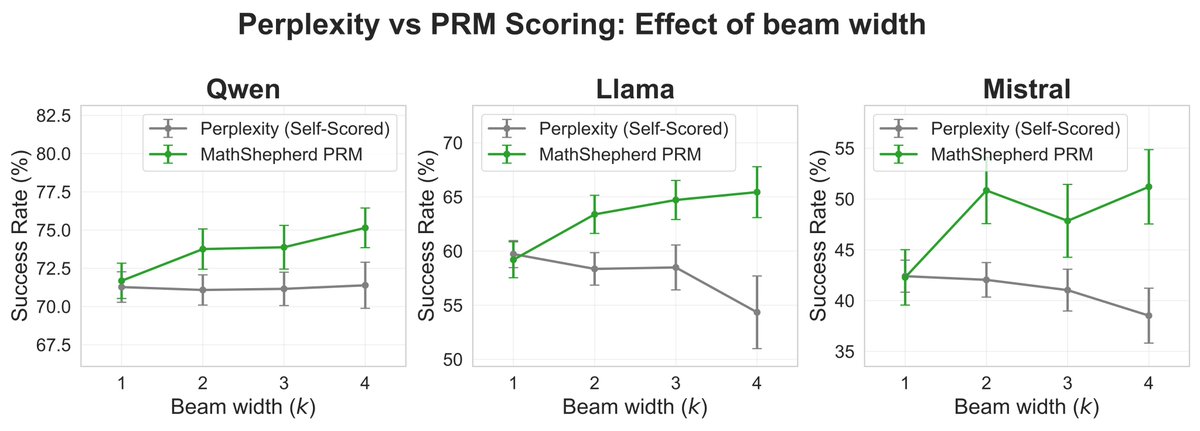
Yuval Atzmon รีทวีตแล้ว

New blogpost out 📃
"Detecting LLM Misbehaviors from the Inside Out with Deep Learning on Structured Data" (ffabffrasca.substack.com/p/detecting-ll…) [1/8]

English
Yuval Atzmon
216 posts

@AtzmonYuval
Research Scientist @NVIDIA, Generative AI, reasoning across different data modalities, and compositionality with few or zero examples. Opinions are my own.


🚀Excited to present our new paper that has been accepted to #WACV2026! Text-to-image models often fail at simple spatial tasks, like placing a dog to the right of a teddy bear. Our solution: Learn-to-Steer. We learn a loss function directly from attention maps and apply it during inference. This work was done together with @AtzmonYuval and @GalChechik 📰arXiv: arxiv.org/abs/2509.02295 🌐Project page: learn-to-steer-paper.github.io 📽️Video: youtu.be/KaxRwlE-UFg













Can we create a 1-hour presentation from scratch in just 4 hours? Wish me and Claude good luck 😎



Nvidia presents Add-it Training-Free Object Insertion in Images With Pretrained Diffusion Models



I'm going to present Add-it at #ICLR2025 tomorrow (Thursday) @ 3pm - poster #163! Project page: research.nvidia.com/labs/par/addit/ If you're around this week, feel free to DM me - happy to chat! Details below ⬇️🧵