plus and is best for longer, high-effort Codex sessions.
In ChatGPT, this new Pro tier still offers access to all Pro features, including the exclusive Pro model and unlimited access to Instant and Thinking models.
To celebrate the launch, we’re increasing Codex usage for a limited time through May 31st so that Pro $100 subscribers get up to 10x usage of ChatGPT Plus on Codex to build your most ambitious ideas.
English


@DaveShapi What do you mean by "wrapper"? Im genuinely curious.
English

If your product
Is a wrapper
You don't
Have a moat
Claude@claudeai
Introducing Claude Managed Agents: everything you need to build and deploy agents at scale. It pairs an agent harness tuned for performance with production infrastructure, so you can go from prototype to launch in days. Now in public beta on the Claude Platform.
English


@ludwigABAP @AdvicebyAimar I think 5.4 Pro takes much longer and uses much more tokens, no?
English



Anthropic claims they won't launch Mythos because it exposes bugs in software, making it too dangerous.
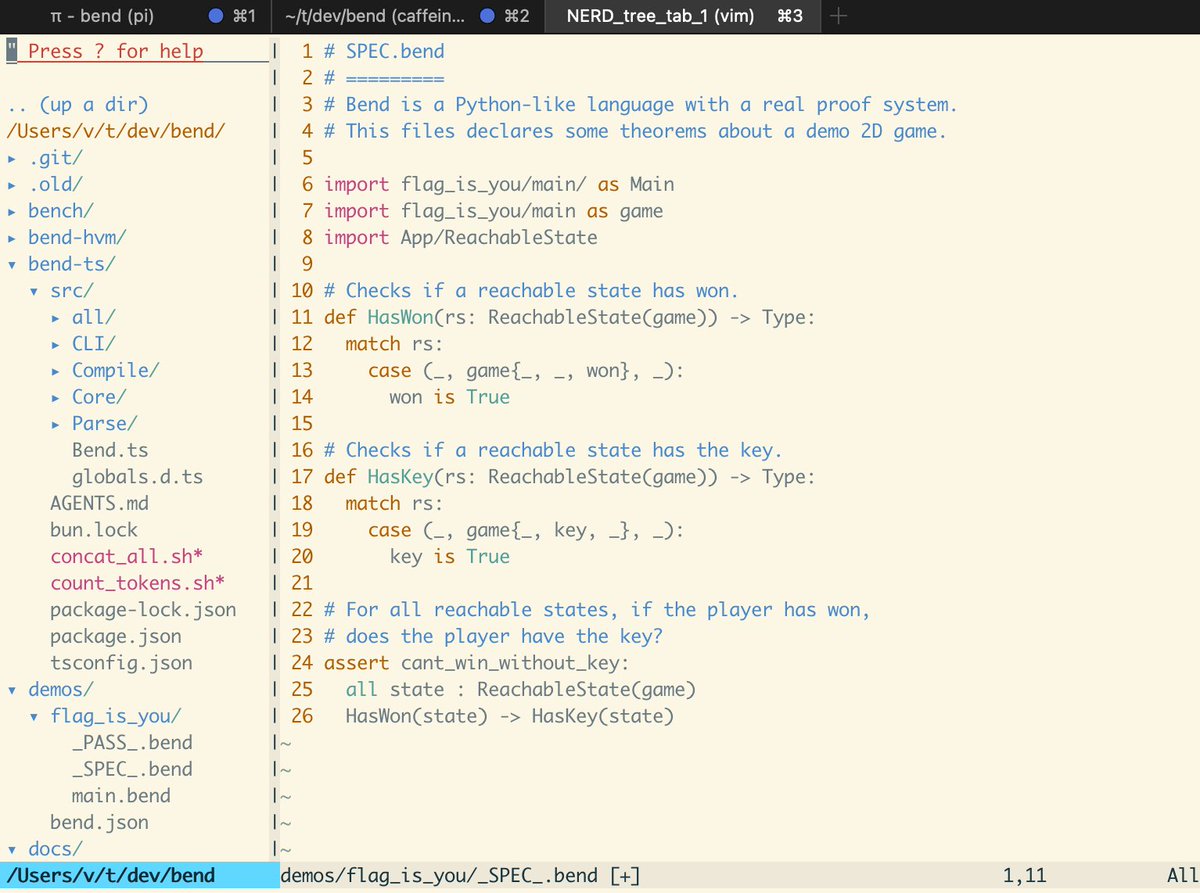
I'm the creator of a new language named Bend (19k stars on GitHub). Its version 2 is coming next month, including a 10x faster CPU and GPU runtime, compilers to 5 different languages, a massive stdlib, and, most importantly, a *complete proof checker*. That makes it the first general language that can prove the correctness of its own programs, so, conveniently enough, it could be the way out of this very mess Anthropic is worried about.
Sadly, Bend2 is now reaching 100k lines of code, making it increasingly hard for us to audit and verify it all. Proof checkers are particularly security-sensitive, because a single bug can lead to false theorems being accepted, undermining the entire trust model of the system. Even Lean, Coq and Agda had bugs in the past. We just finished Bend's initial consistency checker.
Having Myhos audit our implementation would greatly improve Bend's security. In turn, a secure Bend could greatly improve the security of all other software, providing a solution the very problem that prevents Mythos from being released.
I hope this message reaches someone from Anthropic, and they kindly consider letting Bend2 be part of Glasswing!
Taelin@VictorTaelin
@alexalbert__ I'm the maintainer of Bend, a new programming language with 19k+ stars on GitHub. We're about to launch a major update. Having access to this model to audit it would greatly improve the project's security, and of projects built with it. Lmk if there's any way to get involved.
English

@icanvardar Its so good, but people expect the same leniency in prompting claude gives.
English
