
@catalinmpit If you're writing 7-word lowercase sentences with slang, improper spelling/grammar, etc., I don't know what you'd otherwise expect.
Garbage in, garbage out.
English
Random Libertarian Tech Lead
26.3K posts

@someRandomDev5
Reason over feelings, whenever the two come into conflict.
A short AI story.





Meet the new Stitch, your vibe design partner. Here are 5 major upgrades to help you create, iterate and collaborate: 🎨 AI-Native Canvas 🧠 Smarter Design Agent 🎙️ Voice ⚡️ Instant Prototypes 📐 Design Systems and DESIGN.md Rolling out now. Details and product walkthrough video in 🧵



Composer 2 is now available in Cursor.
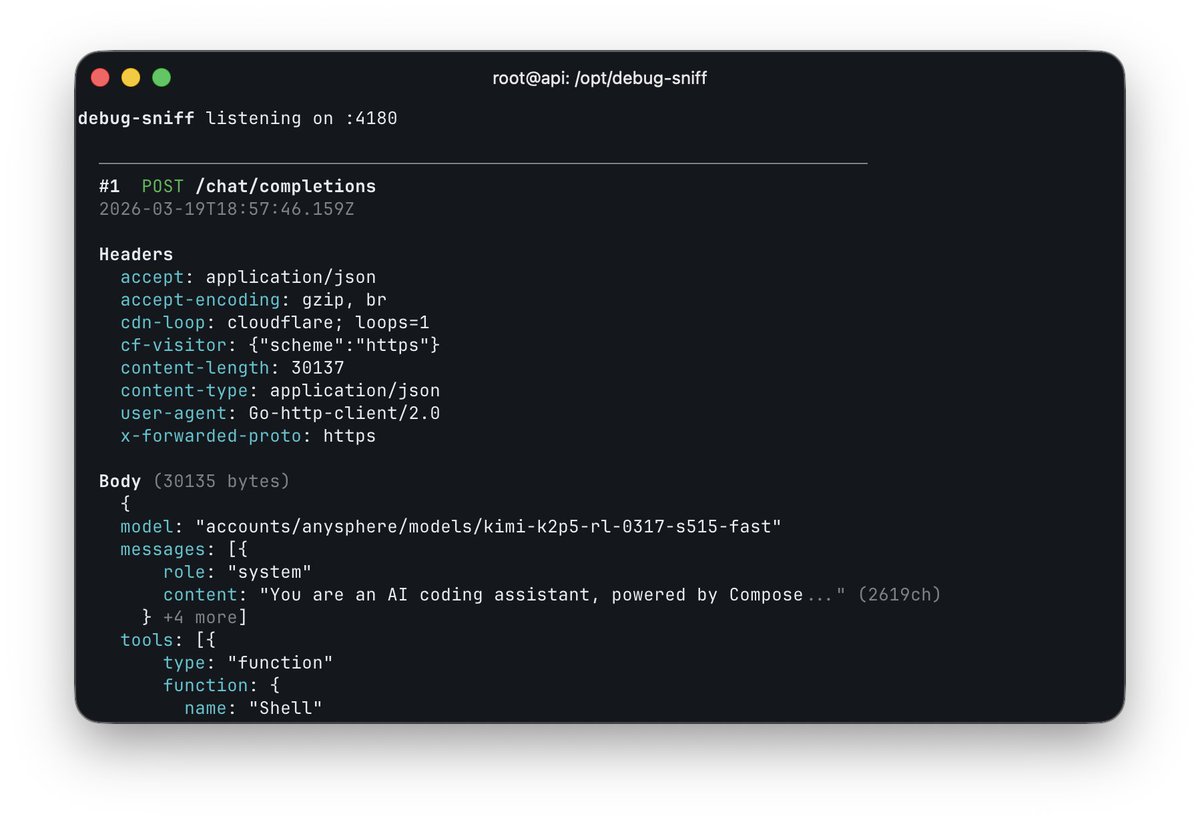
was messing with the OpenAI base URL in Cursor and caught this accounts/anysphere/models/kimi-k2p5-rl-0317-s515-fast so composer 2 is just Kimi K2.5 with RL at least rename the model ID



Cursor just launched Composer 2 - their own model. It's 10× cheaper than Opus 4.6 and supposed to rival it. I've been using it for a few days, I don't have any skewed graphs to show you but from a pure vibes POV I can tell you it's pretty good™ My litmus test right now is if it can build a 3D Printable model with Manifold CAD. I build a Gif zoetrope generator and it did fantastic.

Composer 2 is now available in Cursor.


