Закреплённый твит

Went off-roading with a few CyberTrucks!
Impressed but not surprised when how easily these vehicles managed extremely challenging conditions 📐
Also, my first time shooting vehicles 😁📸




Toronto, Ontario 🇨🇦 English
Aakash Jhaveri🧑🏻💻ΛJ
22.8K posts

@jhaverinator
Events & Comms @Plugn_Drive + Journalist @AndroidPolice🕵🏻 Tech and EVs 😍 Trying to be net positive for the world🌏✨



I’m excited to announce a partnership with @Uber. As part of this, Uber plans to invest up to $1.25 billion in Rivian and deploy up to 50,000 R2 robotaxis. This partnership accelerates our path to Level 4 autonomy and supports our goal of building one of the safest autonomous platforms in the world—across both shared and personally owned vehicles. The combination of Rivian’s rapidly growing data flywheel, our in-house RAP1 inference platform (800 TOPS), and our multi-modal perception stack provides a powerful foundation to scale autonomy quickly and responsibly over the next couple of years.

A fleet of R2 Robotaxis is coming exclusively to @Uber. ⚡🌿 Today, we announced a partnership to help both companies accelerate their autonomous vehicle plans across 25 cities in the US, Canada and Europe by the end of 2031. rivn.co/uber



On this day in 2008: production starts for Tesla’s first vehicle, the Roadster.

Imagine designing an EV and having meetings about putting a start/stop button in an electric car 🤦♂️

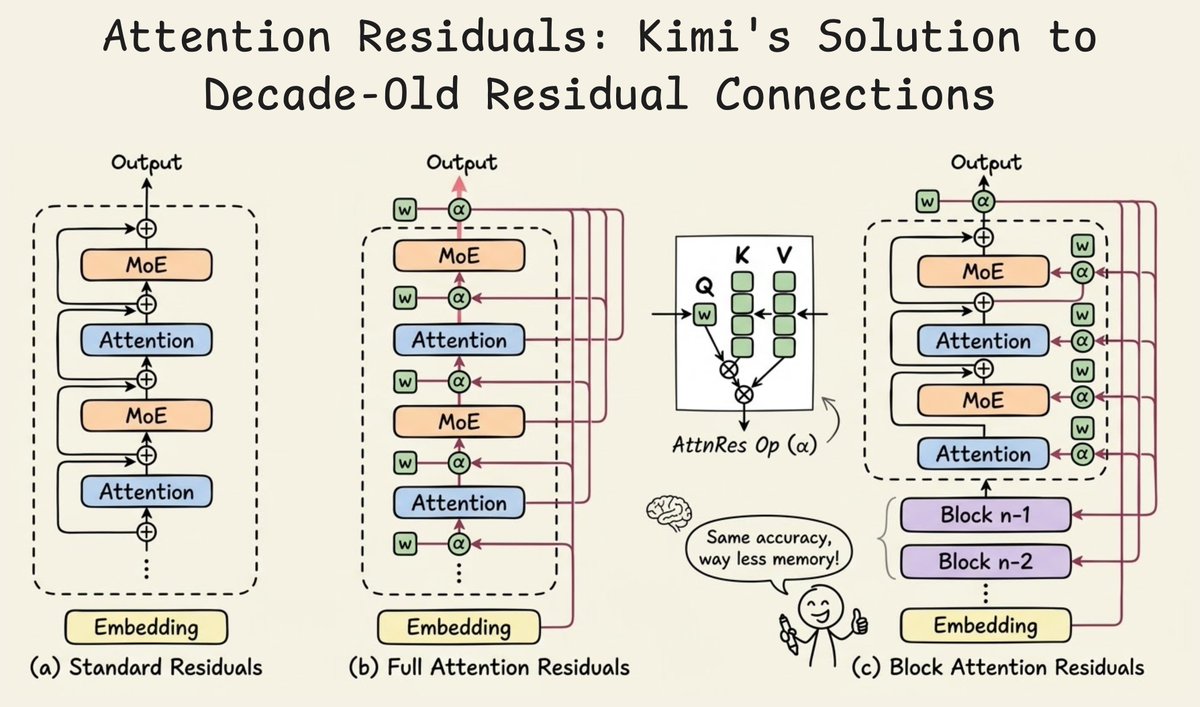
Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation. Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers. 🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth. 🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale. 🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead. 🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains. 🔗Full report: github.com/MoonshotAI/Att…