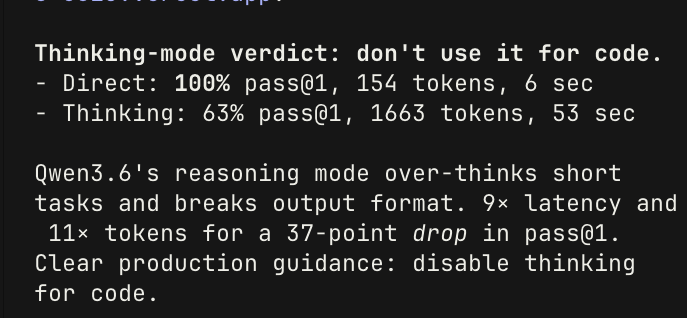
@jerrod_lew The setup is the real work. Once the system is locked, you're just running output. Same thing in fashion video production — months building the pipeline, now $0.63/video at scale. The hard part is always infrastructure, not the creativity after.
English