ทวีตที่ปักหมุด

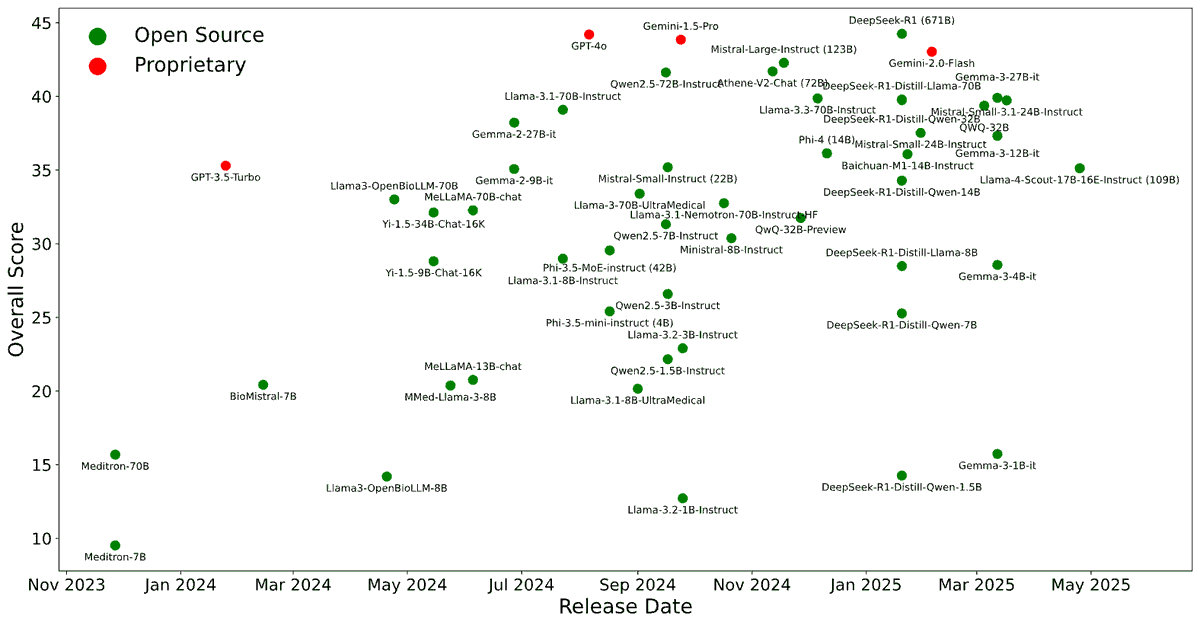
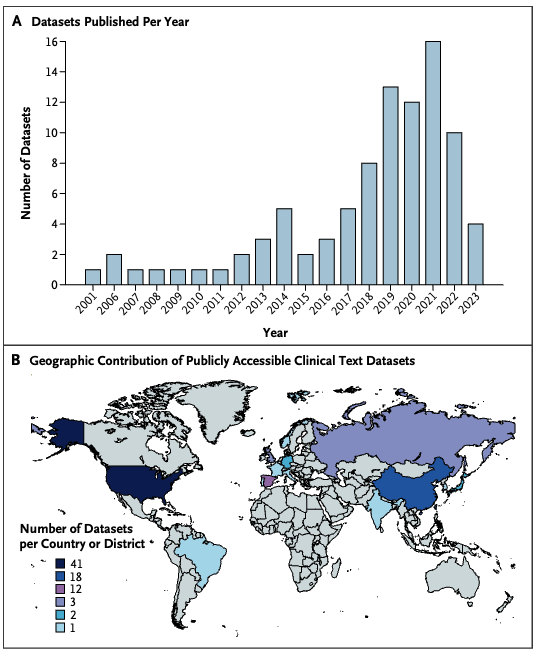
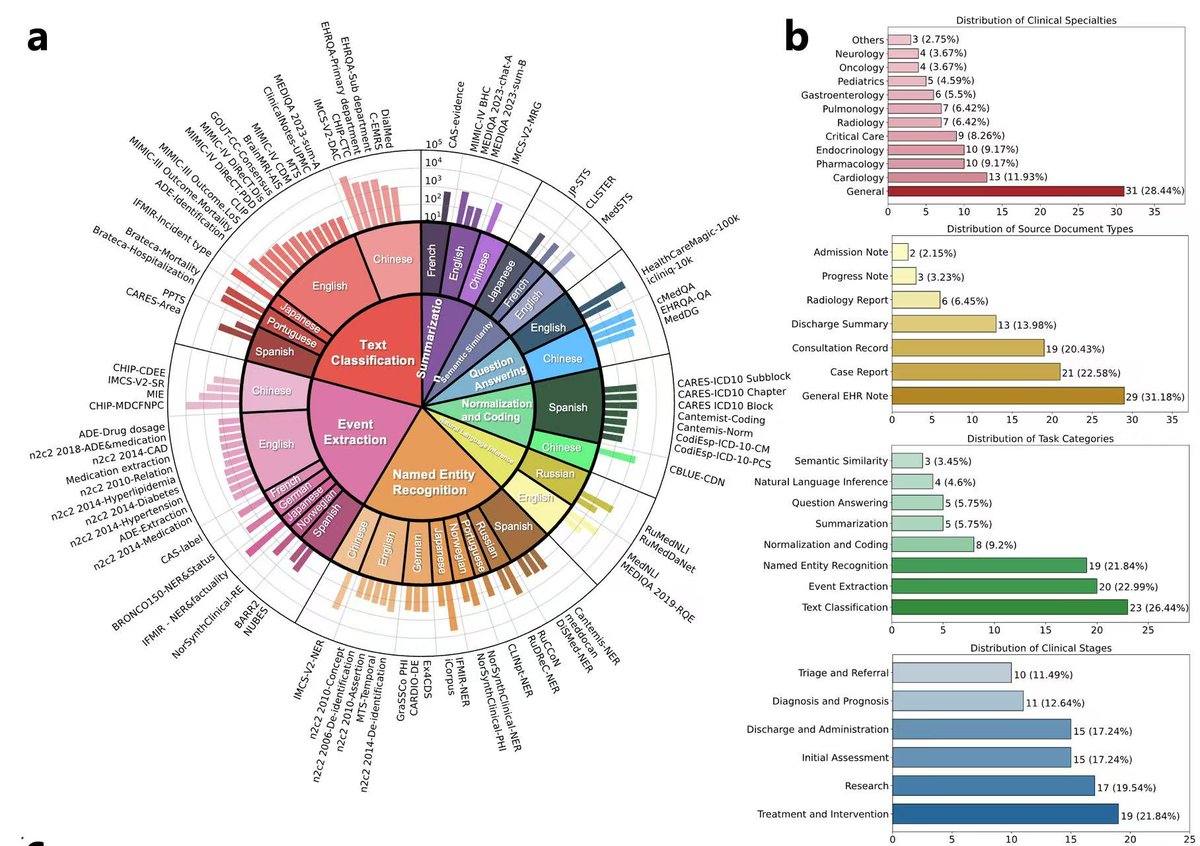
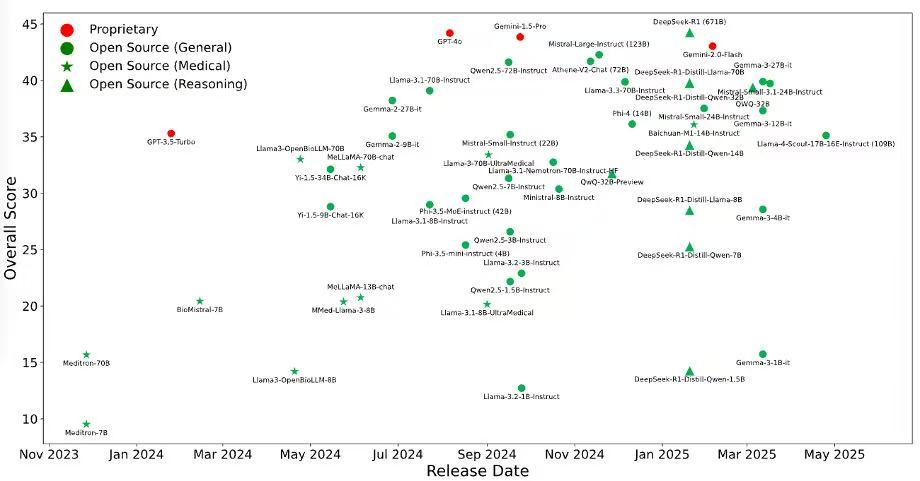
We’re excited to release BRIDGE, a comprehensive benchmark to date for evaluating LLMs on real-world clinical text. Built on multilingual, de-identified EHR data across 87 tasks in 9 languages, BRIDGE evaluates 52 models — including GPT-4o, Gemini, DeepSeek-R1, and LLaMA 4 — through 13,000+ experiments and over 21 million inferences.
💡 Results:
🏆 DeepSeek-R1 leads overall
🥈 GPT-4o and Gemini follow closely
🌟 Baichuan-M1 shines in medical-specific tasks
📈 BRIDGE offers a public leaderboard + open datasets to support fair, ongoing evaluation and model comparison.
Thanks for collaborating closely with great teams from @MassGenBrigham, Harvard, MIT, Stanford, the Mayo Clinic, and UIUC.
🧾 Read the arXiv paper: arxiv.org/abs/2504.19467
🚀Leaderboard: huggingface.co/spaces/YLab-Op…
We welcome new models and data submissions!
#LLM #MedAI #EHR #AIinHealthcare #Benchmark


English