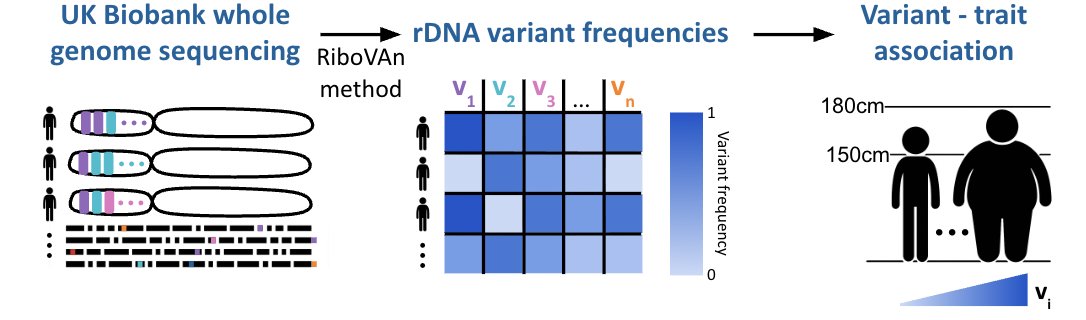
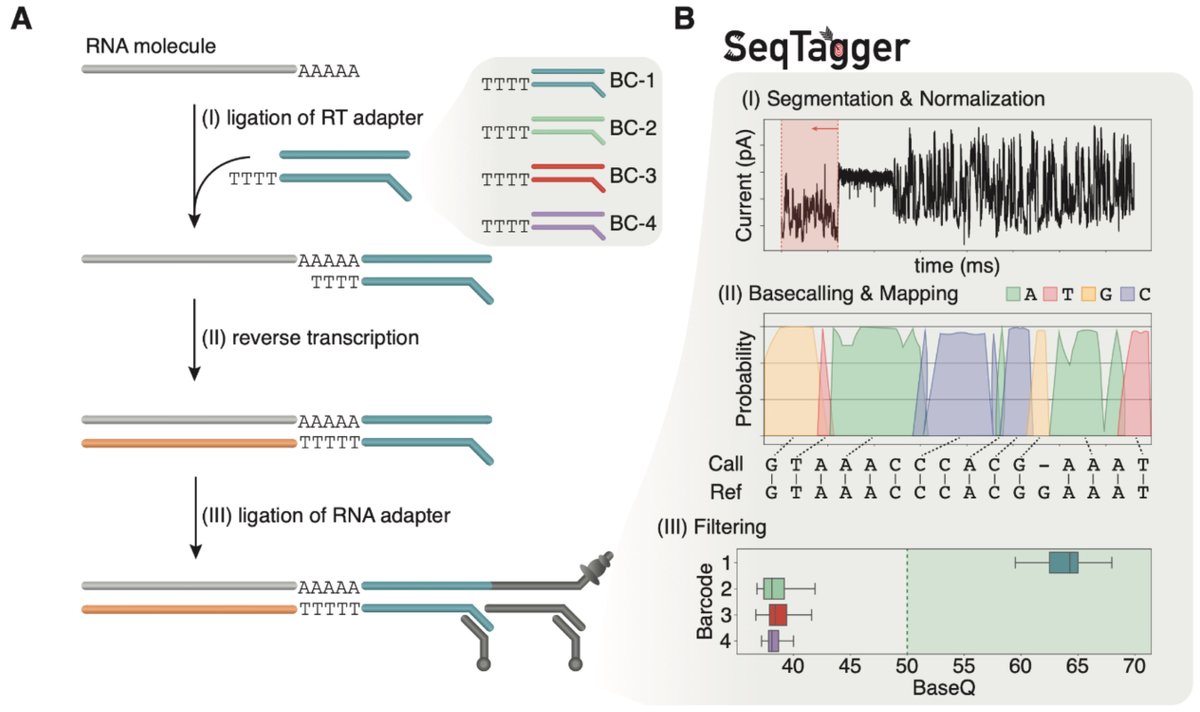
New #preprint from our @NovoaLab! We develop tRIBO-seq, a nanopore method to sequence ribosome-associated #tRNAs and track how the active tRNA pool changes across #stress conditions. Wonderful collaborative effort with #immaginaBiotech and #SoaresLab! biorxiv.org/content/10.648…
English