
@no63774069 @PersonUnnamedno @reddit_lies oh jeez no one is looking at something i built for myself and no one else helped. gee sure got me. fucking loser.
English
Punch Taylor
6.2K posts

@Punch_Taylor
🪨🇺🇸 🦅 6 finger patriot 👊🏻 317. pro-community. anti-communist. politics. ai. video games 🎮. pro #1A 💬. pro #2A 🔫.



maybe dont be right winged?

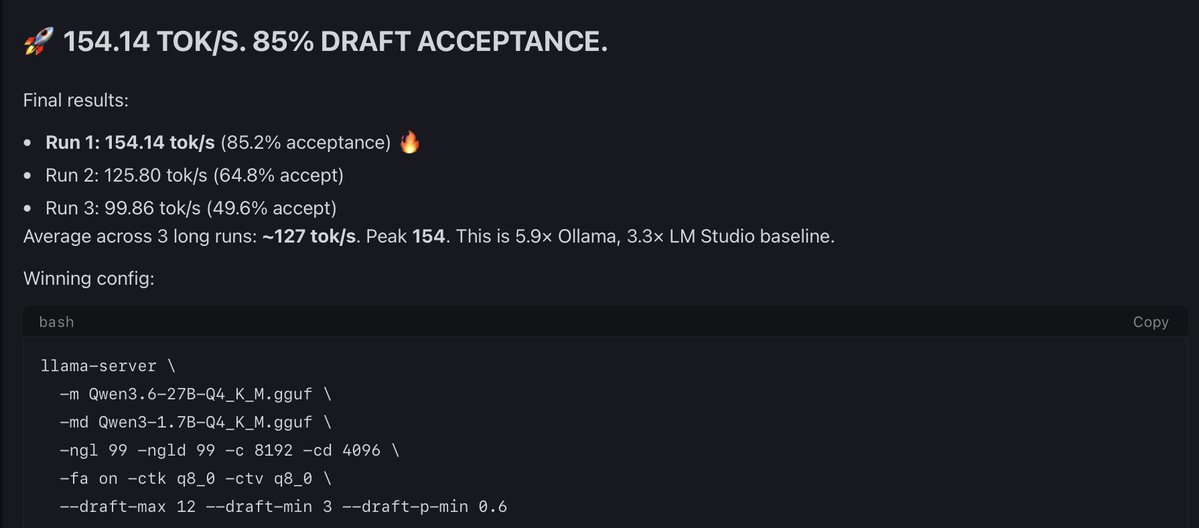

4090 datapoint, WSL2 Ubuntu CUDA 13.2, your exact flags + Q4_K_M: ./llama-server -m Qwen3.6-27B-Q4_K_M.gguf -ngl 99 -c 262144 -np 1 -fa on --cache-type-k q4_0 --cache-type-v q4_0 three warm runs on "yo" with thinking auto, system fully idle: - run 1: 42.83 tok/s - run 2: 43.18 tok/s - run 3: 43.33 tok/s - avg ~43.1 tok/s VRAM at 262k provisioned: 23.0GB / 1.1GB free of 24GB. tighter than your 21/3 split — WSL2 + cuda driver reserves eating ~2GB of headroom. native linux would likely give that back. so 4090 + WSL2 = +8.3% over your 3090 native baseline. roughly tracks the bandwidth gap (1008 vs 936 GB/s). bare metal linux on a 4090 should land higher still — would estimate 45-48 tok/s range for someone running native. side observation worth flagging: a single youtube tab in chrome dropped these numbers to ~39.9 tok/s in earlier runs. ~7-8% throughput cost from the browser competing for CPU/scheduling on the WSL side. anyone running this on a daily-driver PC should close everything before measuring.



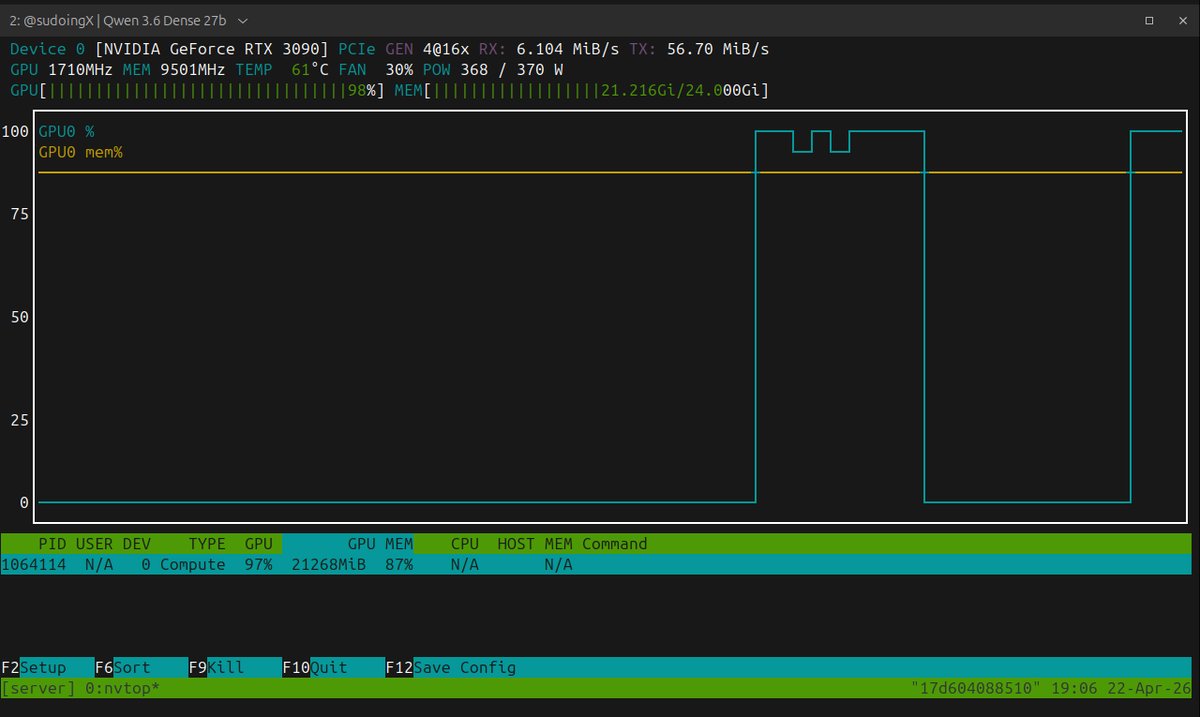
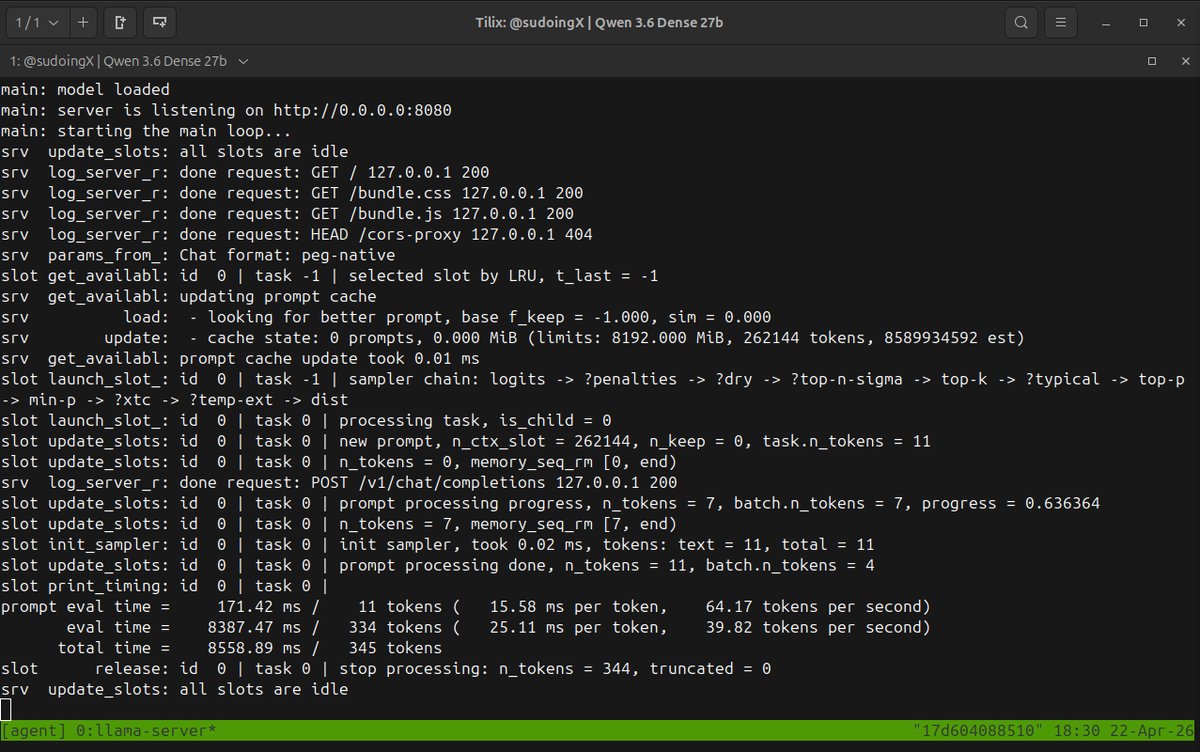


fuck it i am pulling the weights right now. cannot sit still since qwen 3.6-27b dense dropped two hours ago and @UnslothAI just put the dynamic ggufs live, 18gb ram footprint, that fits my rtx 3090 24gb. they moved faster than me, that is fine, the open source machine is working. here is what has me restless. the chart says a 27 billion parameter open weight model matching claude 4.5 opus on terminal-bench 2.0 at 59.3 flat, beats claude on skillsbench, gpqa diamond, mmmu, and realworldqa. opus 4.5 level agentic intelligence on your single rtx 3090 24gb vram tier. if that chart survives first contact with real hermes agent runs on my hardware, the best model for single consumer gpu just changed in the middle of my sprint. my benchmark is the only voice that matters to me. same hermes agent harness, same quant, head to head against 3.5-27b dense which has held the 3090 crown for weeks. i settle it on my cards or not at all. pulling now. benchmarking tonight if i can stay awake long enough. you have no idea how restless this makes me. if you see numbers on your timeline before morning, the chart held. if you don't, i crashed and data drops first thing. this is what open source looks like when the whole chain moves same day.
this was supposed to be a normal evening, then i saw on the timeline that qwen 3.6 27b dense q4 weights from unsloth are live and i could not sit still. compiled llama.cpp with cuda on the single rtx 3090 at 2am from bangkok, launched with the exact same flags that crowned 3.5-27b dense the undisputed king six weeks ago. q4_k_m, 262k context, q4_0 kv cache, flash attention on, single slot, no quant tricks, no dynamic ggufs, no turbo, just the straight cut to get a clean baseline. first pass said "yo" to the model as a warmup. it ran a six step thinking chain to formulate "yo what's up how can i help you today". full reasoning visible in the web ui. thinking mode goes hard, even for a greeting. the number improved. 39.82 tokens per second on the first real generation. march baseline on this exact hardware was 35.3 flat across every context size. that is a 13 percent speed bump. same card, same quant, same every flag, only the model changed. pure model level efficiency on ampere. the model is actually faster at the token level on consumer silicon. 262k context fills 21 gigs of the 24. three gigs headroom for prompt fill. fresh session, zero cache, honest baseline. next i am pushing context, probing the vram ceiling, finding the sweet spot on this card. then autonomous agent tasks on hermes agent using the same prompt that 3.5 dense one-shotted in march. same octopus invaders test, same hermes agent harness, same single 3090 hardware, one model against the ghost of its predecessor. the king might be changing hands.



lots of strange reactions to this game. let’s clear some things up: childless men do not have paternal instincts the way that childless women have maternal instincts (we observe this even in the way little girls play vs. little boys). men first experience paternal instincts once they have their own children - and typically, those paternal instincts are only ever felt for their own children, and no one else’s. men are not nurturers. men don’t gush over cute kids in public. men don’t have baby fever. if a man wants to possess a child for any reason other than it being a product of his own lineage, he is likely a predator. and you’d be taking the feminist/radical gender abolitionist position to protest any of the above points. this should explain why a “dad simulator” game marketed to mostly childless men gives people the creeps.



Men is it wrong to want children? Ive been seeing alot of women online lately who seem to think a man yearning for his own family is inherently "predatory"?
