
Martin Beyer
640 posts


I built an AI Influencer automation in Arcads
... that Automatically Create UGC Videos while you sleep
Comment “UGC” and I’ll send you the full workflow 👀
English
Martin Beyer รีทวีตแล้ว

Martin Beyer รีทวีตแล้ว

@gmonce Estimado, existe evidencia que vincule cambio climático con el aumento en la frecuencia de estos eventos?
Español

Hoy Montevideo tuvo un evento TR100 (que se espera suceda una vez cada 100 años), el segundo en dos años. Tener dos horas después situación normal habla bien del sistema de drenaje, diseñado en general para eventos TR10 o TR20.
Pero el cambio climático no es un cuento.
Intendencia de MVD@montevideoIM
Se normaliza el tránsito vehícular en la zona de La Paz, Rondeau, Galicia y Paraguay 🚘 #MontevideoMásVerde 🌳
Español

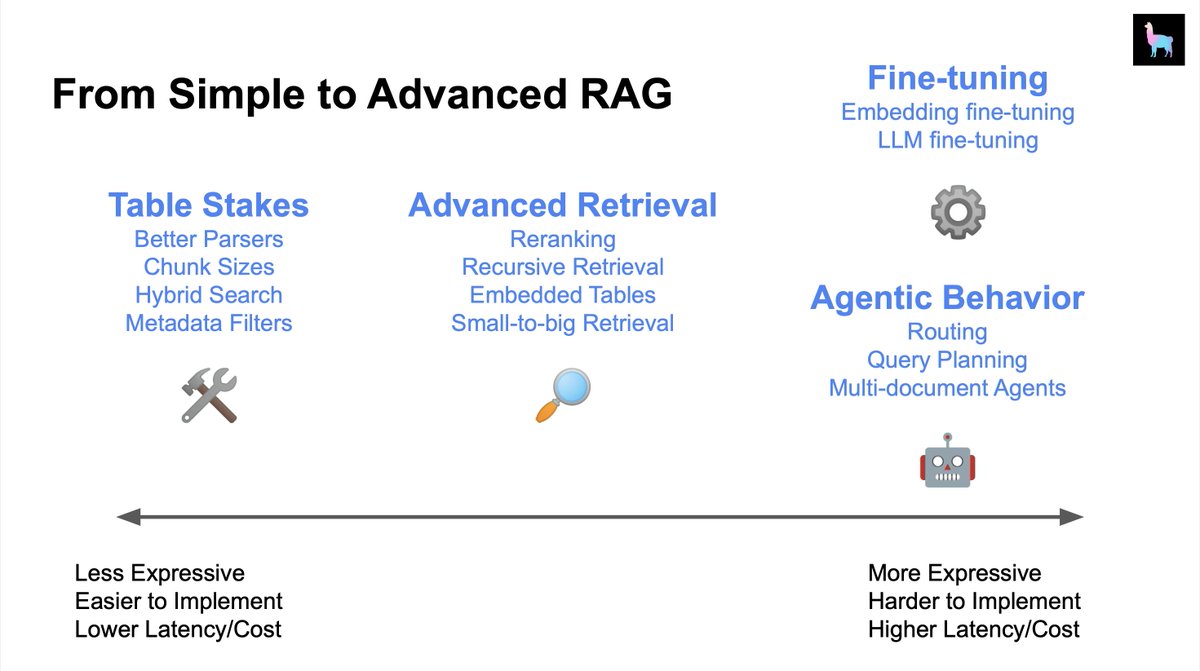
The question “How can I improve my RAG system” is hard because there’s like 50+ things you can try.
I usually give the advice of trying the lowest-hanging fruit first (“table stakes”), and progressively try out more advanced techniques:
🔎 Advanced Retrieval
🤖 Agents
⚙️ Fine-tuning
We’ll be giving a glimpse into all of this during our AI Engineer Summit workshop and talk! Sneak preview of some resources below 👇
Chunk Sizes (Table Stakes): blog.llamaindex.ai/evaluating-the…
Advanced Retrieval Guides: docs.llamaindex.ai/en/stable/end_…
Multi-Document (Agents): docs.llamaindex.ai/en/stable/exam…
Fine-tuning: docs.llamaindex.ai/en/stable/end_…
@disiok is leading our workshop and it’s happening RIGHT NOW - if you can’t make it don’t fret, we’ll make the materials available after :)
English
@jobergum @n0riskn0r3ward Do you have some pointers on multi vector?
English

@n0riskn0r3ward A couple of reasons:
- Lack of training data
- Quadratic cost
- Questionable if you can represent a long text as a single vector
Multi-vector is the future, thinking that a long document can effectively be represented as a single vector is naive imho.
English

Can someone explain to me why there has been no change in embedding context lengths of open source models (all 512 tokens)? Do the improvements made in scaling LLM context windows not also apply to embeddings? @jobergum
English
@Yampeleg @ClementDelangue This is great! What about truly open source, as in commercially viable models? Any winners there?
English

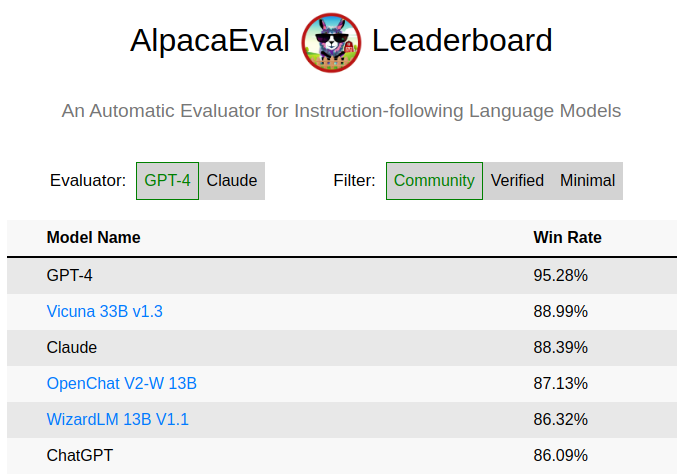
I went through many open-source models lately.
Here are my current top models that I suggest you test for yourself:
- Nous-Hermes: Still the best in my opinion for day-to-day usecases. It follows your instructions flawlessly nearly all the time. [Especially if you use beam search]
Link: huggingface.co/NousResearch/N…
- WizardCoder: Yes. It is a coding model but wow it is also so damn powerful on everything. I was floored by it when I first tried it.
Link: huggingface.co/WizardLM/Wizar…
- OpenChat V2 Weighted: Leading AlpacaEval. Really cool model and the approach behind it (Offline RL) is currently something I try myself based on their write up.
Link: huggingface.co/openchat/openc…
- Baichuan-13B-Chat: A very good model! Following some of the most tricky instructions I tried with ease.
Link: huggingface.co/baichuan-inc/B…
- ChatGLM2-6B: Amazing model that is hard to believe is this small. It's training method is also very interesting! (incorporating MLM pretraining with a causal model)
Link: huggingface.co/THUDM/chatglm2…
- UltraLM-13b: The data this model trained on is the best I had seen on Huggingface. Hands down. The model itself got some criticism lately but I think that it should get a second chance.
Link: huggingface.co/openbmb/UltraL…
- InternLM-7b: Metric-wise: This model is the best 7B model we got today. It is also very good on day to day use cases but just take in consideration that you need to allow external source code to run if you want to use it.
Link: huggingface.co/internlm/inter…
Summary:
I deliberately did not include models that are trained "LIMA style" (Small amount of data).
They might be good but I think they miss the point: This is data science. It is all about the data.
We should strive to use as much data as possible that contain as much information and facts as possible.
Coming up with unique ways to use less data is absolutely good but I think this should be done as the last step of the training.
To "align" your model to answer nicely, so I am more interested in small models that are trained on huge datasets first.
Why small models?
Most models at 65B are much better mostly because of their scale. (Insane model to try: Airoboros 65B)
Opinion about scale:
We should absolutely aim to train a huge SOTA model open source once we clear all the details training smaller models first!
In the picture: OpenChat V2-W overtaking ChatGPT-3.5 on AlpacaEval. I don't think it means much but I like looking at this! 🙃
English
@Marinavelozo @AntelDeTodos Totalmente, que Antel empiece a producir agua
Español

@AntelDeTodos Me importa un 🥚🥚🥚🥚 el 5G, QUEREMOS AGUA POTABLE!!!!!
Español

¡Conectamos a Uruguay con 5G para que vos te conectes con el futuro!
La tecnología 5G ya es una realidad que recorre nuestro país a la mayor velocidad para impactar en la vida de personas y empresas. En Antel, #EstamosParaConectarte
Español
@jobergum @huggingface What about the instruct model, it uses blaize, which is from share gpt, which violates tocs, how are they licensing that?!?
English
I don't understand how a @huggingface employee with Open-Source in their bio can characterize the Falcon model as an open-source LLM. Just stop.
huggingface.co/tiiuae/falcon-…
Quentin Lhoest 🤗@lhoestq
Check out the dataset of the best Open-source LLM 🦅Falcon-40b here 💥 😲 5,000+ parquet files 😳 960M+ samples 🤯 500-650B tokens !! And with a data preview 👇
English
@jerryjliu0 How do you think this translates to even dumber models, say vicuna 13b?
English
We spent a lot of time experimenting with agents + data. 🧪
We found that ReAct is too complex for “dumber” LLMs to query data reliably.
Instead, if we make the agent simpler and Tools better, we can get good query results! 💡🛠️
Full (long) blog: @jerryjliu98/dumber-llm-agents-need-more-constraints-and-better-tools-17a524c59e12" target="_blank" rel="nofollow noopener">medium.com/@jerryjliu98/d…
English
@jobergum Scaling, maintining in sync, replicating, huge pains with VectorDB, this person has no idea
English
I think I’ll nominate this take on vector databases as the dumbest so far.
Tools lack real-time CRUD operation support and durability guarantees.
Many vector workloads require sharding and replication. Not only for scale but to retain high recall accuracy.

English
English

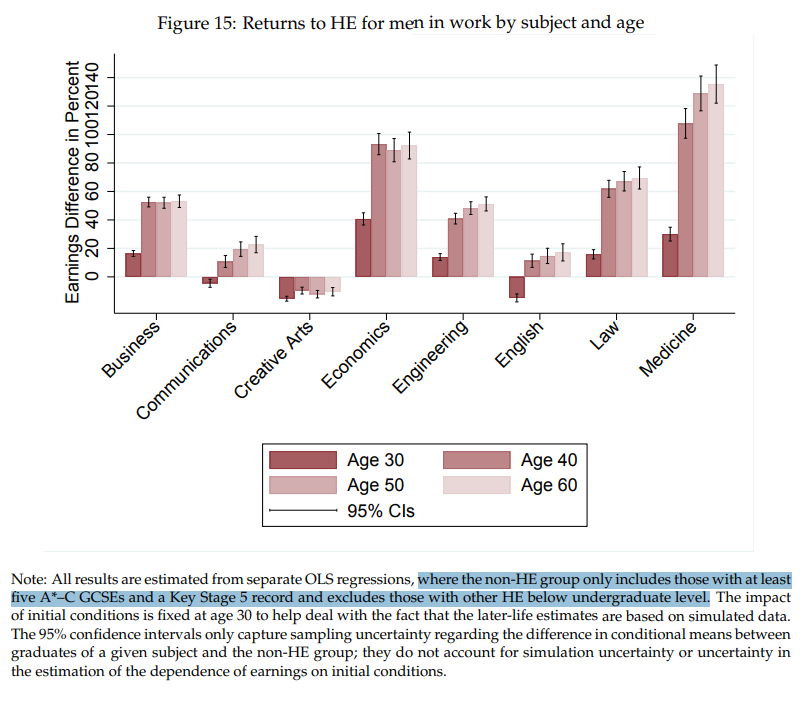
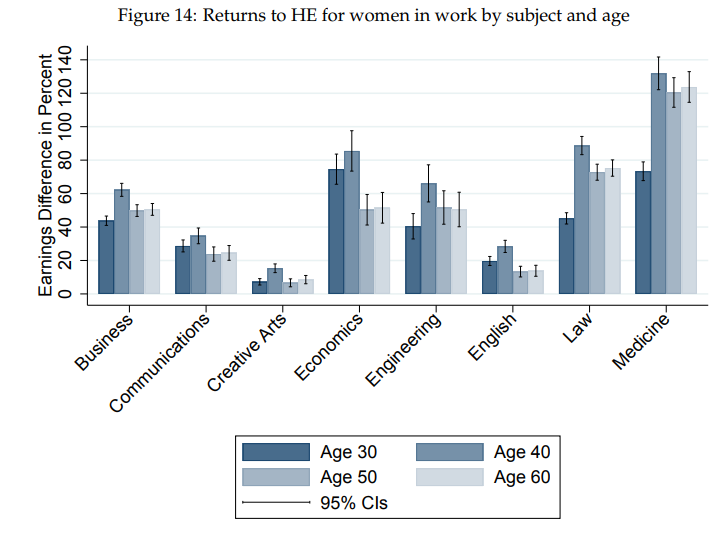
Men have better low-education career options
You can sort of see the impact of this in the age-stratified results
The men who don't get educated, start their careers and have earnings that make the early returns to an education look relatively smaller for men than for women
assets.publishing.service.gov.uk/government/upl…
English

Here's a mysterious pattern: the financially less valuable university degrees are even less valuable for men. Why is that?

English
@YiTayML do you happen to know why LLama gained so much popularity over Flan-T5, and why it seems to get better results for instructions even when fine tuned with alpaca? Does it have to do with size relative to encoder+decoder vs decoder only?
English
Martin Beyer รีทวีตแล้ว

In addition to pausing AI for 6 months, I propose pausing carbon emissions for 6 months so we can solve climate change during that time.
English
@RaulJuncoV @svpino Sadly this is not the case, this model cannot be used commercially. It uses llama which has non-commercial license and the dataset violates OpenAI terms of services since it uses it to create a competing model. I think the best option is together.xyz chat gpt
English

@svpino Thanks for sharing this, Santiago.🔥
This could open the door for companies looking into fine-tuning these models around their business logic.
English

You can now clone ChatGPT!
OpenAI didn't open-source its models, so we don't know much behind the scenes.
But the first complete end-to-end model pipeline was just released, and it's the most practical open-source project resembling ChatGPT.
Here are the details:
English
Martin Beyer รีทวีตแล้ว

Martin Beyer รีทวีตแล้ว

Martin Beyer รีทวีตแล้ว

I've developed a lot of plugin systems, and the OpenAI ChatGPT plugin interface might be the damn craziest and most impressive approach I've ever seen in computing in my entire life.
English






La falta de transparencia no puede ser sin querer… esta todo diseñado con una falta de ética desagradable.
Español
disponibles. Pero lo mas magnifico es que cuando eventualmente me llego y estaba todo helado la app te sugiere que califiques negativamente al local (por algo que es exclusivamente culpa de ellos). Osea te cobran para demorarte los pedidos y que quede como culpable el local.

Español
@pedidosya ya es la segunda vez que me pasa: la app muestra por 1 hora y media “el local esta preparando tu pedido”, llamo al local para averiguar y me dicen que hace 1 hora esta pronto pero PY no le manda repartidor. Te tratas de comunicar con ellos pero obviamente no hay agente
Español