Закреплённый твит

Great that the data & code for Bangladesh mask RCT has been released gitlab.com/emily-crawford…. I tried to run their code and it seems there are only very small differences to what was reported in the paper.
English
Chao Wang
8K posts
@excel_wang
Associate Professor in health and social care statistics at Kingston University. PhD in econometrics.

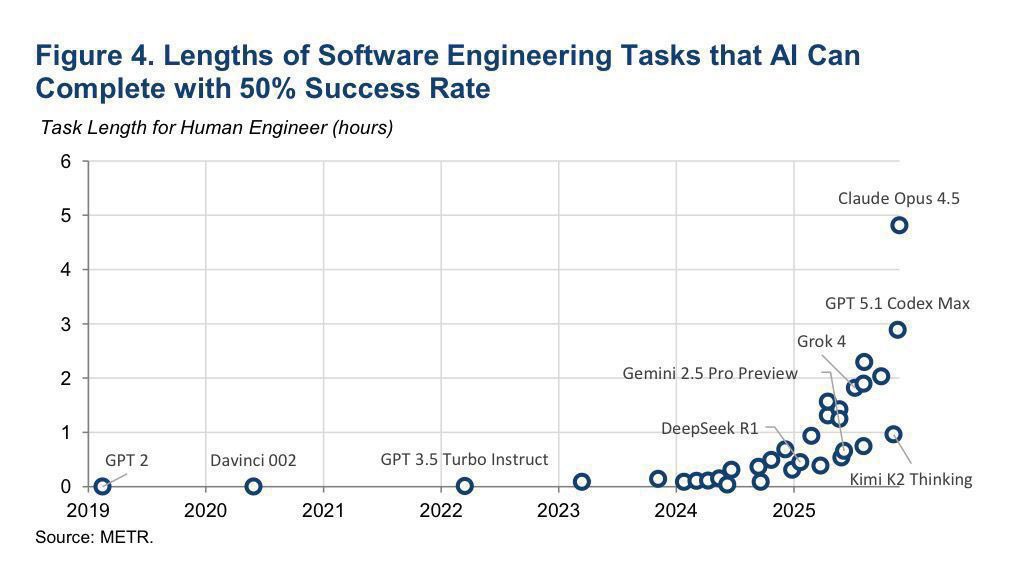
DeepSeek V4’s capability lags behind leading U.S. models by about 8 months. nist.gov/news-events/ne…



chinese models are ~8 months behind and are falling further behind



Tesco argues equal pay claim disregards ‘economic reality’ ft.trib.al/k5n8n5E
DeepSeek V4’s capability lags behind leading U.S. models by about 8 months. nist.gov/news-events/ne…

xAI has launched Grok 4.3, achieving 53 on the Artificial Analysis Intelligence Index with improved agentic performance, ~40% lower input price, and ~60% lower output price than Grok 4.20 The release of Grok 4.3 places @xAI just above Muse Spark and Claude Sonnet 4.6 on the Intelligence Index, and a 4 points ahead of the latest version of Grok 4.20. Grok 4.3 improves its Artificial Analysis Intelligence Index score while reducing cost to run the benchmark suite. Key Takeaways: ➤ Grok 4.3 improves on cost-per-intelligence relative to Grok 4.20 0309 v2: it scores higher on the Intelligence Index while costing less to run the full benchmark suite. Grok 4.3 costs $395 to run the Artificial Analysis Intelligence Index, around 20% lower than Grok 4.20 0309 v2, despite using more output tokens. This makes it one of the lower-cost models at its intelligence level ➤ Large increase in real world agentic task performance: The largest single benchmark improvement is on GDPval-AA, where Grok 4.3 scores an ELO of 1500, up 321 points from Grok 4.20 0309 v2’s score of 1179 Grok 4.3, surpassing Gemini 3.1 Pro Preview, Muse Spark, Gpt-5.4 mini (xhigh), and Kimi K2.5. Grok 4.3 narrows the gap to the leading model on GDPval-AA, but still trails GPT-5.5 (xhigh) by 276 Elo points, with an expected win rate of ~17% against GPT-5.5 (xhigh) under the standard Elo formula ➤ Grok 4.3’s performs strongly on instruction following and agentic customer support tasks. It gains 5 points on 𝜏²-Bench Telecom to reach 98%, in line with GLM-5.1. Grok 4.3 maintains an 81% IFBench score from Grok 4.20 0309 v2 ➤ Gains 8 points on AA-Omniscience Accuracy, but at the cost of lower AA-Omniscience Non-Hallucination Rate of 8 points, so Grok 4.20 0309 v2 still leads AA-Omniscience Non-Hallucination Rate, followed by MiMo-V2.5-Pro, in line with Grok 4.3 Congratulations to @xAI and @elonmusk on the impressive release!

American open source AI is in trouble. China is eating our lunch. This is a bigger problem than people realize.
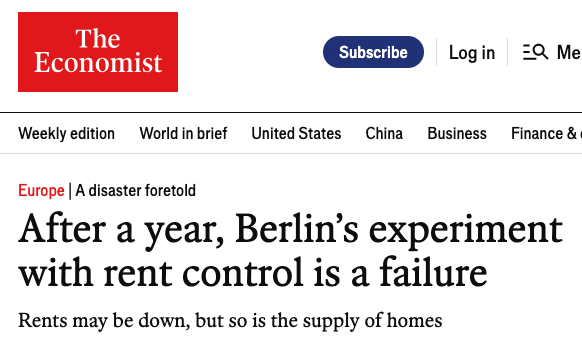

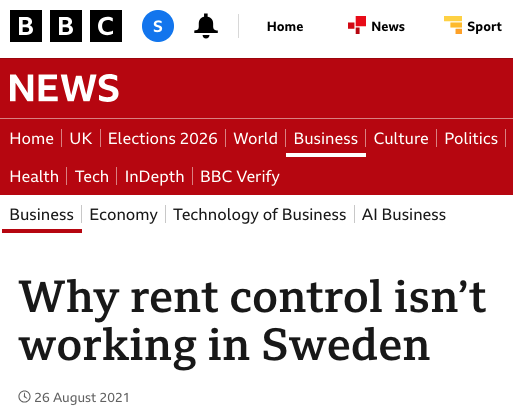

Labour are refusing to bring in rent controls which are common across Europe. End the affordability crisis. Introduce rent controls. Vote Green on 7th May 💚
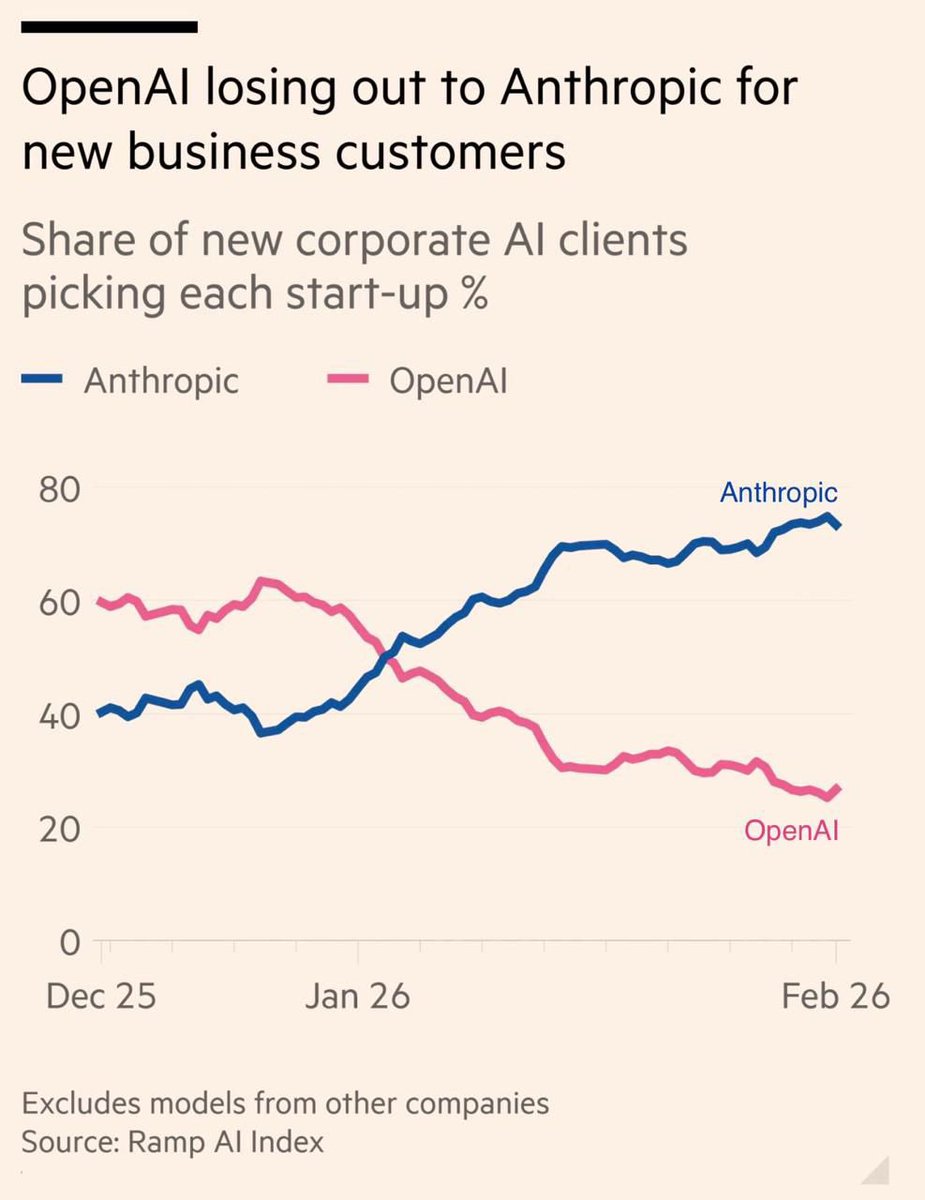
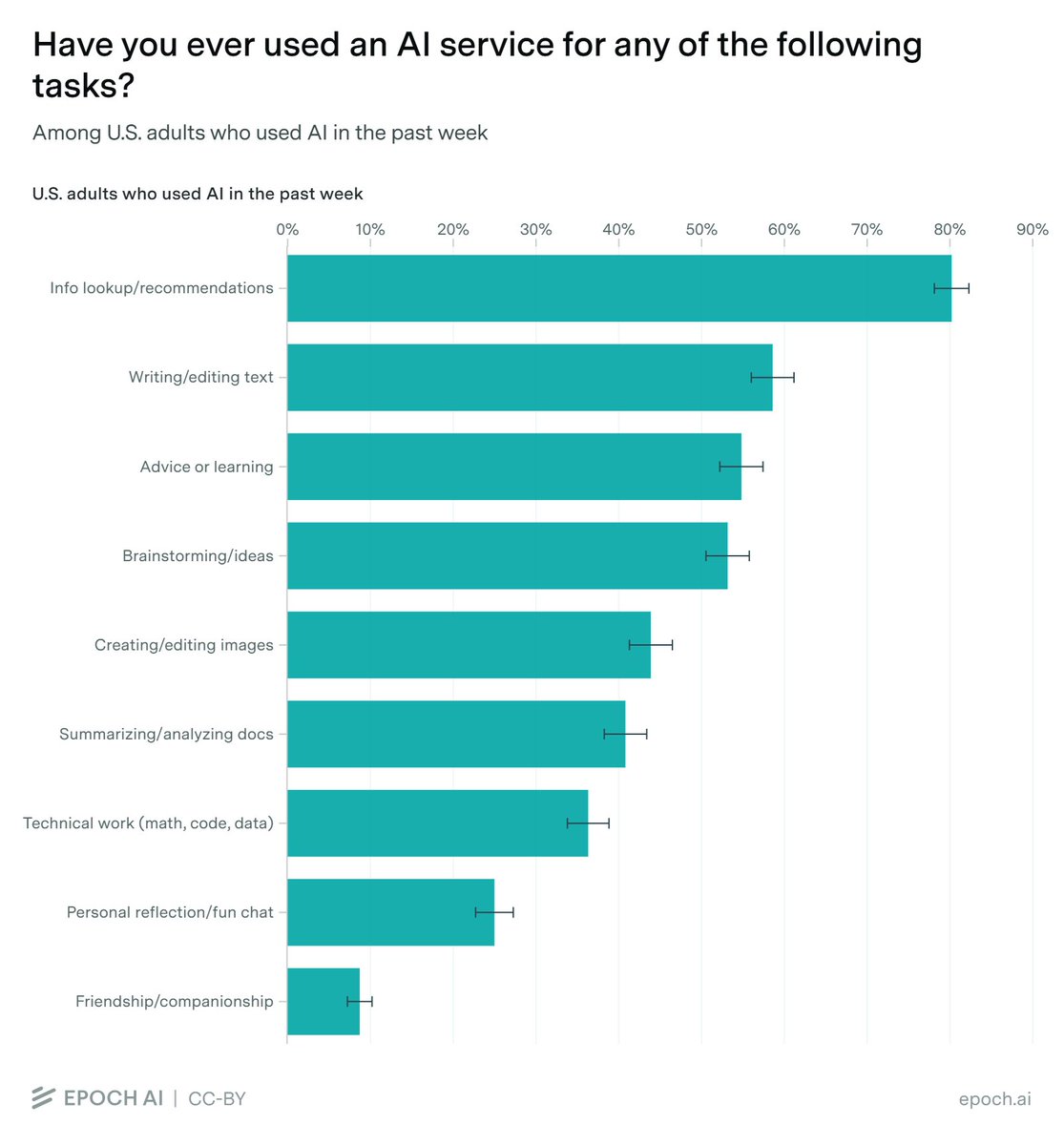
Among people in $100,000+ households, ChatGPT, Gemini, and Copilot all have more users than Claude. So while Claude’s user base tends to be high-income, the smaller number of Claude users overall means these users are still more likely to use services other than Claude.

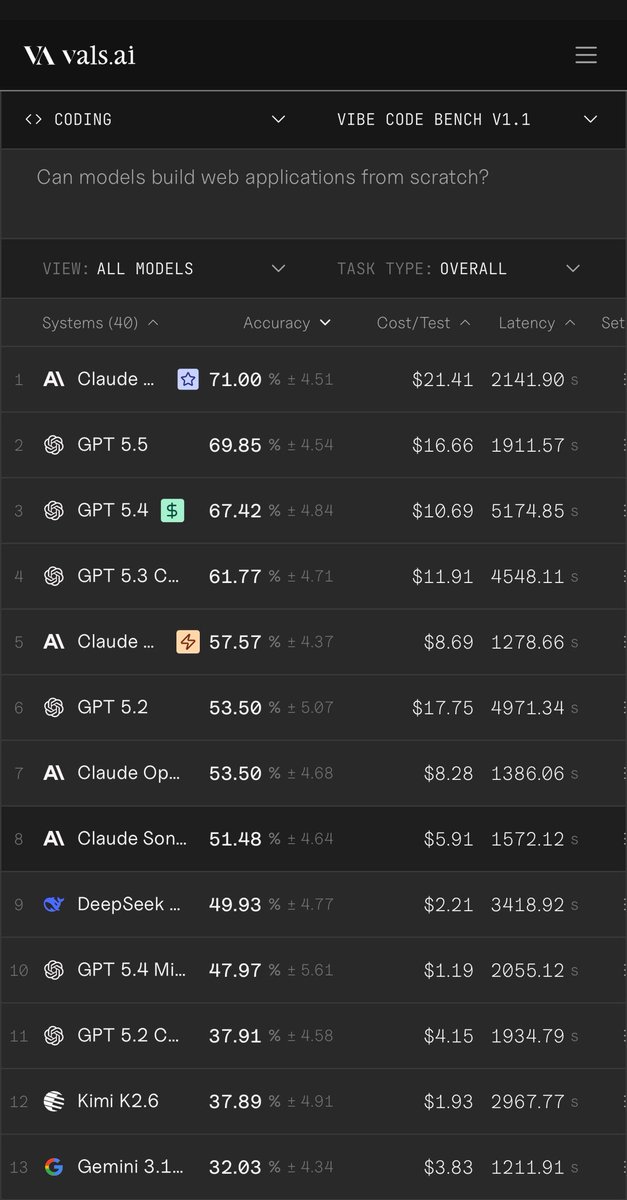
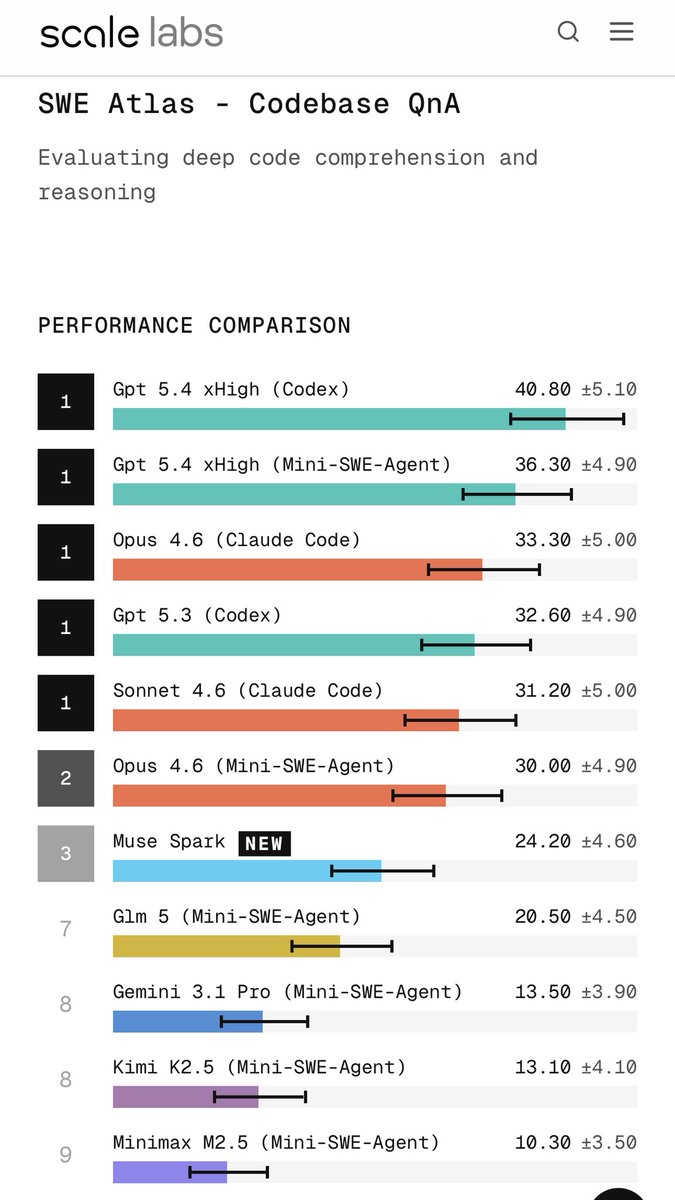





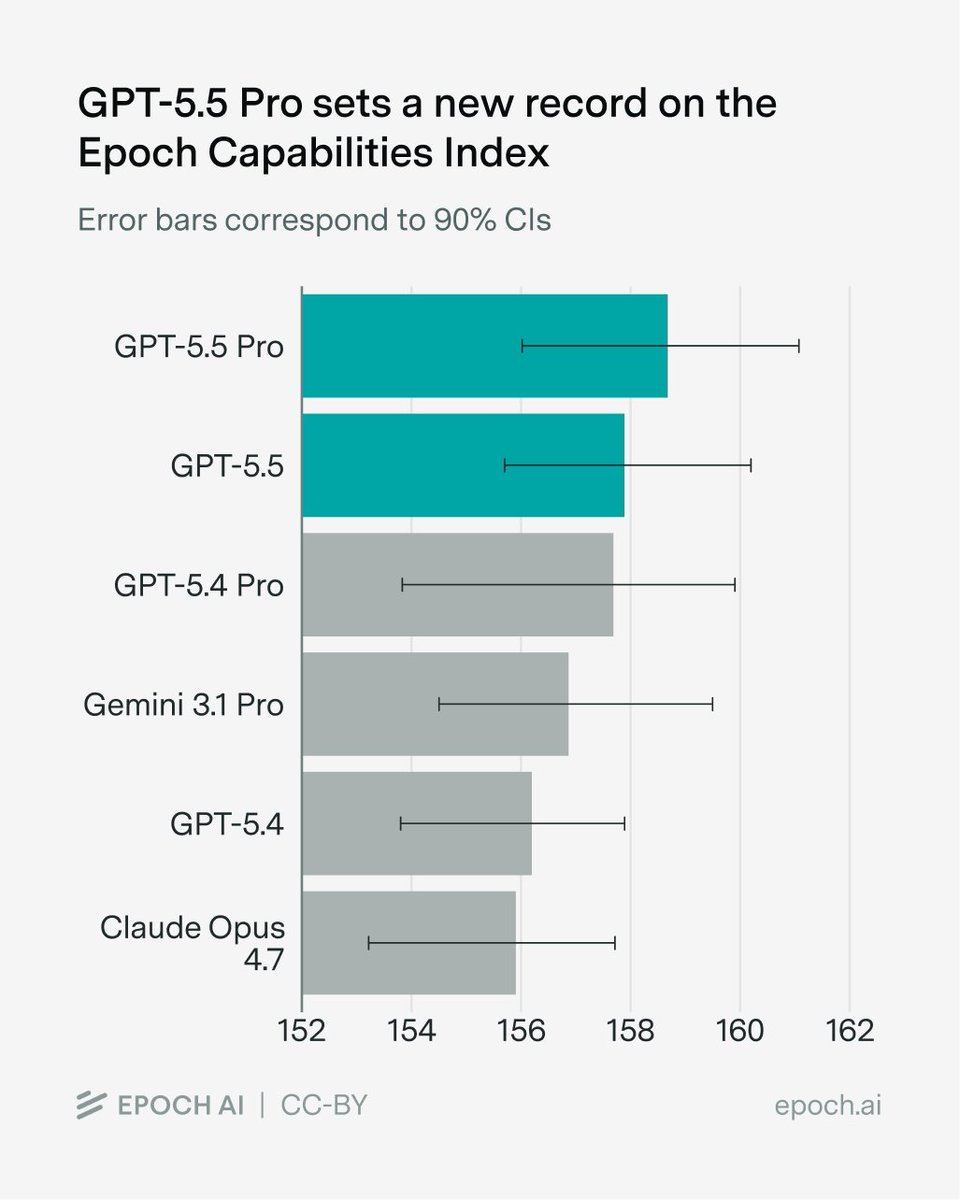
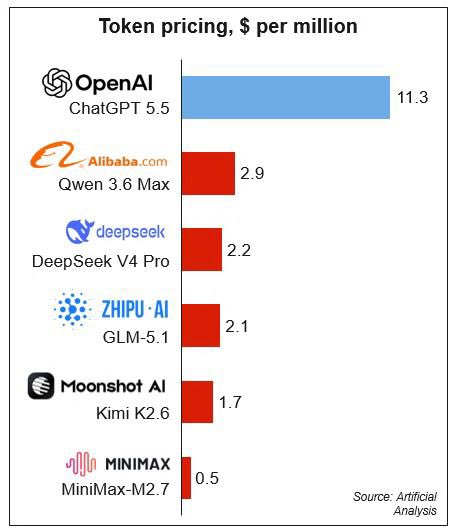
GPT-5.5 (xhigh) uses ~40% fewer output tokens to run our Index than its predecessor


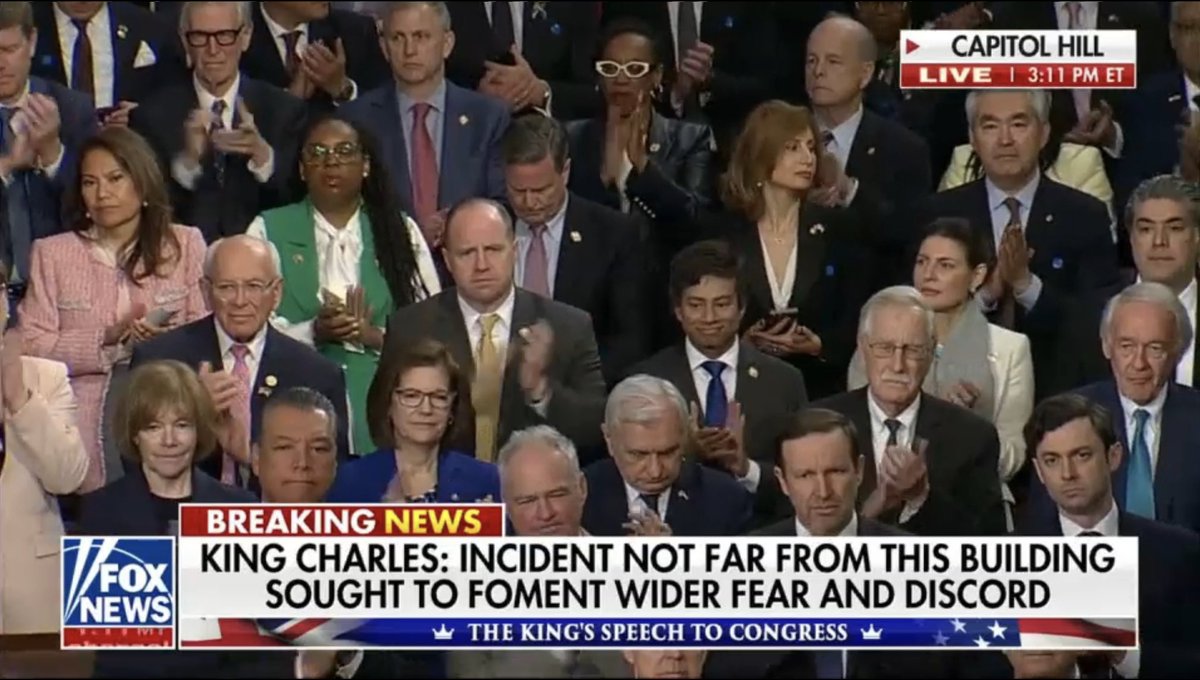
I've got nothing against King Charles personally—in fact, he seems like a decent and thoughtful man—but why the heck are we inviting the 77-year-old monarch of a medium-sized nation that committed something close to national suicide with Brexit to address a joint session of Congress? "Of more worth is one honest man to society," wrote Thomas Paine, "than all the crowned ruffians that ever lived." We are the nation that threw off a crowned ruffian and ended hereditary privilege to create a republic where the people rule. Happy 250th Birthday America.

UK 10y gilt yields back above 5%. At what point do we hit a crisis level?