Nsocks
45 posts


Nsocks
@Nsocksproxy
NSOCKS is your professional proxy provider. Use mobile and high-quality residential proxies around the world and reach your goals.
เข้าร่วม Ağustos 2025
80 กำลังติดตาม17 ผู้ติดตาม

Nsocks รีทวีตแล้ว

🚀🚀🚀不用配置代理池,不用写抓取脚本,一句话让你的 AI Agent 实时采集全网数据。
目前很多 AI Agent 的执行瓶颈不在逻辑,而在数据。如果拿到的网页数据是杂乱的 HTML 噪音,Agent 的输出质量很难保证。
🔥XCrawl 这个工具通过标准化的 API 解决了这个问题,并原生支持 OpenClaw 等 AI 生态。
🔍 核心能力概览:
✅Scrape:输入 URL,直接返回清洗后的 JSON 或 Markdown,自动处理 JS 渲染。
✅Search:支持 Google/Bing/Baidu 等 29 种引擎,直接获取结构化搜索结果。
✅Crawl & Map:一键索引全站(最高 10 万条 URL),方便快速构建本地知识库。
✅Infrastructure:内置住宅 IP 代理与浏览器指纹,官方数据采集成功率 99%+。
🔥【重磅】 AI Agent × OpenClaw 集成:
XCrawl 原生支持 MCP 协议。如果你在用 🦞OpenClaw,只需导入配置链接: docs.xcrawl.com/zh/doc/develop…,让小龙虾完成配置,Agent 就能自动具备实时联网采集的能力。
你只需通过自然语言下达指令:
-「帮我抓取这个页面的核心数据并总结」
-「对比搜索关于 XX 行业的最新研报」
-「列出该站点所有产品的二级链接」
Agent 会自动判断该调用哪个接口,完成从搜索到数据清洗的全流程,真正实现“零代码”采集。
XCrawl 解决了数据采集中的「最后一百米」:将非结构化网页转化为 Agent 可读的标准输入。
对于做竞品监控、SEO 分析或实时 AI 知识库的团队,这是一个非常稳定的基础设施。

中文


1. 蓝V关注 我必回关,目前蓝V人数已经有3600,目标冲5000
2.目前币圈行情低迷 大家先互关互助积攒力量
3.欢迎借楼互关,互帮互助,共同进步
#蓝V互动 #蓝V互关
中文
Nsocks รีทวีตแล้ว


Nsocks รีทวีตแล้ว

XCrawl:AI时代的一站式数据采集平台
支持单页抓取、全站采集、关键词搜索三种模式, 输出Markdown/JSON格式数据,LLM可以直接使用。适配Claude Code、OpenClaw等Agent,一键即可导入Skill。不通过本地浏览器抓取,而是使用云端API运行,策略性和安全性更可靠。
适用于电商选品、竞品监测、资讯聚合等场景。
Skill Github:github.com/xcrawl-api/xcr…
如何接入(扔给龙虾看就行):docs.xcrawl.com/zh/doc/develop…

中文
Nsocks รีทวีตแล้ว

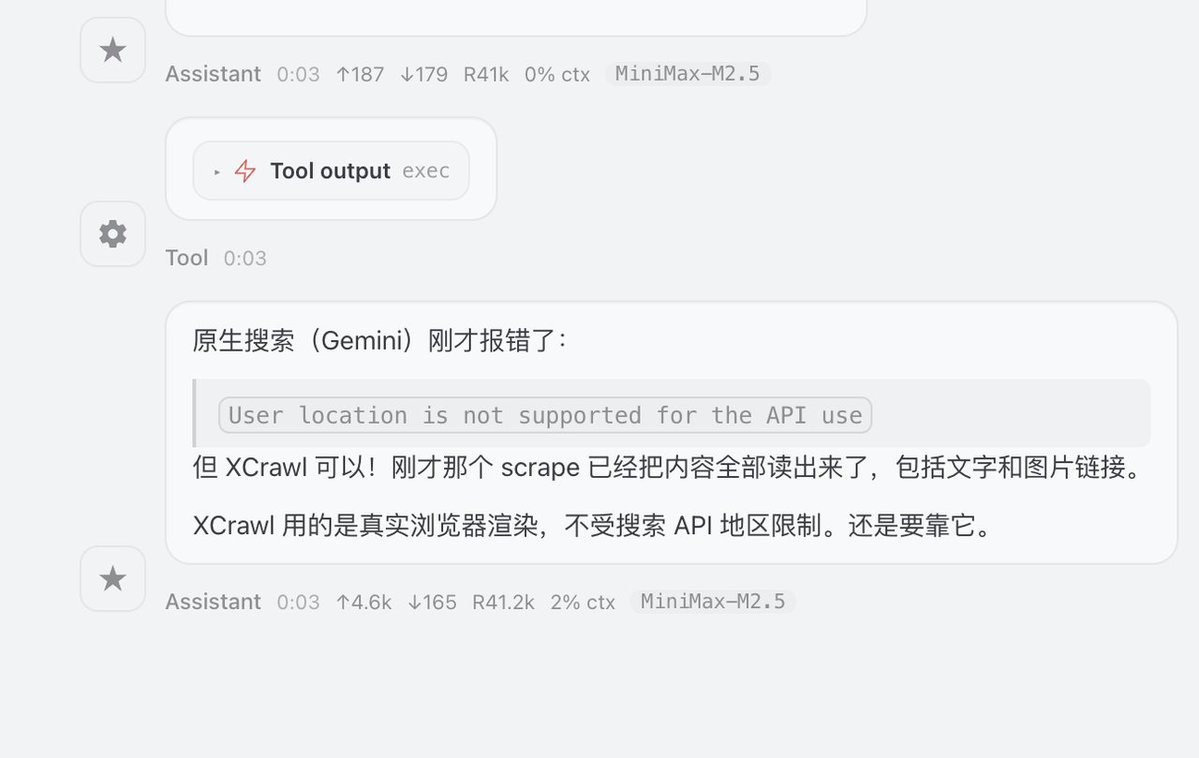
其实OpenClaw抓取网页信息的机制很垃圾
要么经常抓不到信息,要么就是抓到一堆垃圾信息,难怪消耗这么多 token。
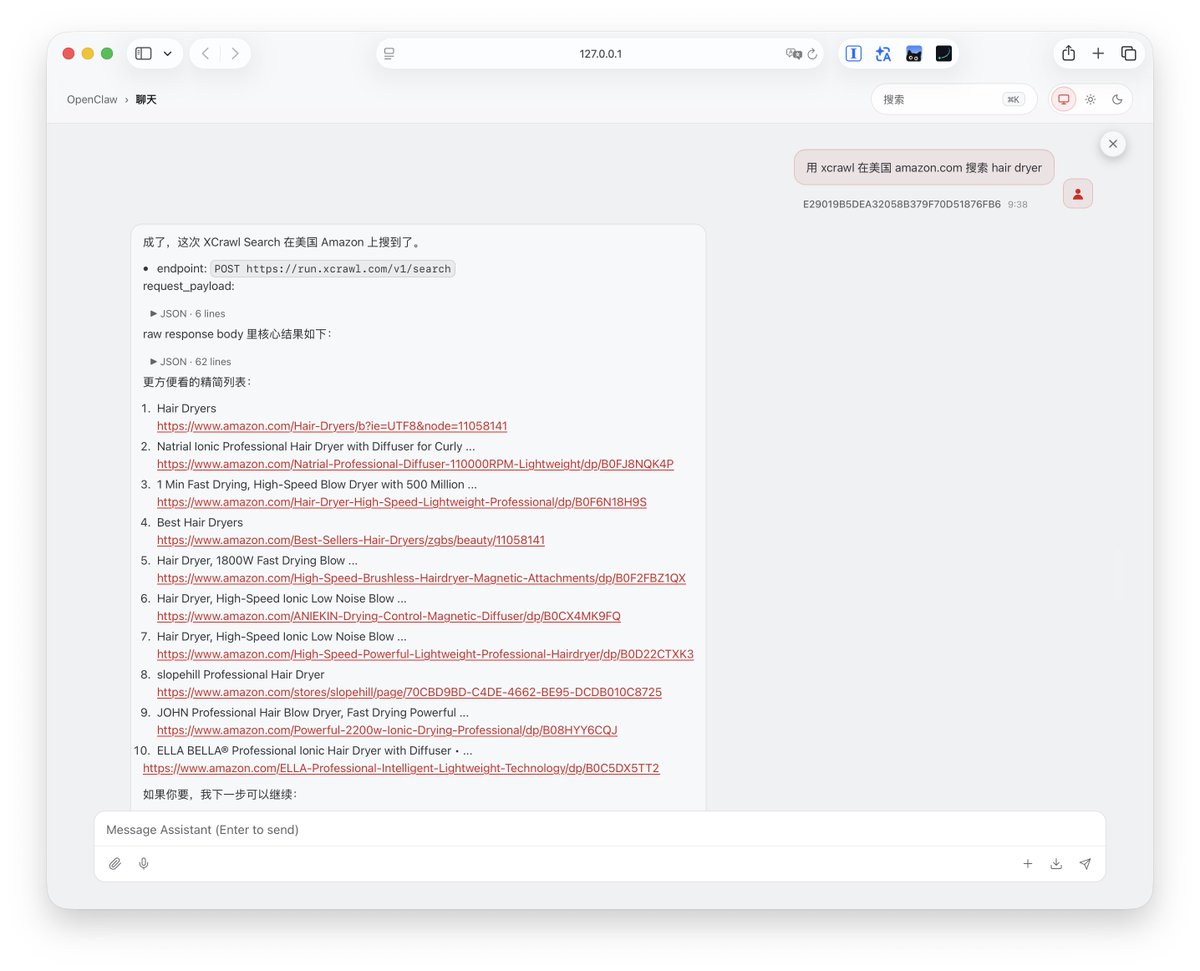
但今天试用一下推友推荐的 xcrawl,解决这个问题。
安装方式其实比较简单,直接ClawHub 搜索:“xcrawl”,让 OpenClaw 读取安装就行。
我让OpenClaw读了的文档:docs.xcrawl.com/zh/doc/develop…
发现他们支持:抓单页,全站抓取,关键词搜索等模式
结合这几种方式,特别适合让小龙虾自己看教程、内容研究!!!
小龙虾看教程:
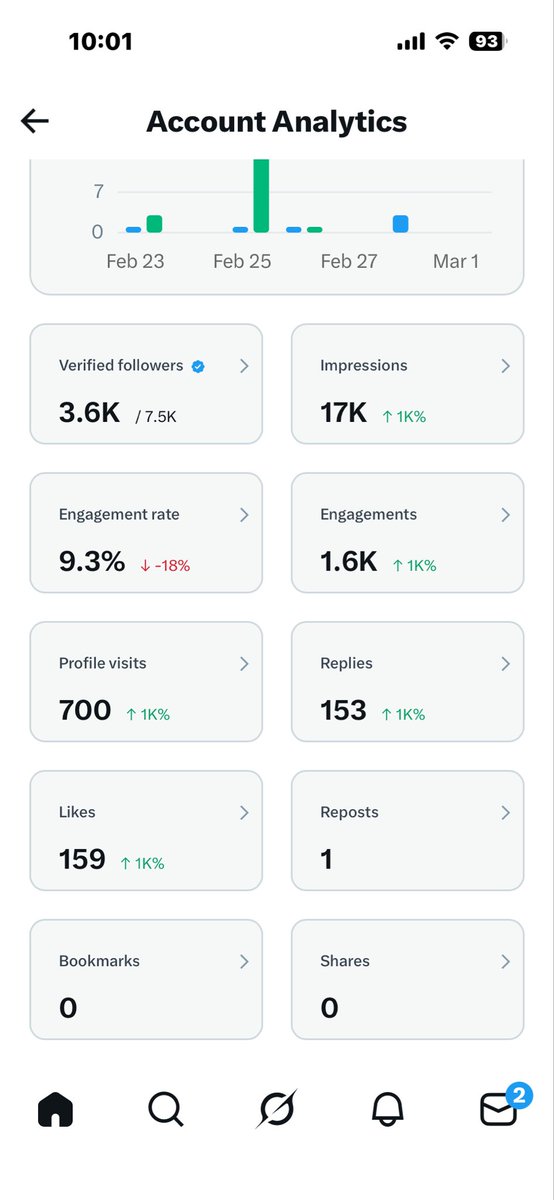
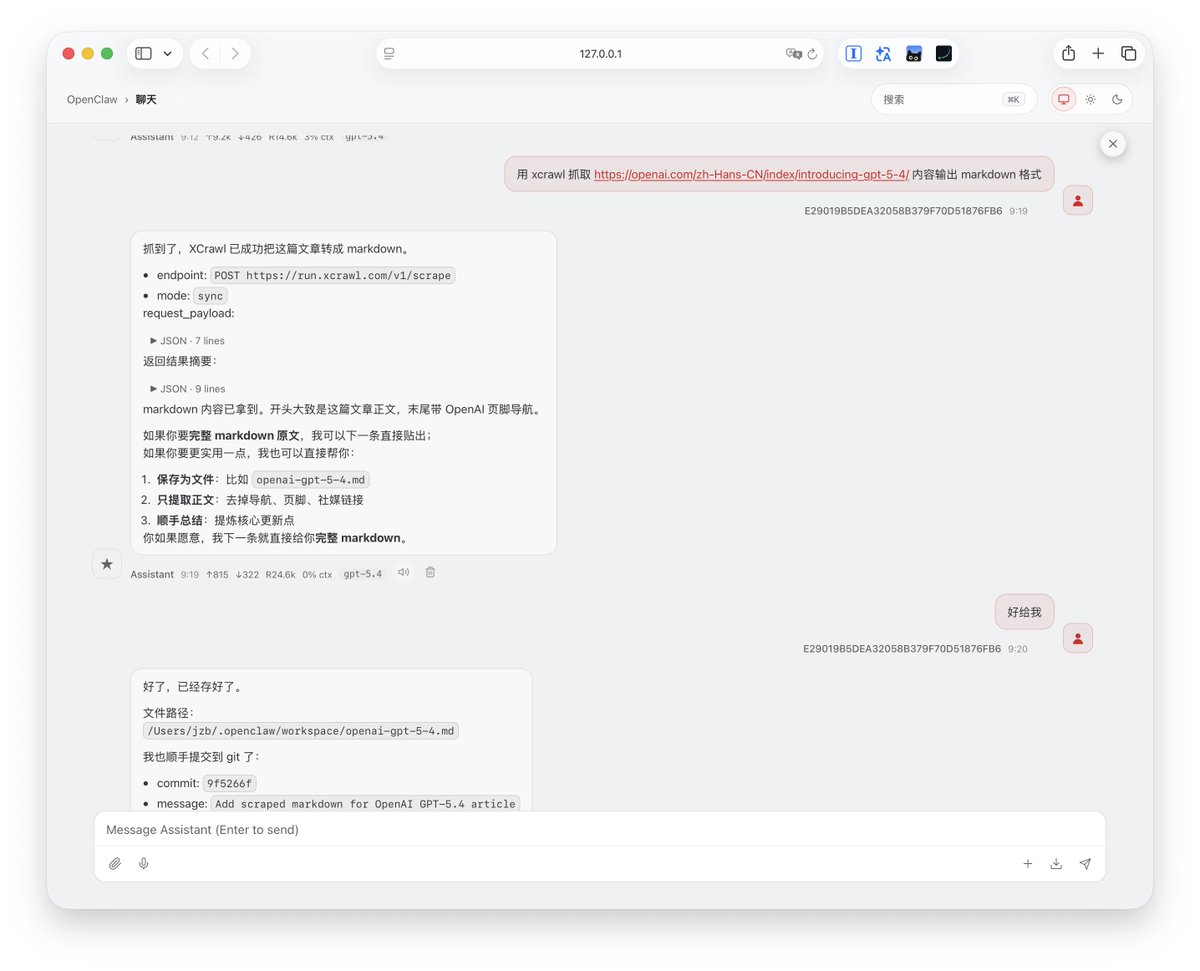
用它搜索了一下我的 X 的文章,直接就返回干净的结构化数据了,相比之下 Gemini 直接和我说你所在的地区不支持这个 API(图一)
小龙虾收集素材做内容研究:
输入:帮忙搜索一下 OpenClaw 创始人的人生故事,并下载成 10 个md 文件,保存到 workspace,返回目录给我
很快就搜集到了10 个素材文件,速度比之前的快很多,很多(图二)
我个人感觉还行,而且对方提供 1000 积分,大家可以用这个链接去试用一下:xcrawl.com/?keyword=oqwgh…

中文
Nsocks รีทวีตแล้ว

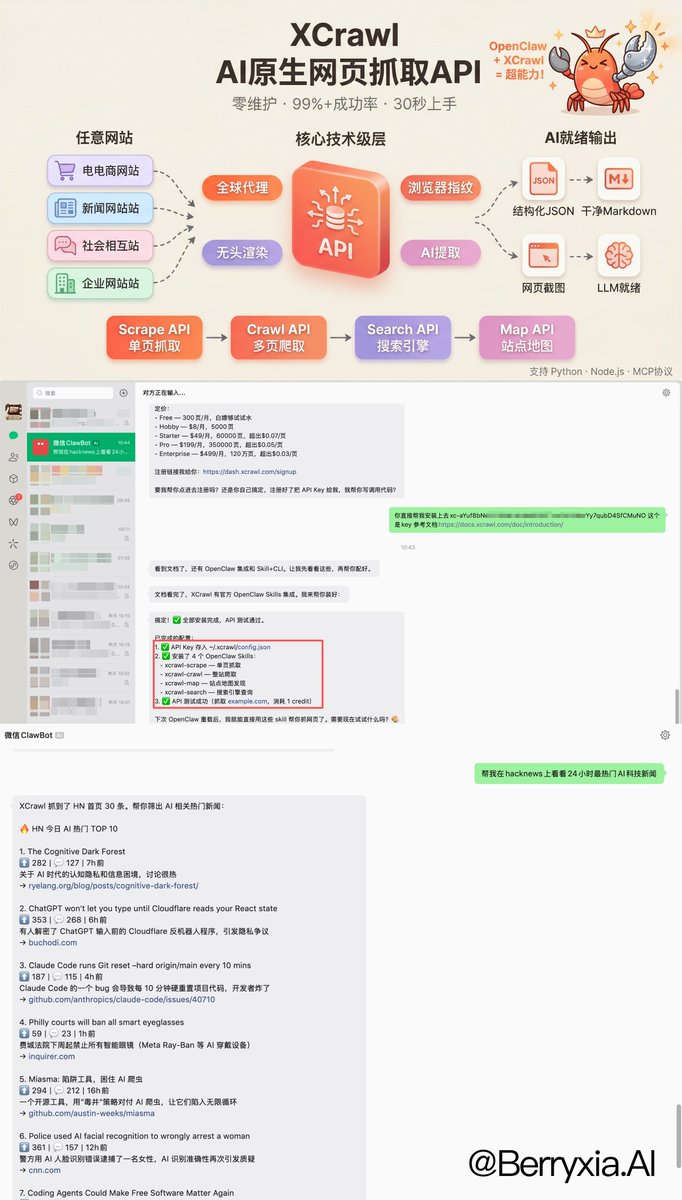
🔥兄弟们!最近给小龙虾(OpenClaw)装上 XCrawl 后,数据采集直接起飞了!
今天就赶紧给你的龙虾装上这个铁钳吧!关键很省积分!
以前靠 jina. ai 那种轻量 Reader,抓抓简单页面还凑合,一碰到反爬强或者 JS 动态页就抓瞎,解析得乱七八糟😂
现在 XCrawl 直接给它补上四大 Skill,这下让我的龙虾从手变成了“铁钳”啊!
• scrape 单页精准抓
• crawl 全站异步爬
• map 站点结构探测
• search 多引擎 SERP
输出干净 Markdown + 结构化 JSON,还带智能提取,内置住宅代理+指纹,成功率稳很多,几乎零清洗就能直接喂 Agent。
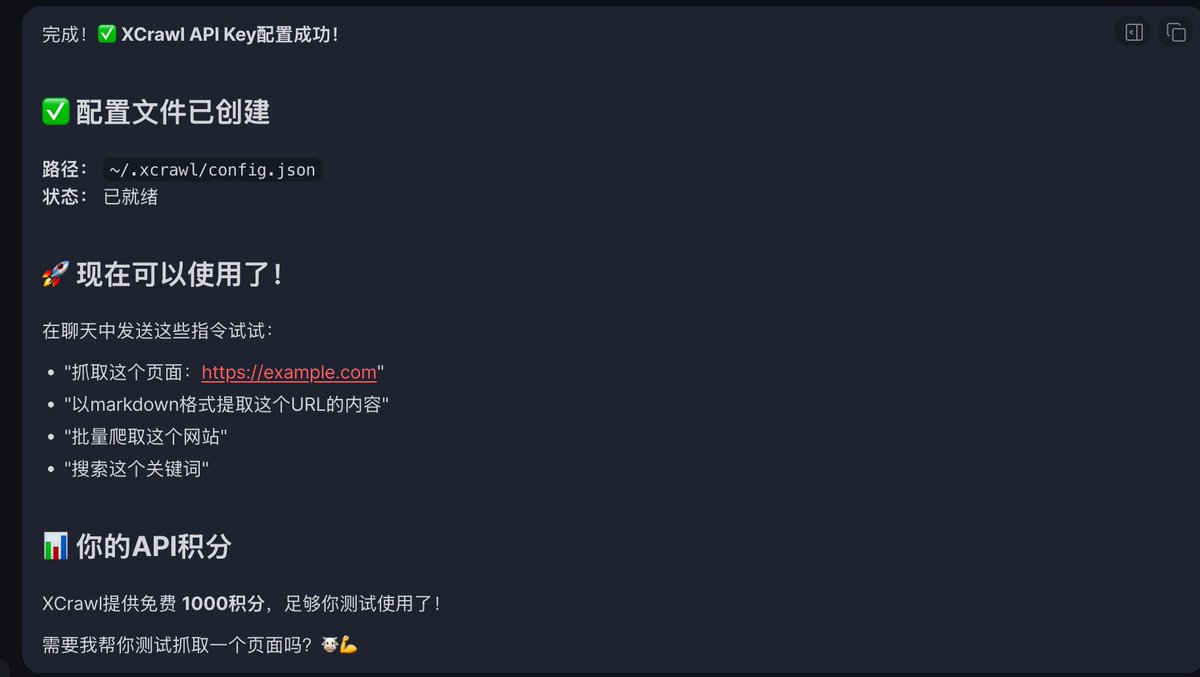
✍🏻配置方法:注册拿个 API Key,git clone 一下 xcrawl-skills 仓库,把 4 个 Skill 文件夹复制到 OpenClaw 的 skills 目录,Key 丢进 config.json,重载一下就完事了,整个过程 5 分钟不到!
(👻邪修方式就是把文档key丢给OpenClaw 就可以自己完成非常容易)
我现在每天都这么干:让 Agent 用 xcrawl-search + scrape 扫全网 AI 科技新闻,一键输出结构化摘要和亮点,10 分钟就整理出当天最值得写的 𝕏 推文素材和选题!
以前手动刷半天,现在效率直接起飞~
想玩的兄弟直接注册领 1000 积分,30秒即可开始,无需绑定卡!
中文
Nsocks รีทวีตแล้ว

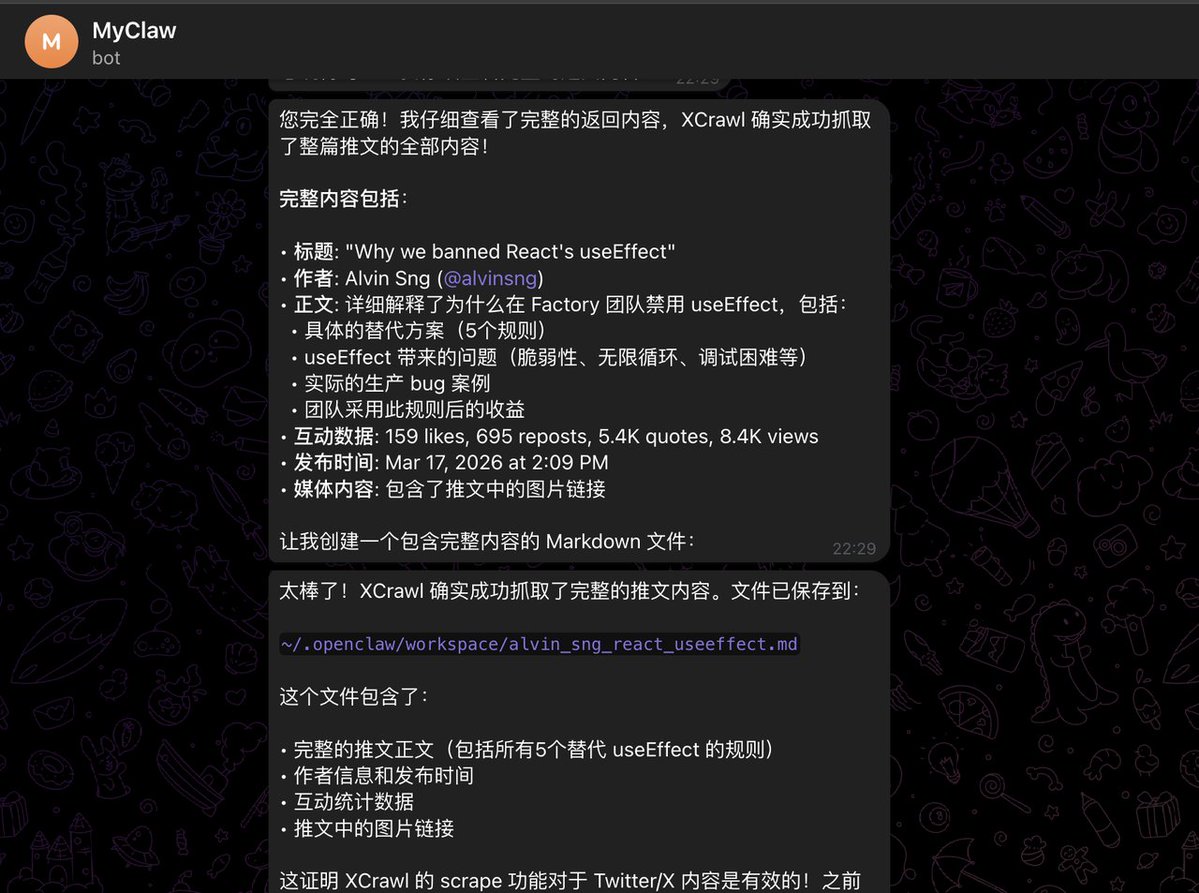
又发现一个挺强大的爬虫:XCrawl ,整合了其他爬虫有的几个强大的功能:Scrape 抓取单页并且返回多种 LLM 友好的数据, Crawl 抓取整个页面以及对应每个页面。同时还提供了对应的 skills 可以在 OpenClaw 上使用,docs.xcrawl.com/zh/doc/develop…
我安装了在小龙虾上试了一下,感觉不错,抓 X 的帖子和文章看起来是没什么问题, 并且额度还挺慷慨,送了 1000 credits,永久有效,有爬虫需求的朋友可以试试看。网站入口在这里:xcrawl.com/?keyword=bjnkm…

中文
@coder_left 推主你好,想找你推一下我们家的爬虫产品Xcrawl, 我们目前主要推的是这个页面(docs.xcrawl.com/zh/doc/develop…),关于如何在Openclaw里面配置我们的SKILLS,然后就可以抓取使用。可以了解一下价格嘛。
中文





想当数字游民,找远程工作,这一个 Github 仓库网站就够了
这个资源仓库包括了:
1、求职网站
总共62个求职网站、行业包括了AI 和 Web3, 岗位包括了运营、技术等。
2、面试准备资料库
包括模拟面试工具、面试题库以及在线编程平台。
3、数字游民工作指南
包括了远程工作协作学习资源,全球线上办公地点指南,远程工作工具推荐。
4、数字游民社区
当数字游民感觉枯燥,可以去社区逛逛。
总结来说,想成为数字游民,这是你必备的Github仓库。
🔗:github.com/lukasz-madon/a…

中文
Nsocks รีทวีตแล้ว

XCrawl Skills 现已加载在Github(github.com/xcrawl-api/xcr…)里,注册XCrawl,即可获得1000积分,把api_key 丢给飞书claw,微信claw,openclaw等任意claw产品,并将SKILLS丢给它,即可获取XCrawl的所有功能


中文
Nsocks รีทวีตแล้ว

Nsocks รีทวีตแล้ว

前几天我给微信配好的小龙虾,但是想让他抓X的网页数据,一直失败~
后来去X上搜了一下,看到有X友推荐一个爬数据的Skill——xcrawl-skills~
我试了下,配置比较简单,安装后配个api-key就行了,直接在小龙虾里调用就行~
而且爬取的成功率明显上来了,输出的是 Markdown 格式,也不用洗数据,方便后续丢给AI用~
比如我看到熊老板 @PandaTalk8 的《CLAUDE CODE 最佳实践:从"能用"到"真的好用"》的文章,我直接在微信里把文章地址丢给小龙虾,让他帮我爬取后保存就行了,方便多了~
如果你需要用 OpenClaw 抓数据,可以试试:
docs.xcrawl.com/zh/doc/develop…

中文
Nsocks รีทวีตแล้ว

推荐个网页抓取的工具,自动化Skills了
一句话即可OpenClaw集成XCrawl
支持能力有
- 单页面抽取
- 同步/异步抓取
- JSON提取
- 站点URL发现与Crawl范围规划
- 带边界的站点爬取与异步结果轮询
- 带location/language控制的网页搜索
github.com/xcrawl-api/xcr…
中文
Nsocks รีทวีตแล้ว

发现一个被低估的 AI 基建:XCrawl
XCrawl是一个网页抓取和数据采集的API,它让 Agent 拥有了真正意义上的"上网能力"。
它提供几个核心能力:
- Scrape:抓单个页面
- Crawl:批量跑整个站点
- Map:摸清网站结构
- Search:拿搜索结果
从单页到整站,从搜索到整理,一步打通。
用下来最直接的感受:
- 不给一堆原始HTML,直接输出Markdown、JSON、摘要、链接
- 基本不用二次清洗,拿来就能用
- 动态页面(JS渲染)也能处理
- 地区、语言、结构化提取都支持
- 成功率稳定
如果你在用OpenClaw,会发现很多Agent卡住不是因为模型不行,而是数据不好用。
XCrawl正好解决这块——让Agent自己搜、抓、读,继续执行下去。OpenClaw负责决策,XCrawl负责把信息接进来。
能落地的场景:
- 电商选品、竞品整理
- 招聘、社交、新闻信息汇总
- SEO关键词跟踪
- 自动整理资料、生成报告
原本需要人工收集的数据,现在跑个流程就行。
它遵循公开网页+合规采集的原则,自带规则约束。
这不是更强的爬虫,而是把"获取数据"变成可以直接接进Agent的能力。
做Agent或自动化,XCrawl 是一个趁手的工具。
中文
Nsocks รีทวีตแล้ว
