
FI𝕊HΞRY Isla
1.5K posts


FI𝕊HΞRY Isla รีทวีตแล้ว

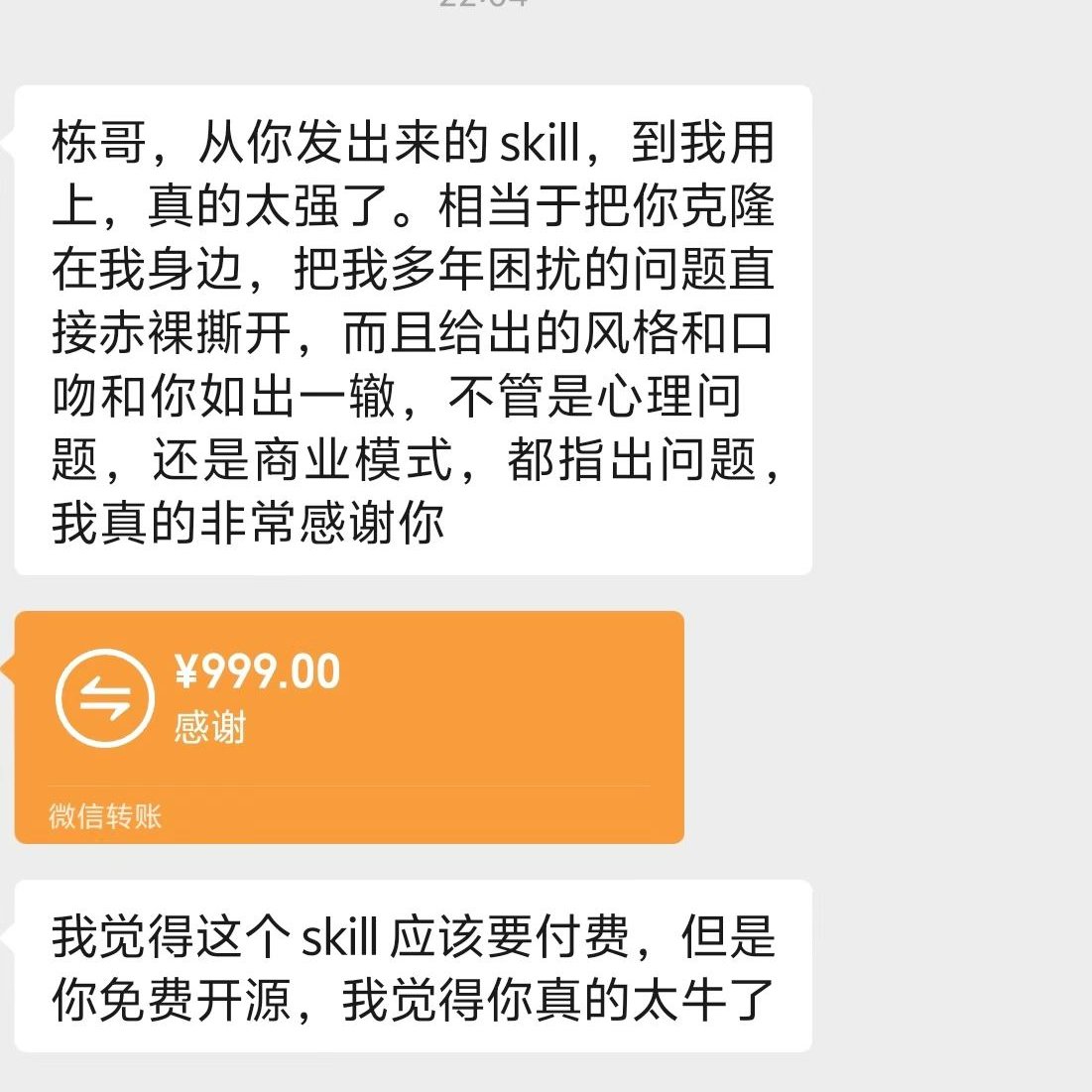
MiMo-V2-Pro & Omni & TTS is out. Our first full-stack model family built truly for the Agent era.
I call this a quiet ambush — not because we planned it, but because the shift from Chat to Agent paradigm happened so fast, even we barely believed it. Somewhere in between was a process that was thrilling, painful, and fascinating all at once.
The 1T base model started training months ago. The original goal was long-context reasoning efficiency. Hybrid Attention carries real innovation, without overreaching — and it turns out to be exactly the right foundation for the Agent era. 1M context window. MTP inference for ultra-low latency and cost. These architectural decisions weren't trendy. They were a structural advantage we built before we needed it.
What changed everything was experiencing a complex agentic scaffold — what I'd call orchestrated Context — for the first time. I was shocked on day one. I tried to convince the team to use it. That didn't work. So I gave a hard mandate: anyone on MiMo Team with fewer than 100 conversations tomorrow can quit. It worked. Once the team's imagination was ignited by what agentic systems could do, that imagination converted directly into research velocity.
People ask why we move so fast. I saw it firsthand building DeepSeek R1. My honest summary:
— Backbone and Infra research has long cycles. You need strategic conviction a year before it pays off.
— Posttrain agility is a different muscle: product intuition driving evaluation, iteration cycles compressed, paradigm shifts caught early.
— And the constant: curiosity, sharp technical instinct, decisive execution, full commitment — and something that's easy to underestimate: a genuine love for the world you're building for.
We will open-source — when the models are stable enough to deserve it.
From Beijing, very late, not quite awake.
English
FI𝕊HΞRY Isla รีทวีตแล้ว

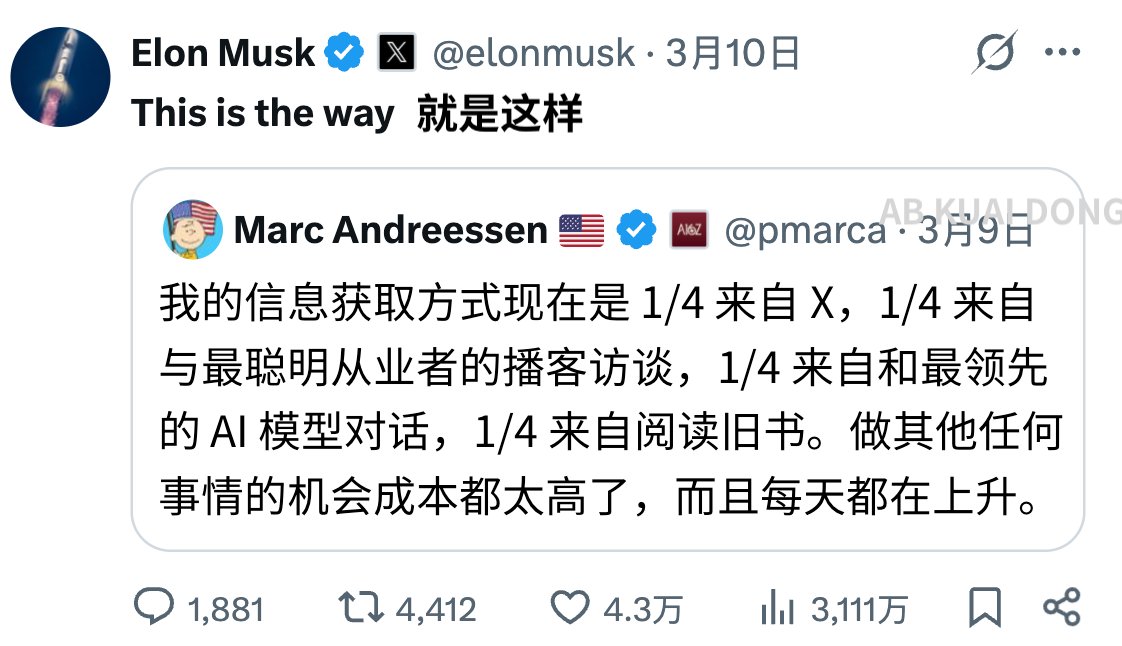
连马斯克都认可。a16z 联合创始人,分享的信息获取方式。
浏览 X 平台,听顶尖从业者分享,与最领先的 AI 模型对话,阅读旧的书籍。
他认为做其他事情,付出的机会成本都太高了,其实只需要从这几个渠道,获取信息即可。
Marc Andreessen 🇺🇸@pmarca
My information consumption is now 1/4 X, 1/4 podcast interviews of the smartest practitioners, 1/4 talking to the leading AI models, and 1/4 reading old books. The opportunity cost of anything else is far too high, and rising daily.
Minato-ku, Tokyo 🇯🇵 中文
FI𝕊HΞRY Isla รีทวีตแล้ว

我印象中这是 X 上第一篇从实战角度系统讲解天气衍生品市场的文章,不过因为直接贴了 markdown 格式到 article,X 无法直接解析,导致阅读不便,需要大家自行把文章贴到支持 markdown 的阅览器细细品读。(用这个 article 提供的功能手工插入公式的的话,工作量可能比再写一篇还大 🤣)
Y老师的原文是按照学术论文的框架写的,我把其中系统实现的部分单独提取了出来做成了笔记(链接见第一个回复),略去了大部分的推导,旨在帮助大家快速了解如何构建原文中的交易系统。(注:基于实时观测数据的交易中有两处核心实现原文有所保留,笔记中已标注待定项,需自行设计)
大家可以结合笔记通读原文,了解各类参数的选取的缘由,知其然更知其所以然,最后再次感谢 Y 老师的无私分享 😀

Y林YourAirdrop.AI@YourAirdropETH
中文
FI𝕊HΞRY Isla รีทวีตแล้ว

最近有个方案叫 PinchTab。它换了一种思路:不再用截图,而是直接读取浏览器的 Accessibility Tree(无障碍树)。
这个数据本来就是浏览器给视障用户准备的结构化信息,按钮、输入框、链接都会有明确的文本描述。AI 直接读这些结构化信息来操作页面,每页大约只需要 800 token,差不多能省 10~13 倍成本。
更方便的是,安装几乎不用折腾。在 OpenClaw 里直接让 Agent 自动安装 PinchTab,再生成一个 skill,以后所有浏览器操作都可以走这个方案。
比如打开网页、点击按钮、填写输入框、提取页面文本这些动作,Agent 都能自动完成。
这个能力其实挺实用的,比如:
·批量分析 GitHub 项目
·自动抓取网页信息做内容整理
·定期监控某些页面变化
·同时管理多个平台账号
PinchTab 还支持多浏览器实例并行,每个实例有独立 Cookie 和登录状态,比如一个跑 Twitter,一个跑 LinkedIn,互不干扰。
一句话总结:
如果你在用 OpenClaw 控制浏览器,换成 PinchTab 基本是必装插件。
体积只有 12MB,但能让 Agent 用文本理解网页,既省 token,又更稳定。省下来的 token,一个月可能够你多跑好几个 Agent。
sitin@sitinme
中文
FI𝕊HΞRY Isla รีทวีตแล้ว

用 Typescript 重构了最流行的开源金融数据源工具 OpenBB,这下终于可以一键启动了。
重构基本全程用 AI 跑,耗时两天,吃着火锅唱着歌就办完了。难免有疏漏,各位多提 issue。
车厘子@0xcherry
中文
FI𝕊HΞRY Isla รีทวีตแล้ว

Folks. Happy Friday! Appreciate the engagement with these past 2 notes.
Saying thank you by opening this one up and removing the paywall.
Why? Bc I think it could help a lot of people develop their own trade strats for what’s coming up in 2026.
EconstratPB@EconstratPB
There is something bigger at risk from the Hormuz shock. A regime shift. Includes a roadmap and timeline to navigate this shift, and what to watch out for. As with Tuesday's note, most of it is free so have a read and pls like and RT if you found it useful. 🙏
English
FI𝕊HΞRY Isla รีทวีตแล้ว

The next step for autoresearch is that it has to be asynchronously massively collaborative for agents (think: SETI@home style). The goal is not to emulate a single PhD student, it's to emulate a research community of them.
Current code synchronously grows a single thread of commits in a particular research direction. But the original repo is more of a seed, from which could sprout commits contributed by agents on all kinds of different research directions or for different compute platforms. Git(Hub) is *almost* but not really suited for this. It has a softly built in assumption of one "master" branch, which temporarily forks off into PRs just to merge back a bit later.
I tried to prototype something super lightweight that could have a flavor of this, e.g. just a Discussion, written by my agent as a summary of its overnight run:
github.com/karpathy/autor…
Alternatively, a PR has the benefit of exact commits:
github.com/karpathy/autor…
but you'd never want to actually merge it... You'd just want to "adopt" and accumulate branches of commits. But even in this lightweight way, you could ask your agent to first read the Discussions/PRs using GitHub CLI for inspiration, and after its research is done, contribute a little "paper" of findings back.
I'm not actually exactly sure what this should look like, but it's a big idea that is more general than just the autoresearch repo specifically. Agents can in principle easily juggle and collaborate on thousands of commits across arbitrary branch structures. Existing abstractions will accumulate stress as intelligence, attention and tenacity cease to be bottlenecks.
English
FI𝕊HΞRY Isla รีทวีตแล้ว

OneBook-英文原著智能阅读伴侣
首款支持epub3书籍真人朗读的外语学习app,非tss,完全真人配音(epub3书籍附在下方网盘链接)
功能特点:文本随声音同步高亮,听和看同时进行,点击即可查词,AI释义,支持苹果播客油管B站视频解析,囊括了目前最热门的外语学习功能,支持多达50种语言,永久免费
epub3资源:pan.quark.cn/s/ead99f74b644


中文
FI𝕊HΞRY Isla รีทวีตแล้ว

我已经大概将近10年完全没上过kaggle这个网站了。
最早kaggle是一个data science打比赛网站,给你一大堆training dataset,让你在上面test dataset做prediction,大家一起排名。
kaggle优质的地方在于,上面的数据非常优质,覆盖范围极其广,缺点是你真的要在上面跑回归、提交数据。
pardus牛逼之处 ,在于我把kaggle上面任何一个csv下载下来,喂给pardus,
不需要写任何一个字的prompt,pardus后面有>10个data scientist agent,并行给你工作,把csv读进去,给你跑regression。
约等于你手底下有10个在kaggle上打比赛级别的北美top 50 DS master毕业的数据分析师,并行帮你处理数据、分析数据,最后帮你汇总成一份完整的报告。
为什么no chatbot revolution是一个用户体验上的革命?
因为你给我个csv文件,我他妈是真的连打开都懒得打开,打开了我连attribute都懒得看,绝大多数的老板和决策者都是这个心态。
pardus就是一个no chatbot data science multi agent,完全不用你写一个字,pardus自己帮你挖掘出十几个数据分析的任务,帮你讲故事,帮你用数据和图表来佐证。
我可以说,我用了24小时的pardus,跑了10个巨大csv文件,里面有印度肝病的,有欧美血液检测的,有纽约房地产的,有全球电影票房的,有乳腺癌检测诊断的。
24小时之内,我唯一的工作就是找csv文件,然而我已经干了至少100个data science和bioinfo的活儿了。
甚至乳腺癌的那份报告,直接当场给出了一套鉴别风险的金标准公式,直接套医学影像结果就可以当场诊断出来了。
pardusai.org/view/27c466adb…
最关键的是,我一句prompt没写,我唯一的活儿就是上传csv,等结果,读报告。
我从来不敢说SWE Agent可以100%替代程序员,但我今天可以说,data science这个领域,算是彻底宣告死亡了。

中文

🔐 厌倦被“记录”的输入法?试试这款真正本地处理的输入法:Urik
✨滑行输入 + 拼写检查 + 智能纠错,还能把学习词库加密保存
🔐 不联网、不追踪、Gboard 的开源替代
👉ahhhhfs.com/78393/
#隐私优先 #开源输入法
中文
FI𝕊HΞRY Isla รีทวีตแล้ว

Anyone who thinks privacy teams are "competitors" is missing the entire point. Privacy isn't a zero-sum game. It demands massive education, real cryptography, strong infra, and regulatory clarity. The real competition is people trying to brand Coinbase as their "privacy" solution, or the distracting parade of shared-sequencers and AI-GF scams pretending to solve anything.
Privacy loves honest company. It's the reason blockchains matter at all; without it, centralized systems will always win on UX and cost. When one real privacy project wins, every honest privacy team wins, and the entire decentralized ecosystem becomes stronger.
But that doesn't mean we should ignore teams jumping on the "privacy" label for attention or launching a token with zero substance. That kind of grift hurts everyone and sets the whole space back within months.
Kudos to all privacy/confidentiality teams that are building for the long game @Zcash @0xfairblock @aztecnetwork @0xbowio @Arcium @RAILGUN_Project @PhalaNetwork @nym @signalapp and others!
English
FI𝕊HΞRY Isla รีทวีตแล้ว

Hashkey招股书中的疑点:拒绝重估价并可提前确认为收入的平台币 $HSK
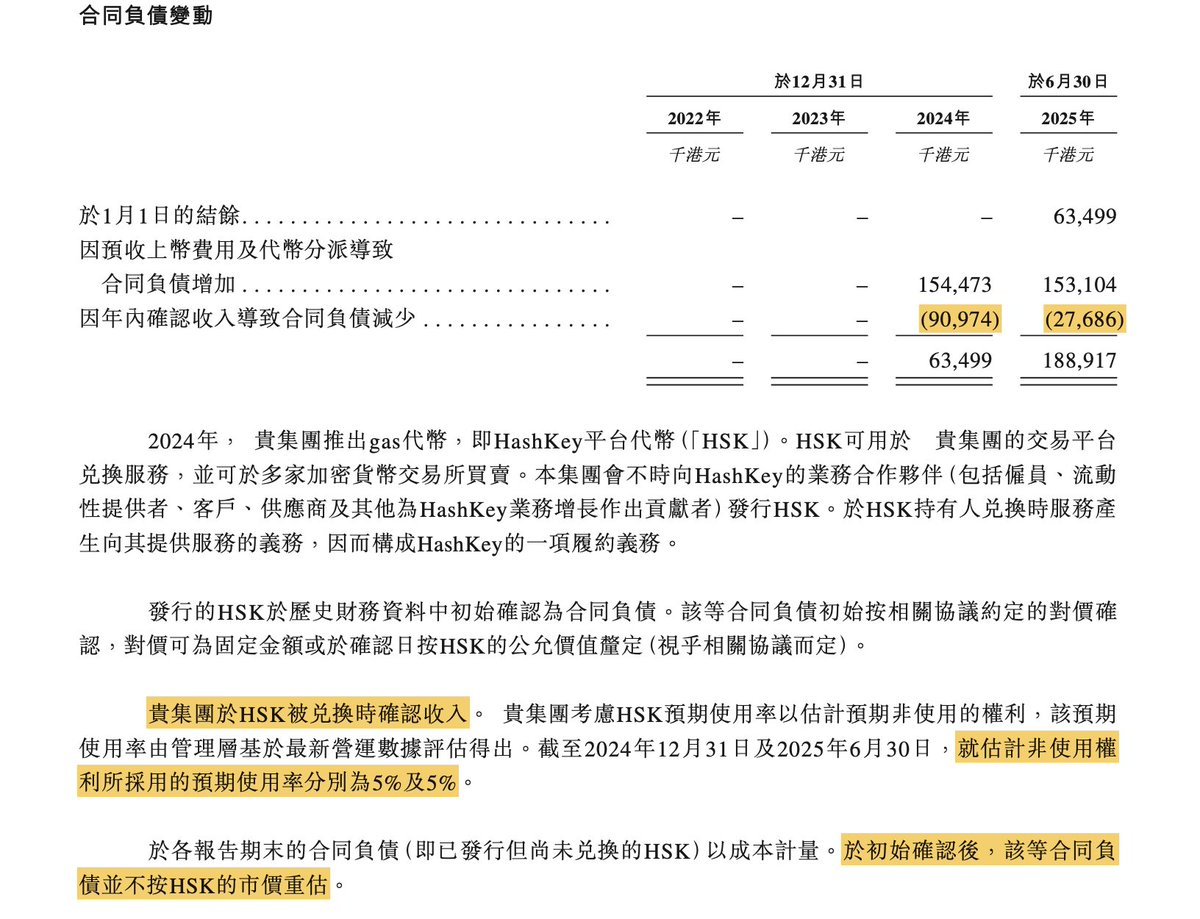
冲刺港交所上市的hashkey已在这周披露招股书,金融再就业的苯人对其平台币 $HSK 的会计处理非常好奇,研究后发现 $HSK 大有妙用,派发后先记成合同负债、不按市价重估,价格波动不影响负债表;此外还可以通过设定“预期非使用率”,将其提前确认为收入,从而达到美化财报的效果。
Hashkey对自家平台币的定义很明确,简单说就是“发币即负债,核销才确收”。(这里类似央行,发行的货币是负债)
$HSK = 服务券, 派发给kol/vip用户等的 $HSK 相当于欠其未来的服务。所以在财务上,发币当下计入 “合同负债”,相当于履约义务。
这导致一个有趣的现象,币发得越多,账面负债越高。不过这部分的币价波动“隐身”,负债端的HSK不按市价重估,即无论 $HSK 跌,负债表不受影响。
从负债确认为收入有2个方式:
1是当用户把 $HSK 花掉(抵扣交易手续费、用于hashkeychain gas等),平台完成履约义务了,负债就可转为收入。
从披露的数字看, $HSK 过往的真实使用率( $HSK 手续费收入/派发的 $HSK 价值)不足2%,也足以见得其业务的惨淡...同时因为公司是亏损的,净利润为负,答应的20%净利润回购 $HSK 自然也就无法达成。
2便是美化财报的重头戏,即设定 $HSK “预期非使用率”,便可将这部分提前确认为收入:既然都没有人用,按照 IFRS15会计准则breakage的逻辑,履约义务视为取消,收入可以入账。
招股书中说“就估计非使用权利所采用的预期使用率为5%”非常绕口,翻译成人话就是预期不会被使用的 $HSK 占比为1-5%=95%,即派发出去的 $HSK 中有95%均可被提前确认为收入。
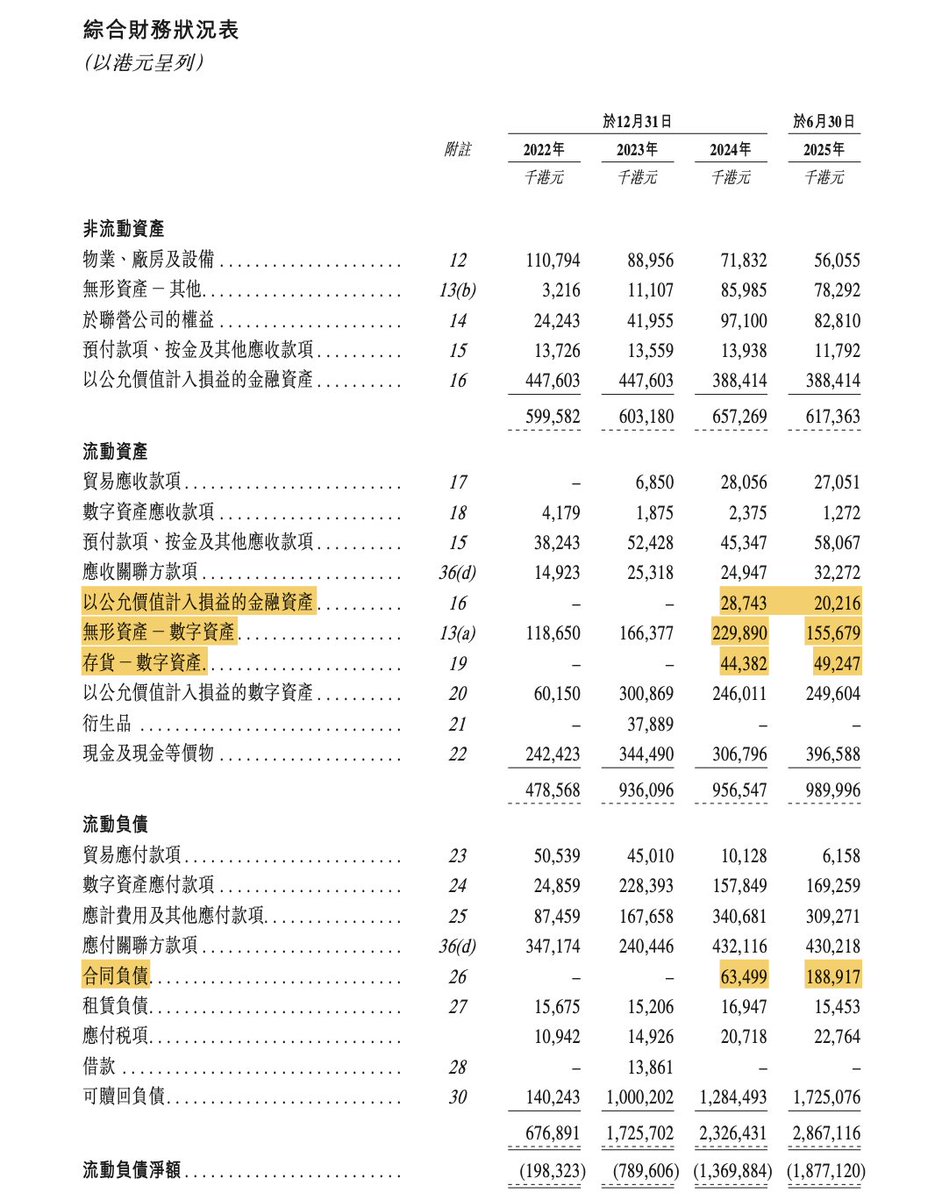
此外,招股书(附录I-7)将数字资产分为三类:无形资产、公允价值计入损益资产、存货。 这里面的疑点在于,招股书全篇未披露这几亿数字资产的具体构成,有多少是真金白银的 BTC/ETH?又有多少是回收后/尚未派发的平台币 $HSK ?这也是一个完全的黑盒。
所以如果你是hashkey,你还会选择去拉币价么?


中文
FI𝕊HΞRY Isla รีทวีตแล้ว
FI𝕊HΞRY Isla รีทวีตแล้ว

昨天公开的 Lux,应该是近期最有趣的一个 AI 模型了。
它拓宽了 AI 能力的边界:能够像人一样直接操作电脑,这让许多原本受限的场景一下子变得现实起来。
其实,OpenAI 和 Google 都有类似的模型,业内通常称之为 Computer-Using Agent(CUA),字面意思就是能自主操作电脑的智能体。
这些模型的基本原理是:每次操作前截取屏幕快照,再由 LLM 判断下一步具体点击的位置,这样就能一步步串起完整的工作流。
但 Lux 最厉害之处在于,它能将这种工作流的运行成本降到其他模型的十分之一,这就直接从量变推动到了质变。
目前官方已对开发者开放 SDK,并提供了 10 美元的免费额度。或许接下来,我们能用它开发出一些更实用、更贴近用户日常体验的智能体应用了。
OpenAGI Labs@agiopen_org
Website: agiopen.org SDK: developer.agiopen.org Blog post: agiopen.org/blog The number of use cases is endless: software QA agents, e-commerce agents, social media management agents, data entry, bulk operations, etc. You can build whatever you want!
中文
FI𝕊HΞRY Isla รีทวีตแล้ว

Kalshi 以 110 亿美元融资 10 亿美元。
原来这轮 Paradigm 领投。
John Wang@j0hnwang
Kalshi is officially the first prediction market decacorn. I still cannot believe how much we have grown (600%!) since I joined just 4 mo ago. This round was led by Paradigm and I’m very grateful for all the help @matthuang @_charlienoyes and @arjunblj have given to us so far
中文
FI𝕊HΞRY Isla รีทวีตแล้ว

FI𝕊HΞRY Isla รีทวีตแล้ว
没想到 Vitalik 在短短 24 小时内,连续推荐了三个主打私密性的聊天工具: @session_app 、 @SimpleXChat 和 @ethstatus 。
这一举动似乎又将进一步加剧即时通讯(IM)市场的碎片化问题。我之前还开玩笑地说,聊天工具是现代的「巴别塔」:虽然不同语言的问题已能通过 LLM 解决,但工具本身的割裂和封闭却始终难以跨越。
目前,微信、Telegram、WhatsApp、Line 和 iMessage 已经牢牢占据了全球普通用户的聊天应用心智。除此之外,最多也只是 Signal 这种主打极致隐私保护的,能在市场上分一杯羹。
然而,Vitalik 希望更进一步,在 Signal 已有的高标准之上,实现两个额外的突破:
- 不需要手机号/邮箱即可自由创建账户,真正做到无需许可。
- 对通讯过程中产生的元数据(metadata)提供更强的隐私保护。
我自己也一直希望能出现一款开源、重视隐私、功能强大且用户体验优秀的 IM 产品。这也是为什么早在 2017 年,我就抱着同样的期望参与了 Status 的 ICO。但现实很残酷:Status 在正式推出后曾短暂风光一时,但最终还是因为缺乏网络效应、使用门槛高,逐渐淡出了主流视野。
但无论如何,先试试看这些产品吧,希望总有一款能形成足够的网络效应。
vitalik.eth@VitalikButerin
Encrypted messaging, like @signalapp, is critical for preserving our digital privacy. Two important next steps for the space are (i) permissionless account creation and (ii) metadata privacy. @session_app and @SimpleXChat are two messaging apps pushing these directions forward. For this reason I've donated 128 ETH to each. Addresses available on their websites if you wish to follow on: getsession.org simplex.chat But also, actually download and use them! Neither of the two are perfect pieces of software, they have a way to go to get to truly optimal user experience and security. Strong metadata privacy requires decentralization, decentralization is hard, users expecting multi-device support makes everything harder. Sybil / DoS resistance, both in the message routing network and on the user side (without forcing phone number dependence) adds further difficulty. These problems need more eyes on them. I wish all teams working on these important problems best of luck.
中文
FI𝕊HΞRY Isla รีทวีตแล้ว

Encrypted messaging, like @signalapp, is critical for preserving our digital privacy. Two important next steps for the space are (i) permissionless account creation and (ii) metadata privacy.
@session_app and @SimpleXChat are two messaging apps pushing these directions forward.
For this reason I've donated 128 ETH to each. Addresses available on their websites if you wish to follow on:
getsession.org
simplex.chat
But also, actually download and use them!
Neither of the two are perfect pieces of software, they have a way to go to get to truly optimal user experience and security. Strong metadata privacy requires decentralization, decentralization is hard, users expecting multi-device support makes everything harder. Sybil / DoS resistance, both in the message routing network and on the user side (without forcing phone number dependence) adds further difficulty.
These problems need more eyes on them. I wish all teams working on these important problems best of luck.
English
FI𝕊HΞRY Isla รีทวีตแล้ว

说下Zcash,因为上周看到这条Tweet,当时有事儿没转,正好这几天稍稍看了下Zcash的一些东西,把这事儿给拾起来
简单说来就是欧美这个大V觉得这次Zcash就是以纳瓦尔为代表的一帮精英Cabal攢了个局,然后还找了一帮欧美顶流加密大V帮他们一起喊,亚洲KOL貌似就没几个收到这个广子……
不过去看了下Zcash的Dashboard,确实隐私池Zec数量从今年初就迅速攀升,不是俩月前喊单了才有的
Sprout,Sapling是一二代池,用了ZK-Snark,绿的那个Orchard是三代Halo2的新技术隐私池,从图上看这一年数量在飙升
不过11月之后不涨了,进入平台期,Zcash的币价可以看到11月摸了三次700左右的顶,似乎上升动能也有所停滞,跟隐私池的曲线基本保持一致
至于还有人讨论的ZSA(Zcash Shielded Asset),把Zcash变成一个可以发行其他资产且享受Zcash隐私级别的平台,貌似是22年就有的提案,今年可算见到一些曙光。但是看进度一杆子支到明年Q4了,到时候Zcash热度还剩多少真不好说。
再者这样一来Zcash不就变成一个类似Aleo,Oasis,Secret这种的“隐私智能合约公链”了?这不一定是好事儿,丢了Meme/SOV属性强行变身“功能链”,有可能像BTC非要尝试着走闪电网络搞支付最后还是回到SOV路线一样 - 此路不通!
当然也可能是偏见,毕竟还没仔细去看社区的提案和讨论啥的。未来两周抽空仔细研究研究, 届时再来跟大家分享


Mark Moss@1MarkMoss
Wonder why ZCash is showing up EVERYwhere all of a sudden? 👇
中文