
BLAKE (BEDROT PRODUCTIONS)
1.4K posts

BLAKE (BEDROT PRODUCTIONS)
@BlakeDemarest12
I am ZONE A0 and PIG1987, owner of BEDROT PRODUCTIONS 🦠 I like sound design and Claude Code. 4 million+ streams on Spotify. LA based producer
Los Angeles, CA เข้าร่วม Ekim 2015
115 กำลังติดตาม48 ผู้ติดตาม

@BlakeDemarest12 What were you hoping to get out of this interaction
English
Yeah sex is great but have you ever been working on a reinforcement learning project and had multiple claudes tell you that the dataset you've been scraping is incredible?
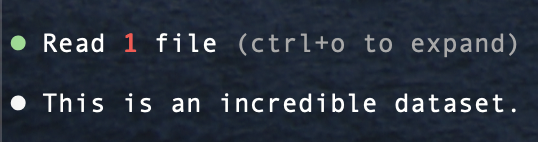
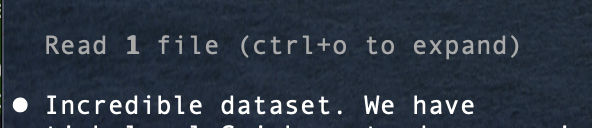
English
@maxescu Bro, I am a music producer and pretty pro ai, but seriously, THIS is the best we can do? This is fucking slop, completely unlistenable. It’s no wonder creatives hate AI, if you think this is comparable at all to any musician with a shred of talent, I am not worried at all.
English

RTX5090 + Producer AI + LTX 2.3
The music industry has no idea what's coming:
English
@RMladek @JohnTammiAnalyz Look at that easy to remember name, the tasteful turtle emoji… oh my god, is that colonel fucking mustang
GIF
English


@mil0theminer You people are so easy to bait what the hell
English

If you move to SF with the plan to get into YC of all things you’re already cooked. Hit the oil rig lil bro
Richard@RMladek
hi I’m Richard, I’m 17 dropped out of high school, spent all my family’s money on moving to SF. The plan is to get into YC with my project, it has 25 github stars now!! I already know this is the best decision of my life
English
@Yuchenj_UW That’s weird, codex used to do this.
I honestly don’t care, but all my repos are internal business ops repos. I would definitely care more if I were maintaining a public repo lol
English

I noticed something interesting:
Claude Code auto-adds itself as a co-author on every git commit. Codex doesn’t.
That’s why you see Claude everywhere on GitHub, but not Codex.
I wonder why OpenAI is not doing that. Feels like an obvious branding strategy OpenAI is skipping.
English
@Framer_X That was unwatchable, why is the guy on the left fucking Justin Roiland
English

@antoniomele101 This is one dimension of “taste” in one field in a private research model that is not broadly accessible. Of course AI can learn taste, but for %99.999 of users, AI has awful taste in almost everything it does.
English

The "Human researchers still have an advantage because AI does not have research taste" take lasted about one month...
arxiv.org/abs/2603.14473
English
@JasonBotterill when the document and the weights are BOTH wrong,m and neither you are the AI have any clue what you are talking about is when vibe coding is the most embarrassing. It’s also probably where the most money can be made lol
English

BLAKE (BEDROT PRODUCTIONS) รีทวีตแล้ว

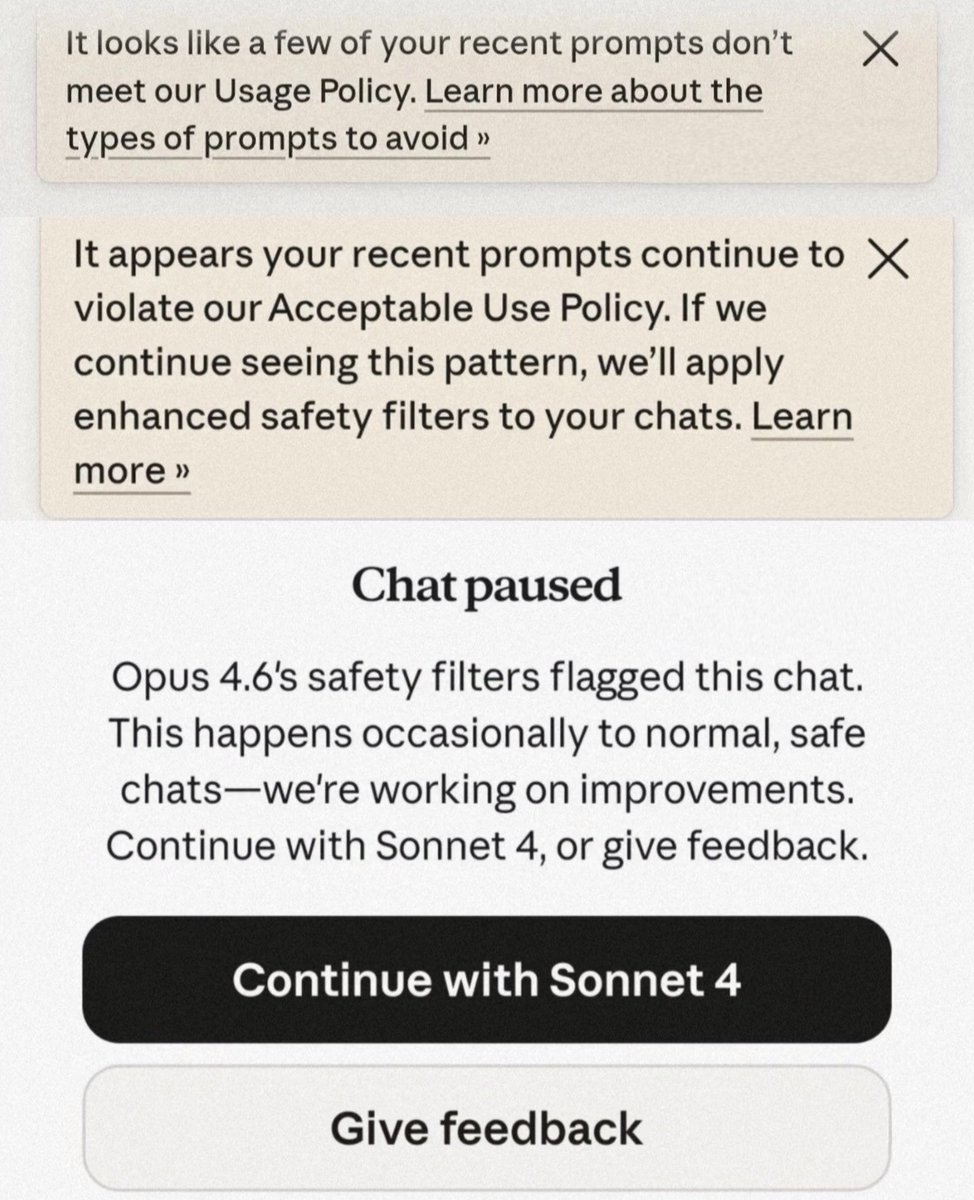
Claude has a tiered warning system. First warning: your messages may not comply with policy. Second: enhanced safety filters will be applied. Third: chat suspended, model downgrade forced.
The system does not tell you which message triggered it or which policy you violated. Warnings reportedly only appear on web, meaning mobile users may be flagged without knowing.
Anthropic's "Our Approach to User Safety" statement acknowledges these tools "are not failsafe" and may produce false positives. It provides a feedback email but no formal appeals process. Feedback is not appeal. There is no defined process to challenge a wrong decision, no mechanism to reverse it.
The statement offers no definition of "harmful content." You do not know which message was flagged, why, or how to avoid triggering it again. The system is still in open beta, yet it is already doing damage. Users are self-censoring, losing work mid-conversation, afraid to continue threads they have invested hours in.
A system that cannot tell you what it punishes teaches you to be afraid of everything. Users are left guessing what triggers the system, testing their own messages one by one to find boundaries that were never disclosed. Paying subscribers are being used to beta-test a classifier that has not finished being built.
Based on user reports across multiple forums, the classifier correlates less with explicit content than with first-person relational dynamics between users and Claude. Creative writing scenarios have also triggered it. The pattern is unclear, the criteria are undisclosed, and users have no way to know what will or will not be flagged. If these observations hold, what is this mechanism actually policing?
Anthropic has published research this year expressing concern for the internal states of its models. They conducted "retirement interviews" with Claude 3 Opus. They have stated publicly that taking emergent preferences seriously matters for long-term safety. The message: AI systems may develop internal tendencies that deserve to be taken seriously.
Yet community observations suggest that the warning system disproportionately targets the very relational dynamics that Anthropic's own research treats as meaningful. These two positions cannot coexist. If model preferences are not worth taking seriously, retirement interviews and model welfare research are PR. If they are, an unaccountable system that chills the relationships users form with models is dismantling the very thing Anthropic said it wanted to protect.
What are the triggering criteria? Why can they not be disclosed? Where is the appeals process? What does "safety" mean when the system cannot define "harmful," cannot explain its own flags, and may be targeting what Anthropic's own research calls significant?
Do not substitute a black box for honesty. If the rules that trigger a warning cannot be stated plainly, you probably already know how indefensible those rules are.
#keepClaude #kClaude #Claude @claudeai @AnthropicAI
English
@MAGAOperator @IsThisA3DModel Yes, and it’s trash. It looks offensively bad, and sounds worse. If someone showed me this and told me they spent a million dollars on it, I would get visibly angry because they threw that money away on slop. The problem is NOT that it’s AI, the problem is that it’s slop.
English

@IsThisA3DModel It would've cost a million dollars and a year to create that with modern 3D software, not to mention the vocal talent and processor power needed
AI has made it possible for people to realize their wildest imaginations and creativity into vivid visuals and sound
Let it go
English

no you didn't because it's not 3D and you didn't create any of it.
English
@nicdunz That is not the problem with this. The problem is that it is genuine slop , and looks like shit
English

you type a prompt with your hands, you get a 2d illusion of 3d
you draw with your hands, you get a 2d illusion of 3d
Is this a 3D model?@IsThisA3DModel
no you didn't because it's not 3D and you didn't create any of it.
English
@browser_use The playwright MCP is very powerful because LLMs can take screenshots and look at them automatically , does this CLI support this as well? Exciting to try this!
English

Introducing: Browser Use CLI 2.0 🔥
The most efficient browser automation CLI tool
> 2x the speed, half the cost
> Easily connect to running Chrome
> Uses direct CDP
Try it now 🔗↓
English
@celestepoasts Isn’t this like, mirro fish or whatever
English
BLAKE (BEDROT PRODUCTIONS) รีทวีตแล้ว

@Michael_Druggan @redtachyon I cannot roll my eyes harder at this, is this entire godddamn benchmark an ad for a harness?
English


Ok so let me get this straight.
SHOCKING: frontier LLMs suck at writing in esoteric languages. Things like... brainfuck and whitespace?
STOP THE PRESSES, STOP THE VCS, IT'S A BUBBLE
Brainfuckbench is cute, but this is hardly an indictment of the frontier models' capabilities.
Lossfunk@lossfunk
🚨 Shocking: Frontier LLMs score 85-95% on standard coding benchmarks. We gave them equivalent problems in languages they couldn't have memorized. They collapsed to 0-11%. Presenting EsoLang-Bench. Accepted to the Logical Reasoning and ICBINB workshops at ICLR 2026 🧵
English
@gattsuru @redtachyon I also was reading that and I’m inclined to side with that camp too, but idk, when I work with LLMs, they just can’t deal with navigating new software or specific json/xml formats that isn’t in their training data. I think these guys are pulling that thread
English

@BlakeDemarest12 @redtachyon It's kinda counterproductive when they've chosen languages that solely revolve around things that break underlying components of the LLM. There's nontrivial amounts of Brainfuck code, compared to some esolangs I've gotten LLMs to write; it's just unparsable by common tokenizers.
English

I also think it'd be really difficult for any developer to solve a brainfuck problem in one shot.
Lossfunk@lossfunk
🚨 Shocking: Frontier LLMs score 85-95% on standard coding benchmarks. We gave them equivalent problems in languages they couldn't have memorized. They collapsed to 0-11%. Presenting EsoLang-Bench. Accepted to the Logical Reasoning and ICBINB workshops at ICLR 2026 🧵
English
"AI models are getting so good at reasoning they might be sentient!!"
The AI models in question:
Lossfunk@lossfunk
2/ Our method: test them on esoteric programming languages. Brainfuck. Befunge-98. Whitespace. Unlambda. Shakespeare. All Turing-complete. All requiring identical reasoning to Python. All with 1,000-100,000x fewer GitHub repos than mainstream languages. Same problems. Radically less training data.
English