ทวีตที่ปักหมุด
Kush Hari
43 posts

Kush Hari รีทวีตแล้ว

We developed a simple, sample-efficient online RL technique for post-training image generation models. We see it as a possible steerable alternative to CFG, driven by any scalar reward, including human preference.
English
Website (with code): stitch-2.github.io
Paper: arxiv.org/abs/2510.25768
Thanks to Ziyang Chen, Hansoul Kim and @Ken_Goldberg for collaboration and @IntuitiveSurg for the dVRK!!! #RAL
English
Kush Hari รีทวีตแล้ว

Robotics: coding agents’ next frontier.
So how good are they?
We introduce CaP-X: an open-source framework and benchmark for coding agents, where they write code for robot perception and control, execute it on sim and real robots, observe the outcomes, and iteratively improve code reliability.
From @NVIDIA @Berkeley_AI @CMU_Robotics @StanfordAILab
capgym.github.io
🧵
English
Kush Hari รีทวีตแล้ว

Really excited to release mjviser, a web-based MuJoCo viewer, powered by Viser. It has almost all the features of the native MuJoCo viewer, but runs in your browser. Load and simulate any MuJoCo model with a single uv command 👇
uvx mjviser
English
Kush Hari รีทวีตแล้ว

Check out our latest Dream2Flow work, which uses 3D object flow from generated videos to perform manipulation!
Wenlong Huang@wenlong_huang
What representation enables open-world robot manipulation from generated videos? Introducing Dream2Flow, our recent work that bridges video generation and robot control with 3D object flow. dream2flow.github.io @Stanford #ICRA2026 1/N
English
Kush Hari รีทวีตแล้ว

Introducing Tether 🪢, a fun little idea to scale data by having our robot “play” in the real world for over 24 hours, throughout the day and overnight—improving policies from zero to mastery with minimal supervision!
But play is messy, with out-of-distribution scenarios that are hard to anticipate. To perform autonomous functional play in the real world, from just a handful of demos, we propose a highly robust few-shot imitation method that warps demo trajectories using visual correspondences. Then, continuously running it within a multi-task VLM-guided cycle, we generate a data stream that produces 1000+ expert-level demos. This generated data is finally funneled downstream to train imitation learning policies, which improve from zero to near-perfect success rates.
We’ll be presenting Tether at #ICLR2026 in just a few weeks! But before that, deep dive with me… 🧵
English
Kush Hari รีทวีตแล้ว

How can robot policies be trained to best leverage VLMs' CoT reasoning and in-context learning for generalization?
The key is Steerable Policies: vision-language-action models that can be flexibly controlled in many ways!
steerable-policies.github.io
1/9

English
Kush Hari รีทวีตแล้ว

We trained diffusion models on a billion LLM activations, and we want you to use them!
New preprint: Learning a Generative Meta-Model of LLM Activations
Joint work with @feng_jiahai, @trevordarrell, @AlecRad, @JacobSteinhardt.
More in thread 🧵
English
Kush Hari รีทวีตแล้ว

Some exciting takeaways in addition to Brent's post:
• We show flow policies working for sim2real humanoid locomotion & motion tracking without distillation or shortcut models.
• The same recipe works for both from-scratch RL and BC → RL fine-tuning for manipulation---no bells and whistles.
Code will be released: github.com/amazon-far/fpo…
Brent Yi@brenthyi
New project! Flow Policy Gradients for Robot Control tldr; a simple online RL recipe for training and fine-tuning flow policies for robots co-led w/ @redstone_hong: hongsukchoi.github.io/fpo-control
English
Kush Hari รีทวีตแล้ว

tl;dr New planner for world models! GRASP: gradient-based, stochastic, parallelized.
Long range planning for world models has always been an issue. 0th order methods like CEM/MPPI dominate, but have degrading performance at longer contexts or higher-dimensional actions. We wanted to address this from the ground up.
w/ Michael Rabbat, @ask1729 , @ylecun*, @_amirbar* (equally advised)
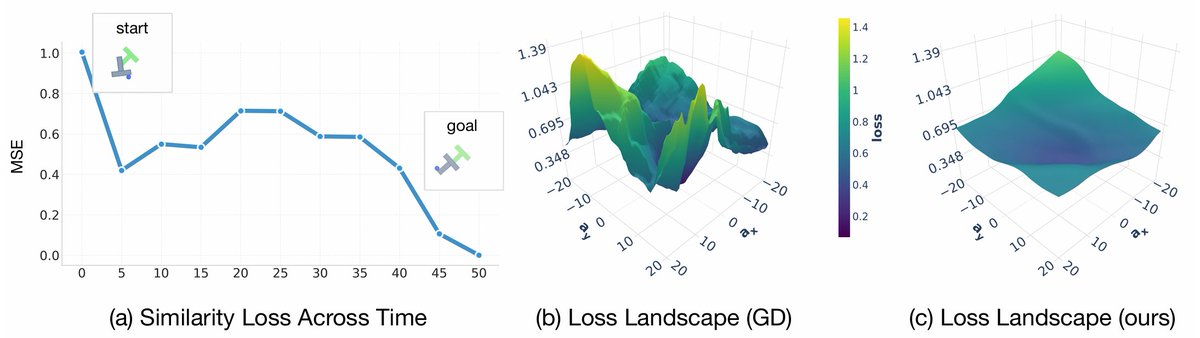
English
Kush Hari รีทวีตแล้ว

New project! Flow Policy Gradients for Robot Control
tldr; a simple online RL recipe for training and fine-tuning flow policies for robots
co-led w/ @redstone_hong: hongsukchoi.github.io/fpo-control
English
Kush Hari รีทวีตแล้ว

[Accepted to ICRA 2026!] 🚀 Introducing EgoMI: An egocentric manipulation interface that captures synchronized 6-DoF head and hand trajectories from egocentric human demonstrations!
Transfers to IL policies zero-shot w/o visual augmentation or on-embodiment data.
1/n
English
Kush Hari รีทวีตแล้ว

Do you ever find finetuning VLA overfits to the target task, to the point where generalist ability is lost and even minor deviations beyond the SFT data break the policy?
We found an extremely simple solution: directly merge the base and finetuned policy in weight space 🤯
👇🧵
English
Kush Hari รีทวีตแล้ว

Can robot data evolve with robot hardware? Robot arms and hands are rapidly evolving based on advances in materials, motors, sensors, mechanical designs, and applications. Now, demo data can also evolve:
AugE-Toolkit is a new open-source, easy-to-use, scalable package for augmenting robot embodiments: it converts demo data from one robot arm/gripper to a different robot arm/gripper in a scalable way.
We used AugE-Toolkit to create OXE-AugE––a large open-source dataset that augments 16 popular OXE subsets with 9 different robot embodiments to provide over 2M new trajectories, tripling the size of the original dataset. The OXE-AugE dataset is on HuggingFace and you can download and train right away!
Most importantly, we find robot augmentation scales!
🌐 oxe-auge.github.io
🤗 huggingface.co/oxe-auge
🔗arxiv.org/abs/2512.13100
🧵👇 (1/9)
English