ทวีตที่ปักหมุด

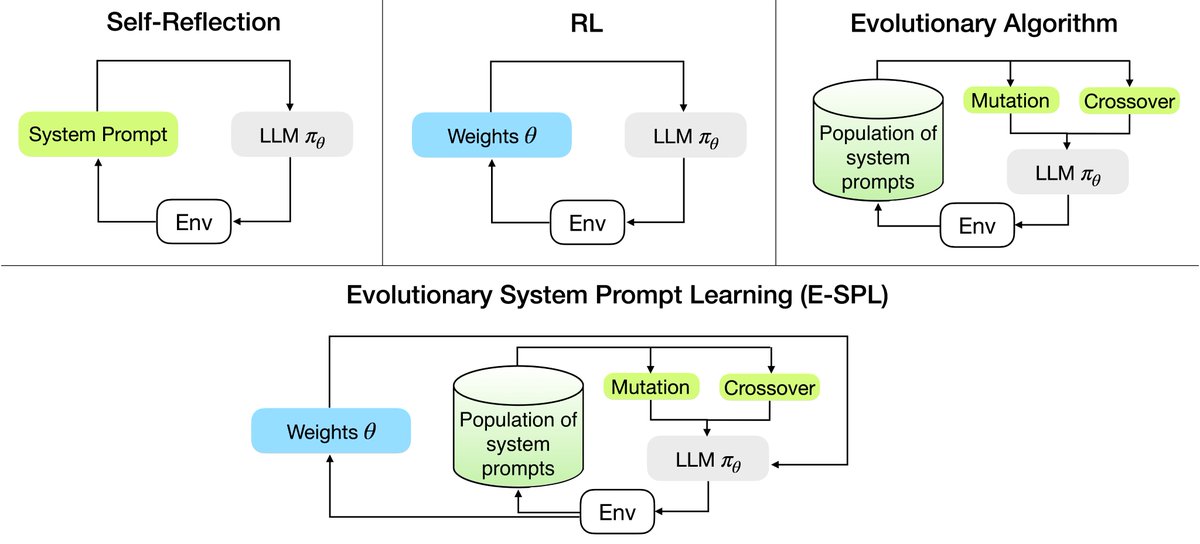
🧵 Your DiT, faster
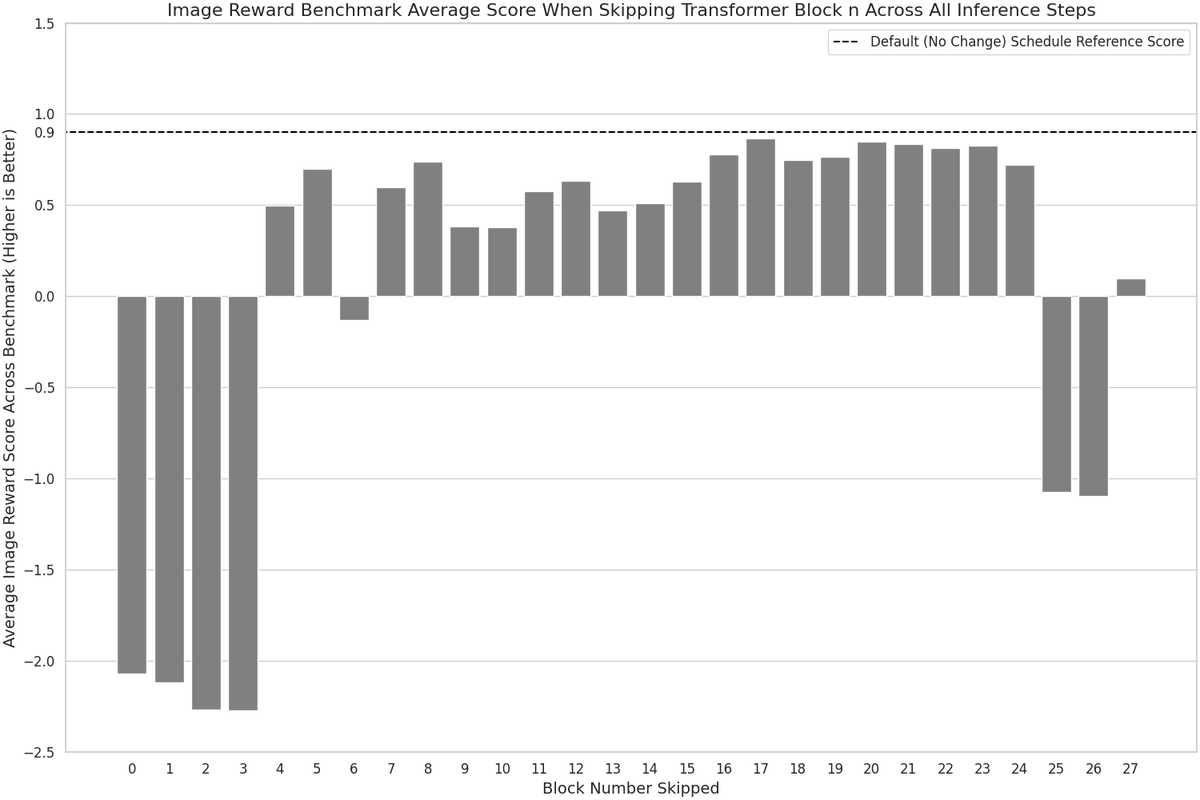
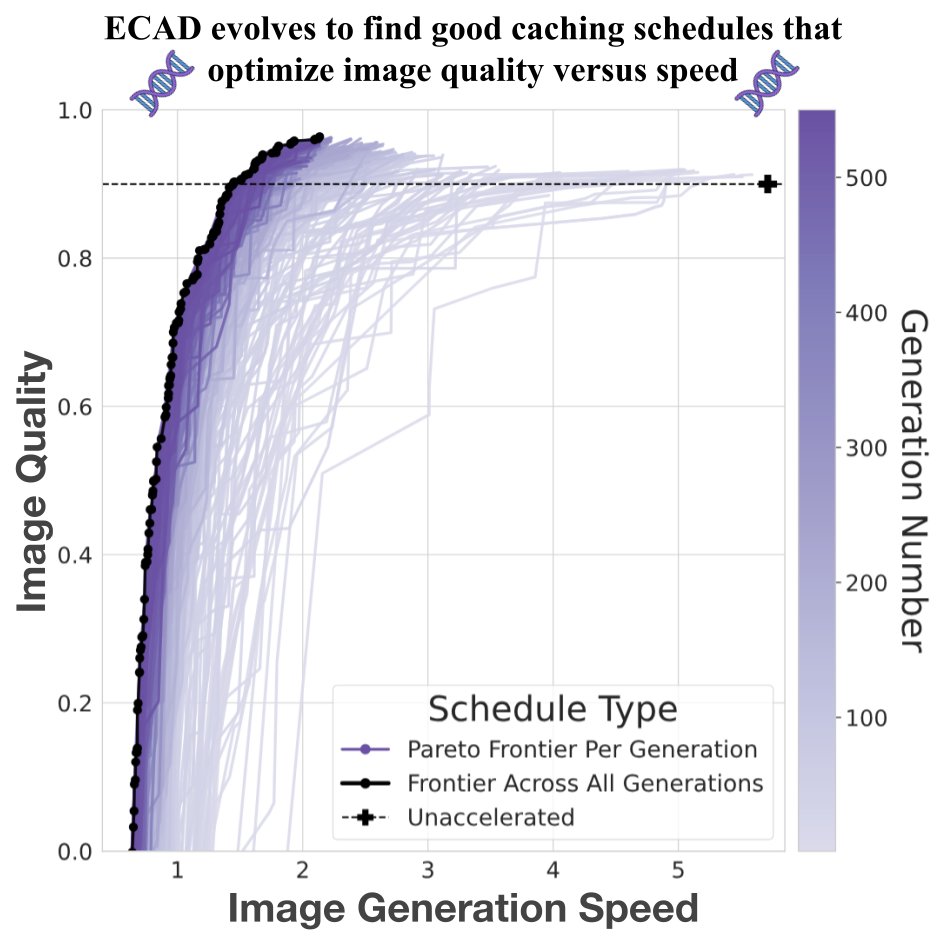
Introducing ECAD: we reframe diffusion model caching as multi-objective optimization and evolve Pareto-optimal schedules via a genetic algorithm—achieving 4.47 FID gain at 2.58× speedup, with no retraining or tuning.
🔗 aniaggarwal.github.io/ecad
#MachineLearning
English