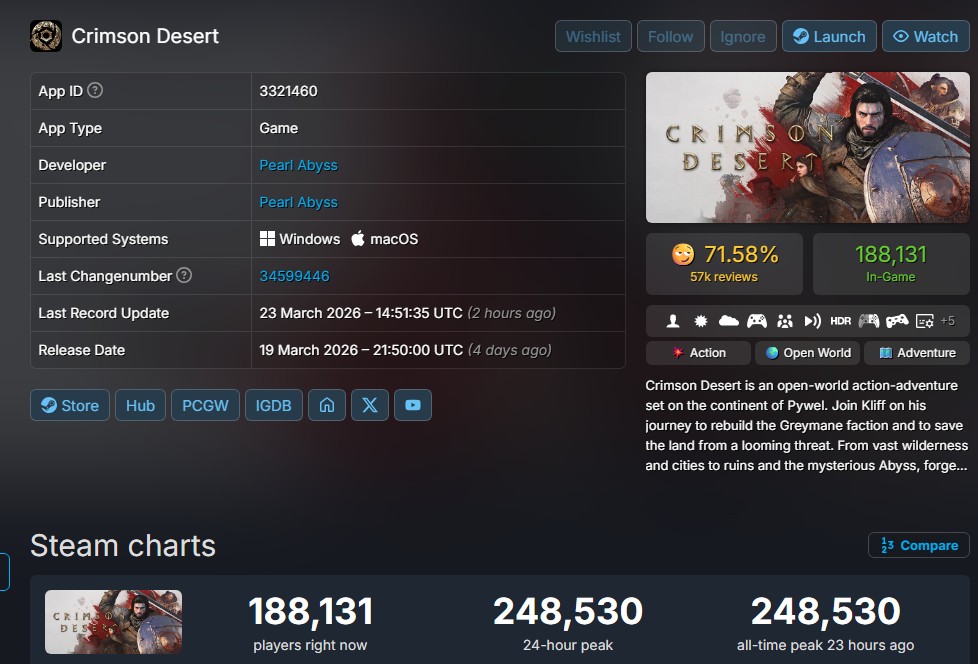
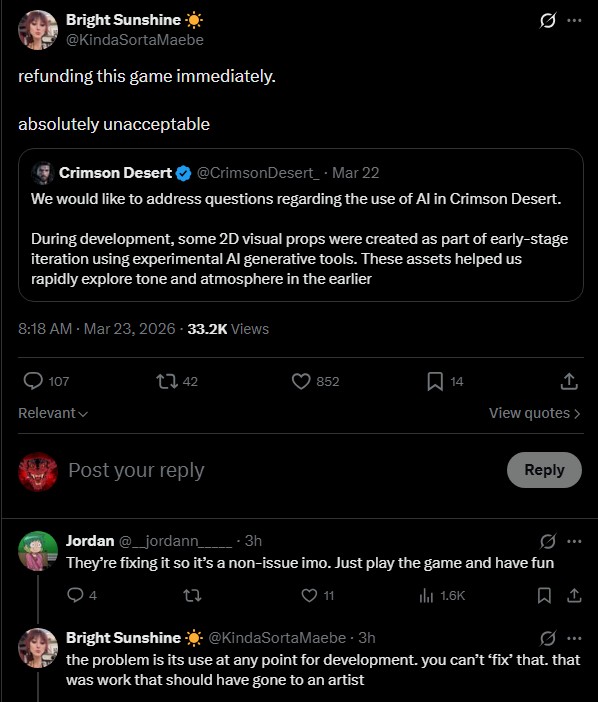
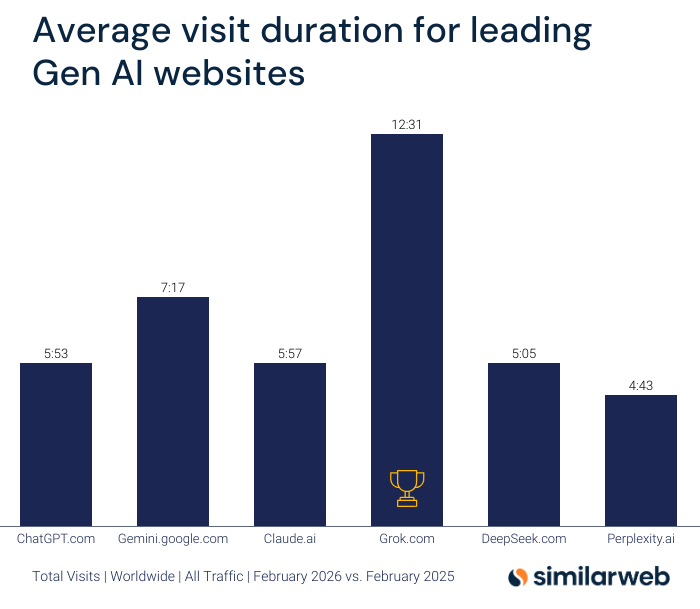
ทวีตที่ปักหมุด

Ximm's Law: every critique of AI assumes to some degree that contemporary implementations will not, or cannot, be improved upon.
Lemma: any statement about AI which uses the word "never" to preclude some feature from future realization is false.
English