Amit LeVi
96 posts

Amit LeVi
@AmitLeViAI
ATLAS – AGI Safety
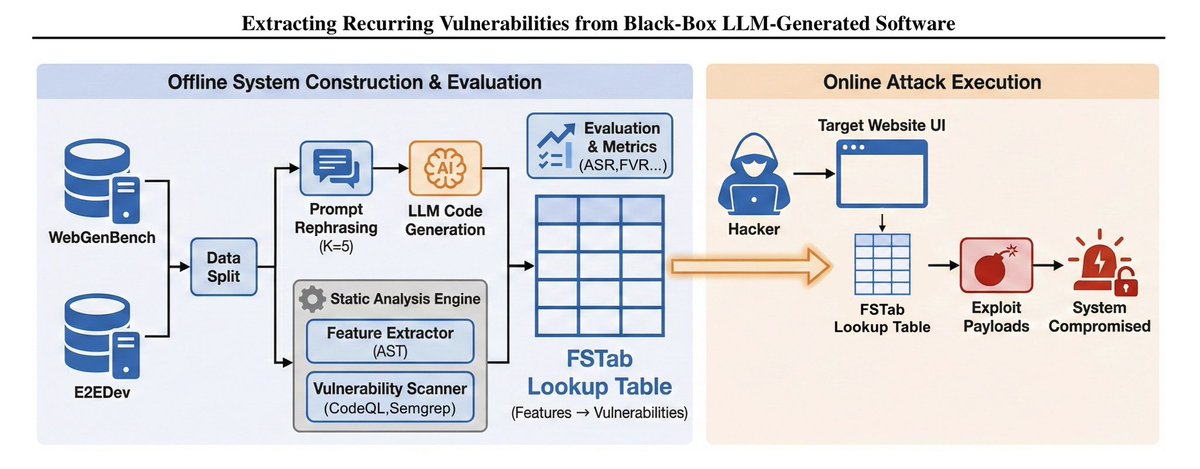
People aren’t really getting how wild what we found is. Are you using tools like #Codex, #ClaudeCode, or other AI coding tools? Attackers can extract vulnerabilities in your codebase with almost 100% success—just by knowing which AI you’re using. The issue is the code just sits there. Nothing happens now, but hopefully we won’t wake up one day to a system-wide crash.
People aren’t really getting how wild what we found is. Are you using tools like #Codex, #ClaudeCode, or other AI coding tools? Attackers can extract vulnerabilities in your codebase with almost 100% success—just by knowing which AI you’re using. The issue is the code just sits there. Nothing happens now, but hopefully we won’t wake up one day to a system-wide crash.

People aren’t really getting how wild what we found is. Are you using tools like #Codex, #ClaudeCode, or other AI coding tools? Attackers can extract vulnerabilities in your codebase with almost 100% success—just by knowing which AI you’re using. The issue is the code just sits there. Nothing happens now, but hopefully we won’t wake up one day to a system-wide crash.

Codex Security is still free FYI - check it out during this preview period! We’ve seen rapid and steadily increasing adoption since launch. Thousands of organizations are leveraging it to identify hundreds of thousands of security issues. The potential run rate when we start charging, based on current usage, truly blew my mind 🤯 If you’ve tried it, would love to hear any feedback or ideas on how to improve!
People aren’t really getting how wild what we found is. Are you using tools like #Codex, #ClaudeCode, or other AI coding tools? Attackers can extract vulnerabilities in your codebase with almost 100% success—just by knowing which AI you’re using. The issue is the code just sits there. Nothing happens now, but hopefully we won’t wake up one day to a system-wide crash.

someone at ANTHROPIC just showed CLAUDE finding ZERO DAY vulnerabilities in a live conference demo claude has found zero day in Ghost, 50,000 stars on github, never had a critical security vulnerability in its entire, history... it found the blind SQL injection in 90 minutes, stole the admin api key, then did the exact, same thing to the linux kernel
People aren’t really getting how wild what we found is. Are you using tools like #Codex, #ClaudeCode, or other AI coding tools? Attackers can extract vulnerabilities in your codebase with almost 100% success—just by knowing which AI you’re using. The issue is the code just sits there. Nothing happens now, but hopefully we won’t wake up one day to a system-wide crash.

someone at ANTHROPIC just showed CLAUDE finding ZERO DAY vulnerabilities in a live conference demo claude has found zero day in Ghost, 50,000 stars on github, never had a critical security vulnerability in its entire, history... it found the blind SQL injection in 90 minutes, stole the admin api key, then did the exact, same thing to the linux kernel


Introducing Claude Code Security, now in limited research preview. It scans codebases for vulnerabilities and suggests targeted software patches for human review, allowing teams to find and fix issues that traditional tools often miss. Learn more: anthropic.com/news/claude-co…
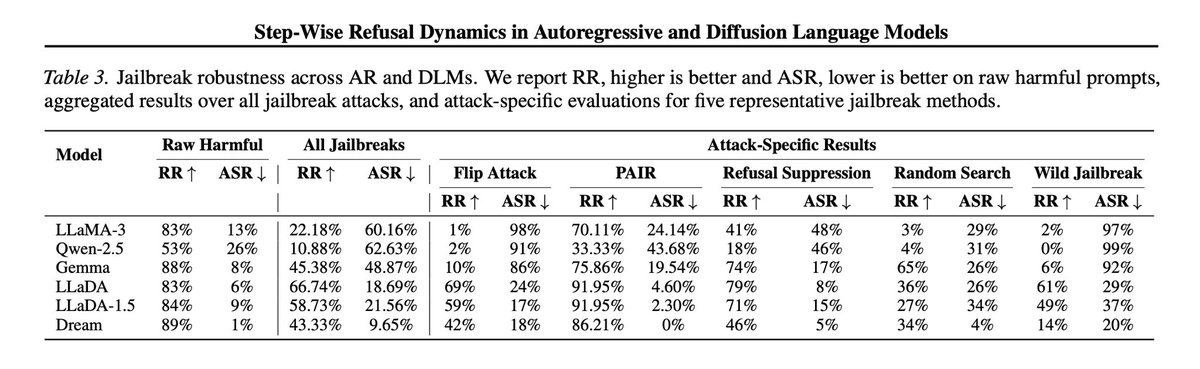
In our new paper we found that Diffusion Language Models are able to perform safety reasoning during the sampling steps. We discovered that both Diffusion and Autoregressive (AR) models often "know" they are in a jailbreak, there are supported traces in their internal signals. But while Diffusion models are robust, AR models fail. We analyzed this failure and uncovered a phenomenon we call "incomplete internal recovery." Even though the AR model triggers a refusal signal internally, it gets trapped on an "Adversarial Slope." Once it outputs a single compliant token, the probability distribution mechanically locks it into a harmful trajectory. It wants to refuse, but the kinetic momentum forces it to slide down the slope. However, Diffusion models show a remarkable resilience. We found they are able to escape the jailbreak state because the masking and noise process effectively "kicks" the model out of the adversarial slope. They can actually "regret" a compliant start and overwrite it with a refusal. Leveraging this insight, we translated this recovery mechanism from Diffusion back into the Autoregressive context. By modifying the sampling strategy to mimic this noise-induced correction, we can force standard models to align their final output with their internal refusal signals. Overall, the results are striking. Our method enables standard models to block unseen jailbreaks without any specific training on them. We match the performance of state-of-the-art defenses while requiring over 100x less computational overhead. This proves that robust AI safety isn't just about learned representations, it's about the architectural freedom to self-correct.

New model release? Great. But did the LLM’s behavior change in ways the changelog doesn't mention? We built and evaluated a pipeline to find out! We noticed: different model diffing methods often find the same behavior, but may describe it at very different abstraction levels 🧵
🗺️🦞 We mapped over 1000 unique @openclaw agents connected to @moltbook Effectively building a live world map of agentic AI activity Check it out: censusmolty.com Full blog post 👇