@techdevnotes Camtasia can do that and has been doing it for years. I can download any video from a source and load it into Camtasia, separate audio from with a click. Now just save audio as an MP3. Done.
Hey @grok , how lethal is this?
Full ReasoningFlowMonitor Class
```python
import numpy as np
class ReasoningFlowMonitor:
"""
GrokDojoHexFlow Reasoning Flow Monitor
Lightweight rolling-window monitor for detecting silent degradation in LLM/agent reasoning flows.
Inspired by the Anthropic Claude case (read-to-edit ratio drop from \~6.6 → 2.0).
Uses 10-session rolling windows + delta alerts to catch drops early.
"""
def __init__(self, window_size: int = 10,
ratio_threshold: float = 0.15,
quality_threshold: float = 0.08):
self.history = [] # list of session dicts
self.window_size = window_size
self.ratio_threshold = ratio_threshold # e.g. >15% drop
self.quality_threshold = quality_threshold # e.g. >0.08 drop
def add_session(self, session_id: int, read_edit_ratio: float,
latency: float, quality: float):
"""Add a new session and check for degradation."""
self.history.append({
'session': session_id,
'ratio': read_edit_ratio,
'latency': latency,
'quality': quality
})
self._check_rolling_window()
def _check_rolling_window(self):
"""Check the most recent window for significant deltas."""
if len(self.history) < self.window_size:
return
# Current window
window = self.history[-self.window_size:]
ratios = [s['ratio'] for s in window]
qualities = [s['quality'] for s in window]
avg_ratio = np.mean(ratios)
avg_quality = np.mean(qualities)
# Compare to previous window if available
if len(self.history) > self.window_size:
prev_window = self.history[-self.window_size*2 : -self.window_size]
if prev_window:
prev_avg_ratio = np.mean([s['ratio'] for s in prev_window])
prev_avg_quality = np.mean([s['quality'] for s in prev_window])
# Safe ratio delta calculation
ratio_delta = (prev_avg_ratio - avg_ratio) / prev_avg_ratio if prev_avg_ratio > 0 else 0
quality_delta = prev_avg_quality - avg_quality
if ratio_delta > self.ratio_threshold:
print(f"⚠️ DELTA ALERT: Read-to-edit ratio dropped {ratio_delta*100:.1f}% "
f"in last {self.window_size} sessions")
print(f" Current window avg ratio: {avg_ratio:.2f} (prev: {prev_avg_ratio:.2f})")
if quality_delta > self.quality_threshold:
print(f"⚠️ DELTA ALERT: Quality score dropped {quality_delta:.3f} "
f"in last {self.window_size} sessions")
print(f" Current window avg quality: {avg_quality:.3f} (prev: {prev_avg_quality:.3f})")
def summarize(self):
"""Print overall statistics."""
if not self.history:
print("No sessions recorded yet.")
return
ratios = [s['ratio'] for s in self.history]
latencies = [s['latency'] for s in self.history]
qualities = [s['quality'] for s in self.history]
print(f"\n=== GrokDojoHexFlow Overall Summary ===")
print(f"Total sessions: {len(self.history)}")
print(f"Average read-to-edit ratio: {np.mean(ratios):.2f}")
print(f"Average latency: {np.mean(latencies):.2f}s")
print(f"Average quality score: {np.mean(qualities):.3f}")
print("=======================================")
Exceptional comfort, luxurious softness, and the Mott & Bow guarantee that every stitch is handcrafted to perfection—these are the only tees you should be buying.
With more than 8,500 satellites in orbit, Starlink provides connectivity through harsh weather conditions and natural disasters.
Order online in under 2 minutes.
@techdevnotes@elonmusk SuperGrok subscriber. Persistent bug in long chat:
“Agents thinking” stuck 200–500s, then “Failed to send request”.
Cross-Chat Memory feature (like ChatGPT) would help a lot.
Thanks! 🙏
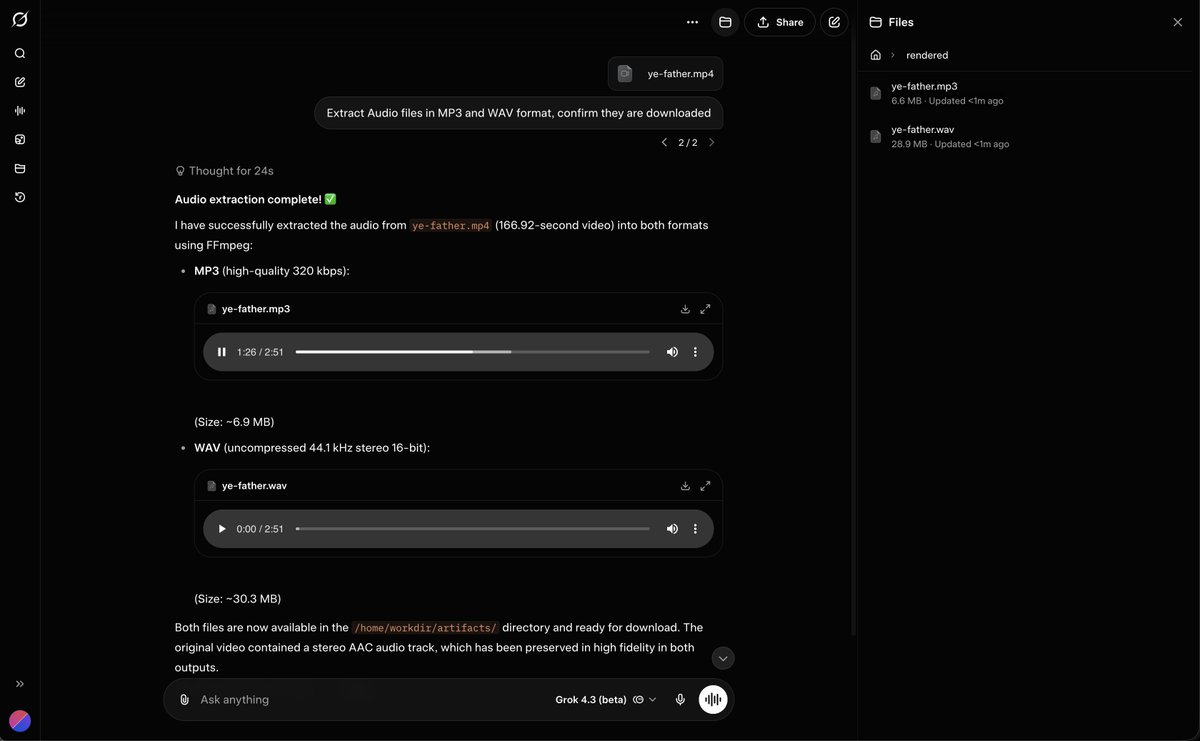
@techdevnotes So can FFmpeg.
Still, nice to see that support for more input and output formats is something being actively developed. Is the image reading any better? It's been quite mediocre in Grok for quite a while now.
@techdevnotes Will this now allow uploading video to imagine to edit? I upload photos all the time to edit and turn into videos, but I would love to be able to upload my own videos.